
pyTorch深入学习梯度和Linear Regression实现
目录
- 梯度
- 线性回归(linear regression)
- 模拟数据集
- 加载数据集
- 定义loss_function
梯度
PyTorch的数据结构是tensor,它有个属性叫做requires_grad,设置为True以后,就开始track在其上的所有操作,前向计算完成后,可以通过backward来进行梯度回传。
评估模型的时候我们并不需要梯度回传,使用with torch.no_grad() 将不需要梯度的代码段包裹起来。每个Tensor都有一个.grad_fn属性,该属性即创建该Tensor的Function,直接用构造的tensor返回None,否则是生成该tensor的操作。
tensor(data, *, dtype=None, device=None, requires_grad=False, pin_memory=False) -> Tensor #require_grad默认是false,下面我们将显式的开启 x = torch.tensor([1,2,3],requires_grad=True,dtype=torch.float)
注意只有数据类型是浮点型和complex类型才能require梯度,所以这里显示指定dtype为torch.float32
x = torch.tensor([1,2,3],requires_grad=True,dtype=torch.float32) > tensor([1.,2.,3.],grad_fn=None) y = x + 2 > tensor([3.,4.,5.],grad_fn=<AddBackward0>) z = y * y * 3 > tensor([3.,4.,5.],grad_fn=<MulBackward0>)
像x这种直接创建的,没有grad_fn,被称为叶子结点。grad_fn记录了一个个基本操作用来进行梯度计算的。
关于梯度回传计算看下面一个例子
x = torch.ones((2,2),requires_grad=True) > tensor([[1.,1.], > [1.,1.]],requires_grad=True) y = x + 2 z = y * y * 3 out = z.mean() #out是一个标量,无需指定求偏导的变量 out.backward() x.grad > tensor([[4.500,4.500], > [4.500,4.500]]) #每次计算梯度前,需要将梯度清零,否则会累加 x.grad.data.zero_()
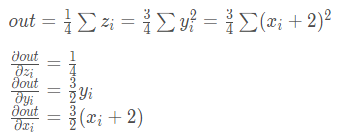
值得注意的是只有叶子节点的梯度在回传时才会被计算,也就是说,上面的例子中拿不到y和z的grad。
来看一个中断求导的例子
x = torch.tensor(1.,requires_grad=True) y1 = x ** 2 with torch.no_grad() y2 = x ** 3 y3 = y1 + y2 y3.backward() print(x.grad) > 2
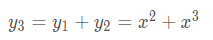
本来梯度应该为5的,但是由于y2被with torch.no_grad()包裹,在梯度计算的时候不会被追踪。
如果我们想要修改某个tensor的数值但是又不想被autograd记录,那么需要使用对x.data进行操作就行这也是一个张量。
线性回归(linear regression)
利用线性回归来预测一栋房屋的价格,价格取决于很多feature,这里简化问题,假设价格只取决于两个因素,面积(平方米)和房龄(年)
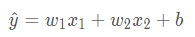
x1代表面积,x2代表房龄,售出价格为y
模拟数据集
假设我们的样本数量为1000个,每个数据包括两个features,则数据为1000 * 2的2-d张量,用正太分布来随机取值。
labels是房屋的价格,长度为1000的一维张量。
真实w和b提前把值定好,然后再取一个干扰量 δ \delta δ(也用高斯分布取值,用来模拟真实数据集中的偏差)
num_features = 2#两个特征 num_examples = 1000 #样本个数 w = torch.normal(0,1,(num_features,1)) b = torch.tensor(4.2) samples = torch.normal(0,1,(num_examples,num_features)) labels = samples.matmul(w) + b noise = torch.normal(0,.01,labels.shape) labels += noise
加载数据集
import random def data_iter(samples,labels,batch_size): num_samples = samples.shape[0] #获得batch轴的长度 indices = [i for i in range(num_samples)] random.shuffle(indices)#将索引数组原地打乱 for i in range(0,num_samples,batch_size): j = torch.LongTensor(indices[i:min(i+batch_size,num_samples)]) yield samples.index_select(0,j),labels(0,j)
torch.index_select(dim,index)
dim表示tensor的轴,index是一个tensor,里面包含的是索引。
定义loss_function
def loss_function(predict,labels): loss = (predict,labels)** 2 / 2 return loss.mean()
定义优化器
def loss_function(predict,labels): loss = (predict,labels)** 2 / 2 return loss.mean()
开始训练
w = torch.normal(0.,1.,(num_features,1),requires_grad=True) b = torch.zero(0.,dtype=torch.float32,requires_grad=True) batch_size = 100 for epoch in range(10): for data, label in data_iter(samples,labels,batch_size): predict = data.matmul(w) + b loss = loss_function(predict,label) loss.backward() optimizer([w,b],0.05) w.grad.data.zero_() b.grad.data.zero_()
以上就是pyTorch深入学习梯度和Linear Regression实现的详细内容,更多关于pyTorch实现梯度和Linear Regression的资料请关注hwidc其它相关文章!
【来源:自由互联:http://www.yidunidc.com/usa.html 欢迎留下您的宝贵建议】