
C语言数据结构之vector底层实现机制解析
目录
- 一、vector底层实现机制刨析
- 二、vector的核心框架接口的模拟实现
- 1.vector的迭代器实现
- 2.reserve()扩容
- 3.尾插尾删(push_back(),pop_back())
- 4.对insert()插入时迭代器失效刨析
- 5.对erase()数据删除时迭代器失效刨析
一、vector底层实现机制刨析
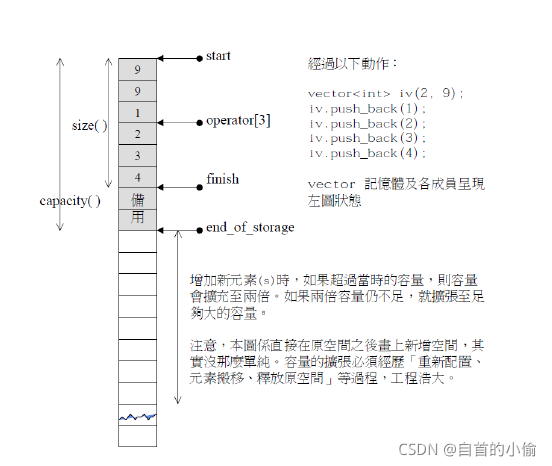
通过分析 vector 容器的源代码不难发现,它就是使用 3 个迭代器(可以理解成指针)来表示的:
其中statrt指向vector 容器对象的起始字节位置;
finish指向当前最后一个元素的末尾字节
end_of指向整个 vector 容器所占用内存空间的末尾字节。
如图 演示了以上这 3 个迭代器分别指向的位置
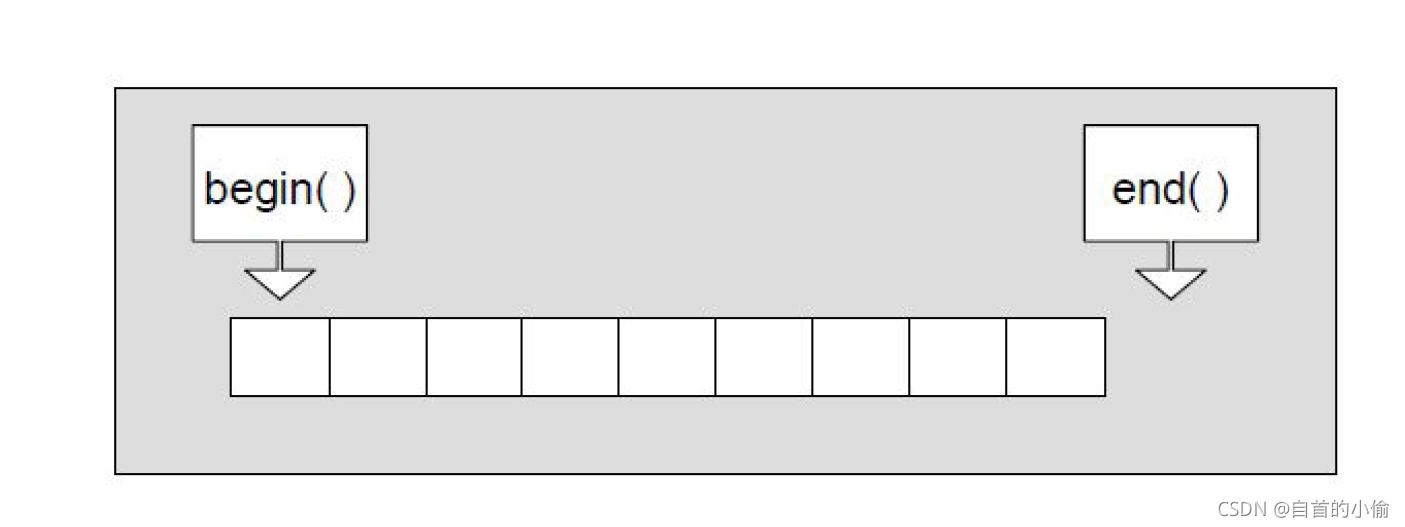
如图 演示了以上这 2个迭代器分别指向的位置
在此基础上,将 3 个迭代器两两结合,还可以表达不同的含义,例如:
start 和 finish 可以用来表示 vector 容器中目前已被使用的内存空间;
finish 和 end_of可以用来表示 vector 容器目前空闲的内存空间;
start和 end_of可以用表示 vector 容器的容量。
二、vector的核心框架接口的模拟实现
1.vector的迭代器实现
typedef T* Iteratot;
typedef T* const_Iteratot;
Iteratot cend()const {
return final_end;
}
Iteratot cbegin()const {
return start;
}
Iteratot end() {
return final_end;
}
Iteratot begin() {
return start;
}
vector的迭代器是一个原生指针,他的迭代器和String相同都是操作指针来遍历数据:
- begin()返回的是vector 容器对象的起始字节位置;
