
Python爬虫小练习之爬取并分析腾讯视频m3u8格式
目录
- 普通爬虫正常流程:
- 环境介绍
- 分析网站
- 开始代码
- 导入模块
- 数据请求
- 提取数据
- 遍历
- 保存数据
- 运行代码
普通爬虫正常流程:
- 数据来源分析
- 发送请求
- 获取数据
- 解析数据
- 保存数据
环境介绍
- python 3.8
- pycharm 2021专业版
【付费VIP完整版】只要看了就能学会的教程,80集Python基础入门视频教学
点这里即可免费在线观看
分析网站
先打开开发者工具,然后搜索m3u8,会返回给你很多的ts的文件,像这种ts文件,就是视频的片段
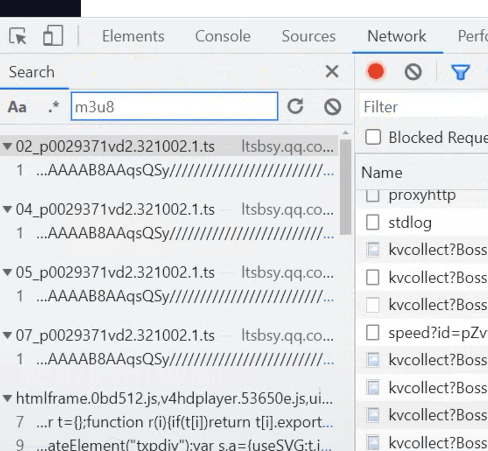
我们可以复制url地址,在新的浏览页打开
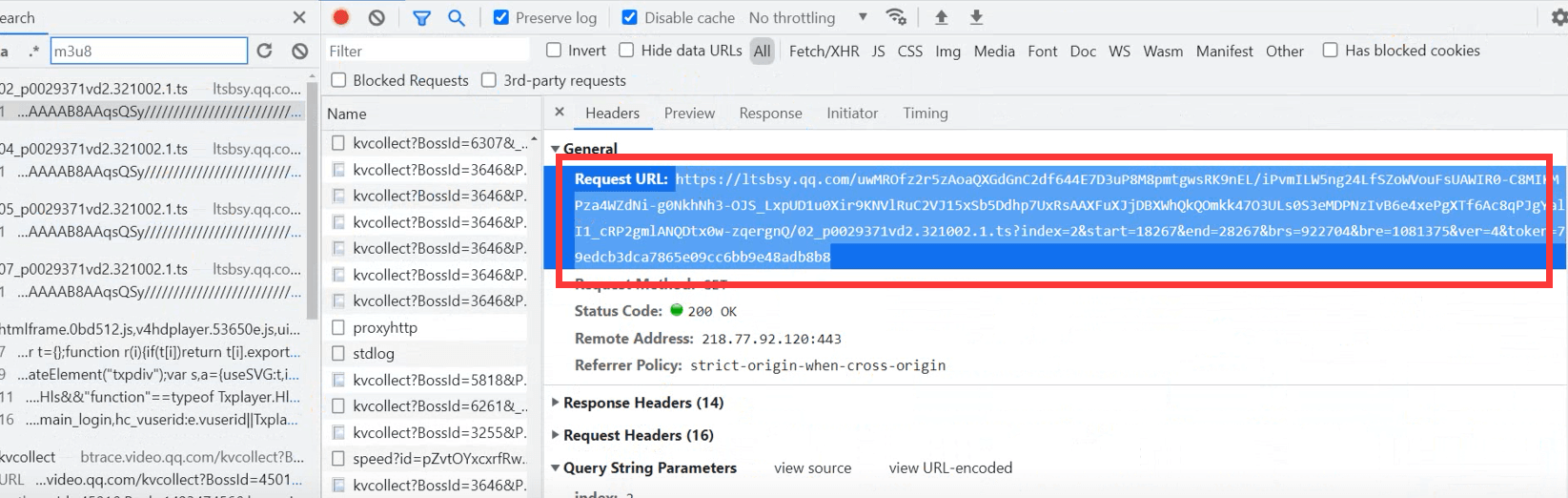
然后会给我们下载ts的文件,打开文件,就会发现是十多秒的视频片段


所以说这些数据的数据还是比较好找的,只要我们找到地址是从哪里来的
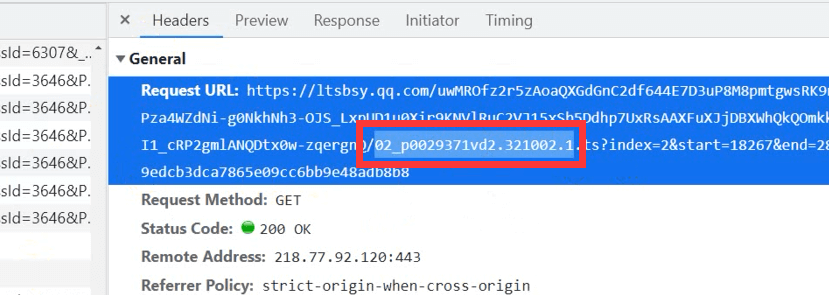
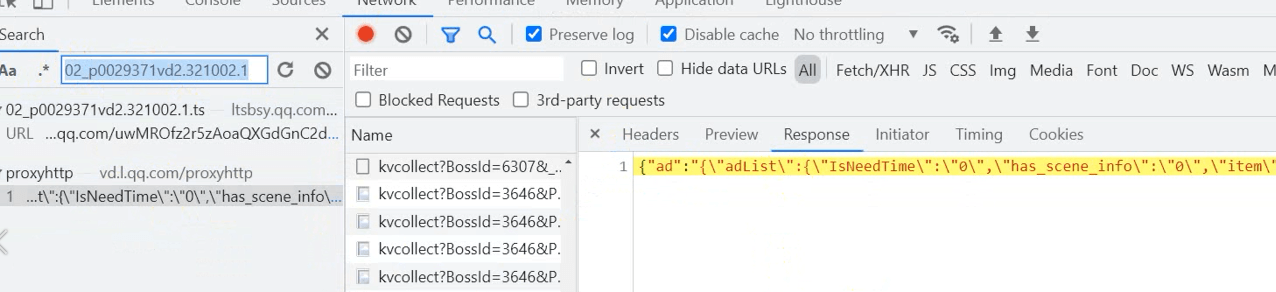
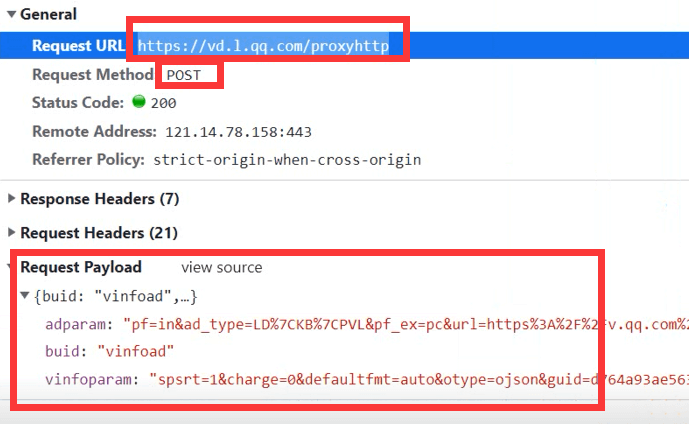
找到url地址,因为是post请求,所以需要下面的表达参数
开始代码
导入模块
import requests import re from tqdm import tqdm # 进度条展示
数据请求
url = 'https://vd.l.qq.com/proxyhttp'
data = {"buid":"vinfoad","adparam":"pf=in&ad_type=LD%7CKB%7CPVL&pf_ex=pc&url=https%3A%2F%2Fv.qq.com%2Fx%2Fcover%2Fj3czmhisqin799r.html&refer=https%3A%2F%2Fv.qq.com%2Fx%2Fsearch%2F&ty=web&plugin=1.0.0&v=3.5.57&coverid=j3czmhisqin799r&vid=z002615k57t&pt=&flowid=e9b3e49b2593efd194cbcd24030ed803_10201&vptag=www_baidu_com%7Cvideo%3Aposter_tle&pu=-1&chid=0&adaptor=2&dtype=1&live=0&resp_type=json&guid=4b4e192e83f4abaf8b68df3e4f5be769&req_type=1&from=0&appversion=1.0.166&uid=522810848&tkn=fbYfeWDCLKtAaOd_OGvCNg..