
如何利用python实现词频统计功能
目录
- 功能要求
- 方法如下
- 运行结果
- 总结
功能要求
这是我们老师的作业 代码中都有注释 要求 词频统计软件:
1)从文本中读入数据:(文件的输入输出)
2)不区分大小写,去除特殊字符。
3) 统计单词 例如:about :10 并统计总共多少单词
4)对单词排序。出现次数
5)输出词频最高的10个单词和次数
6)把统计结果存入文本
方法如下
1.文件的读取,区分大小写,去除特殊字符
import re
def getword():
# 读取文件
f=open('read.txt','r',encoding='utf-8')
# 将大写转化成小写
word=f.read().lower()
# 关闭文件
f.close()
#利用正则除去特殊字符 |\符+
list=re.split('\s+|\,+|\.+|\!+|\:+|\?+|\;+|\(+|\)+|\-+|\_+|\=+|\++|\“+|\、+|\/+|\{+|\}+|\”+|\:+|\。+|\“+|\[+|\]+|\【+|\】+|\—+|\%+|\"+',word)
# 遍历列表 去除列表中的空格
i = 0
while i < len(list):
if list[i] == '':
list.remove(list[i])
i -= 1
i += 1
# for a in list:
# if a == "":
# list.remove(a)
#用for循环的话如果存在多个空字符串 其列表会随时发生变化,导致无法正常删除空字符串 所以在使用for…in循环遍历列表时,最好不要对元素进行增删操作
# 对于others'优化 如果最后一个字符是‘就将'其去掉
for i in range(len(list)):
l=list[i]
if list[i][-1] == "'":
list[i] = list[i][:-1]
return list
2. 统计,排序
from getfilewords import getword
def statistics():
dict={} #定义一个空的字典,在后面的运算中逐步添加数据
words=getword()
for word in words: #遍历整个列表
if word in dict.keys(): #判断当前单词是否已经存在 dict.keys()是已存进字典中的单词
# 补充:keys() 方法用于返回字典中的所有键;
# values() 方法用于返回字典中所有键对应的值;
#详情见Test1
dict[word]=dict[word]+1 #在当前单词的个数上加 1
else:
dict[word]=1 #当前单词第一次出现时 会把单词写入dict字典里 格式为 ‘单词'=1
#排序
w_order=sorted(dict.items(),key=lambda x:x[1],reverse=True)
# print(dict.items())
# dict.items()返回的是列表
# 按字典集合中,每一个元组的第二个元素排列。
# sorted会对dict.items()这个list进行遍历,把list中的每一个元素,也就是每一个tuple()当做x传入匿名函数lambda x:x[1],函数返回值为x[1]
# reverse属性True为降序 False为升序
return w_order #返回排序后的列表
3.结果写入文本
from WordStatistics import statistics
def writefile():
w_order=statistics()
f = open('result.txt', 'w',encoding='utf-8')
print("文章单词总个数:",+len(getword()),file=f)
print("文章单词总个数:", +len(getword()))
# 写入文件
print("词频最高的10个单词和次数",file=f)
print("词频最高的10个单词和次数")
w_order10=w_order[:10]#将列表的前十位提取并且遍历 输出key(单词)和values(次数)
for key,values in w_order10:
print(key,':',values,file=f)
print(key, ':', values)
#遍历列表中的所有数据
print("统计结果",file=f)
for key,values in w_order:
print(key,':',values,file=f)
f.close()#关闭文件
4.程序入口
import os
from writefile import writefile
print("词频统计软件")
print("正在统计中。。。")
print("统计成功,结果保存到result.txt")
writefile()
print("程序运行结束")
os.system("pause")
5.运行截图 这是需要统计的文本

运行程序
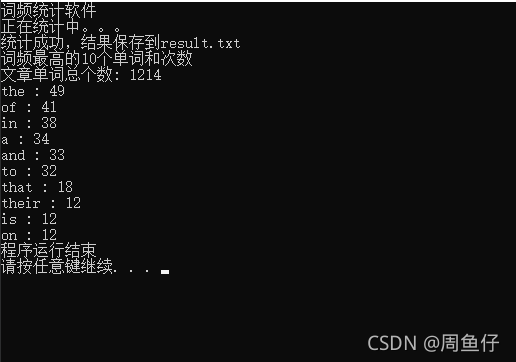
运行结果

总结
到此这篇关于如何利用python实现词频统计功能的文章就介绍到这了,更多相关python实现词频统计内容请搜索hwidc以前的文章或继续浏览下面的相关文章希望大家以后多多支持hwidc!
【转自:荷兰服务器 】