- end()返回的是当前最后一个元素的末尾字节;
2.reserve()扩容
void reserve(size_t n) {
if (n > capacity()) {
T* temp = new T [n];
//把statrt中的数据拷贝到temp中
size_t size1 = size();
memcpy(temp, start, sizeof(T*) * size());
start = temp;
final_end = start + size1;
finally = start + n;
}
}
当 vector 的大小和容量相等(size==capacity)也就是满载时,如果再向其添加元素,那么 vector 就需要扩容。vector 容器扩容的过程需要经历以下 3 步:
- 完全弃用现有的内存空间,重新申请更大的内存空间;
- 将旧内存空间中的数据,按原有顺序移动到新的内存空间中;
- 最后将旧的内存空间释放。
这也就解释了,为什么 vector 容器在进行扩容后,与其相关的指针、引用以及迭代器可能会失效的原因。
由此可见,vector 扩容是非常耗时的。为了降低再次分配内存空间时的成本,每次扩容时 vector 都会申请比用户需求量更多的内存空间(这也就是 vector 容量的由来,即 capacity>=size),以便后期使用。
vector 容器扩容时,不同的编译器申请更多内存空间的量是不同的。以 VS 为例,它会扩容现有容器容量的 50%。
使用memcpy拷贝问题
reserve扩容就是开辟新空间用memcpy将老空间的数据拷贝到新开空间中。
假设模拟实现的vector中的reserve接口中,使用memcpy进行的拷贝,以下代码会发生什么问题?
int main()
{
bite::vector<bite::string> v;
v.push_back("1111");
v.push_back("2222");
v.push_back("3333");
return 0;
}
问题分析:
- memcpy是内存的二进制格式拷贝,将一段内存空间中内容原封不动的拷贝到另外一段内存空间中