<=qq&platform=10201&opid=5FE180427A4C883F69CADDED665CE99B&atkn=49C1A486316C8D269AC65AAC080CFB29&appid=101483052&tpid=1&rfid=86c3f668da63d8bc7aab3fbc1eb7378a_1633763084","vinfoparam":"spsrt=1&charge=0&defaultfmt=auto&otype=ojson&guid=4b4e192e83f4abaf8b68df3e4f5be769&flowid=e9b3e49b2593efd194cbcd24030ed803_10201&platform=10201&sdtfrom=v1010&defnpayver=1&appVer=3.5.57&host=v.qq.com&ehost=https%3A%2F%2Fv.qq.com%2Fx%2Fcover%2Fj3czmhisqin799r.html&refer=v.qq.com&sphttps=1&tm=1633767536&spwm=4&logintoken=%7B%22main_login%22%3A%22qq%22%2C%22openid%22%3A%225FE180427A4C883F69CADDED665CE99B%22%2C%22appid%22%3A%22101483052%22%2C%22access_token%22%3A%2249C1A486316C8D269AC65AAC080CFB29%22%2C%22vuserid%22%3A%22522810848%22%2C%22vusession%22%3A%22fbYfeWDCLKtAaOd_OGvCNg..%22%7D&vid=z002615k57t&defn=fhd&fhdswitch=0&show1080p=1&isHLS=1&dtype=3&sphls=2&spgzip=1&dlver=2&drm=32&hdcp=0&spau=1&spaudio=15&defsrc=2&encryptVer=9.1&cKey=W5agxKnJ7N56KJEItZs_lpJX5WB4a2CdS8kEIo8rVaqtHEZQ1c_W6myJ8hQXnmDDG8ErEJDMLjvm2vPBr-xE-uhvZyEMY131vUh1H4pgCXe2OphM_H32Jqtu2hFoqfA-un0sVBkIXYfWkOdABnbLUo4RgzSXkBHF3N3K7dNKPg_56X9JO3gwBMyBeAex05x8SbbQKY5AXaDVSM7hsBQ8XEeHzIEGJzlCt94ONgPYVSRkZqo51NVr_Bs8h4-UNLT0jG-obbyNs2IJhrZ4JUBeuGEk8zAOhE9HTZPNDViLRIyt2mNDud09qSLLKl4XAj3CE6i26P6BRyAy1_qatijXkm9J1hs3ZYC7dgYmAZD6BE9UGX4hkziTy-Y8cCBppeEBGSaj9w&fp2p=1&spadseg=3"}
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36'
}
response = requests.post(url=url, json=data, headers=headers)
提取数据
html_data = response.json()['vinfo']
# 正则表达式
m3u8_url = re.findall("url(.*?),", html_data)[3].split('"')[2]
m3u8_data = requests.get(url=m3u8_url).text
m3u8_data = re.sub('#EXTM3U', '', m3u8_data)
m3u8_data = re.sub('#EXT-X-VERSION:\d', '', m3u8_data)
m3u8_data = re.sub('#EXT-X-MEDIA-SEQUENCE:\d', '', m3u8_data)
m3u8_data = re.sub('#EXT-X-TARGETDURATION:\d+', '', m3u8_data)
m3u8_data = re.sub('#EXT-X-PLAYLIST-TYPE:VOD', '', m3u8_data)
m3u8_data = re.sub('#EXTINF:\d+\.\d+,', '', m3u8_data)
m3u8_data = re.sub('#EXT-X-ENDLIST', '', m3u8_data).split()
遍历
for ts in tqdm(m3u8_data):
ts_url = 'https://apd-57c5d150c8b9788baf40ea4f65feddf8.v.smtcdns.com/moviets.tc.qq.com/A2k4JuW9ATia8thdFQ6y5HWRUGLqAr4L5fk9KFbAUEI8/uwMROfz2r5xgoaQXGdGnC2df64gVTKzl5C_X6A3JOVT0QIb-/doVi4hWq0sqexPo_ylKYxVIJdr9zz2VweWbcY7x70kRnbVNPvBaoTsjwfOq1uojOtsRKJ8r3372HRaTOVg4VyKOFFvzjq2EeMdpleIIyTv0tb-C3CzXmkZz-34hK4Fc-r4mZK55L9W1RqJMpsvrORZr_sqpqvGZrrRq830get0NLJGkeAQ9SBg/' + ts
ts_content = requests.get(url=ts_url).content
保存数据
with open('霸王别姬.mp4', mode='ab') as f:
f.write(ts_content)
print('下载完成')
运行代码
到此这篇关于Python爬虫小练习之爬取并分析腾讯视频m3u8格式的文章就介绍到这了,更多相关Python爬取腾讯视频内容请搜索hwidc以前的文章或继续浏览下面的相关文章希望大家以后多多支持hwidc!
【文章出处:美国多ip服务器】