- 如果拷贝的是自定义类型的元素,memcpy即高效又不会出错,但如果拷贝的是自定义类型元素,并且自定义类型元素中涉及到资源管理时,就会出错,因为memcpy的拷贝实际是浅拷贝。
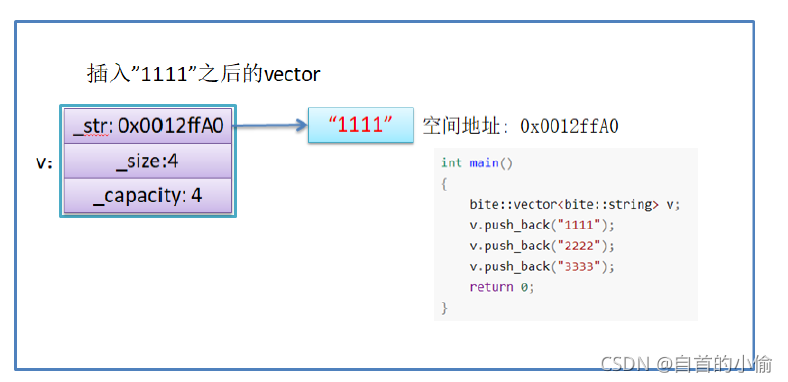
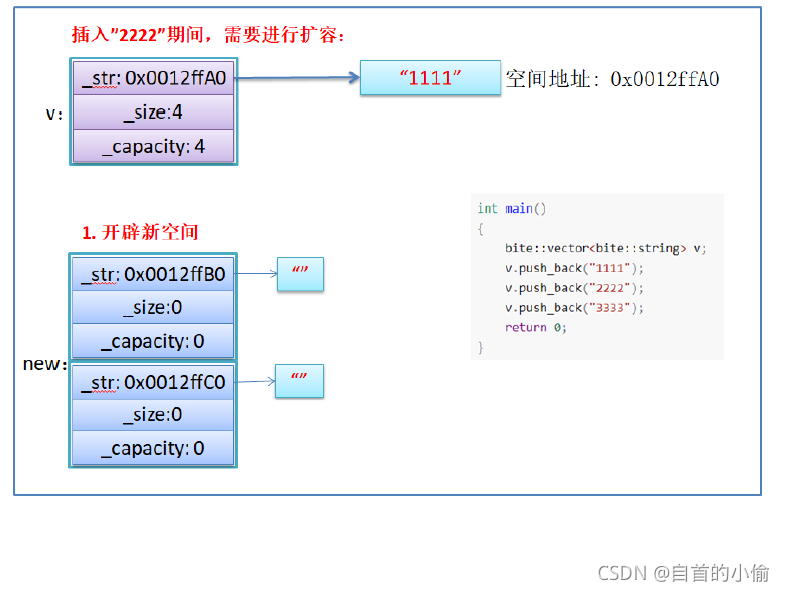
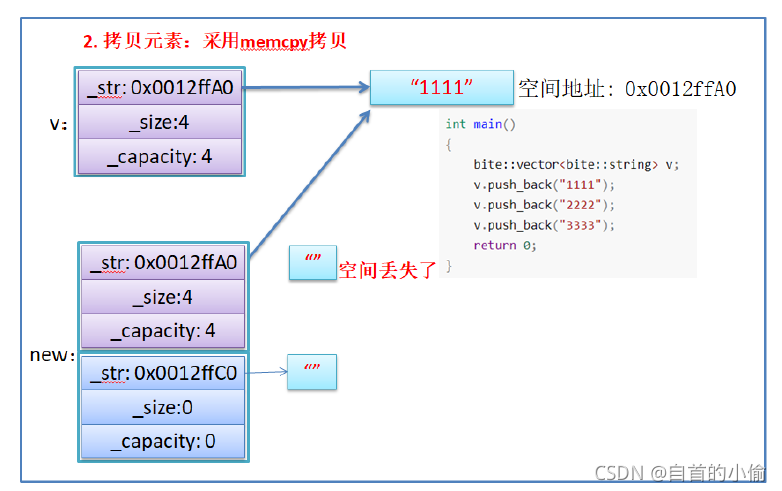
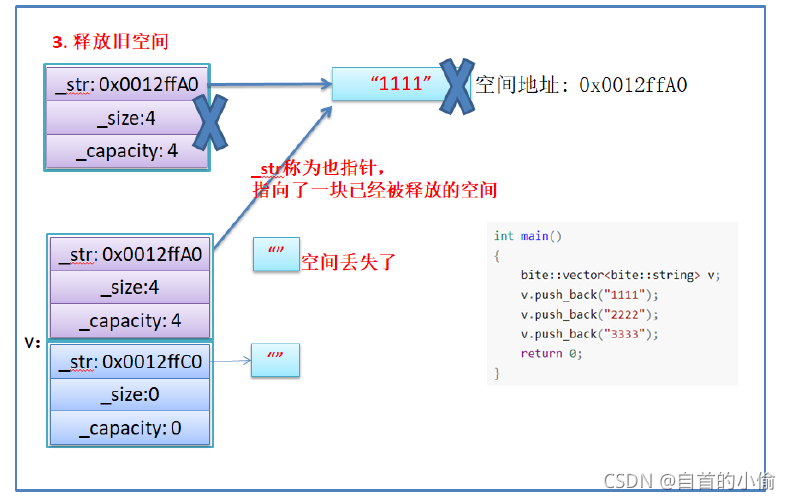
结论:如果对象中涉及到资源管理时,千万不能使用memcpy进行对象之间的拷贝,因为memcpy是浅拷贝,否则可能会引起内存泄漏甚至程序崩溃。
3.尾插尾删(push_back(),pop_back())
void push_back(const T&var) {
if (final_end ==finally) {
size_t newcode = capacity() == 0 ? 4 : capacity() * 2;
reserve(newcode);
}
*final_end = var;
++final_end;
void pop_back() {
final_end--;
}
插入问题一般先要判断空间是否含有闲置空间,如果没有,就要开辟空间。我们final_end==finally来判断是否含有闲置空间。如果容器含没有空间先开辟4字节空间,当满了后开2capacoity()空间。在final_end部插入数据就行了。对final_end加以操作。
4.对insert()插入时迭代器失效刨析
Iteratot insert(Iteratot iterator,const T&var) {
assert(iterator <= final_end && iterator >= start);
size_t pos = iterator - start;
if (final_end == finally) {
size_t newcode = capacity() == 0 ? 4 : capacity() * 2;
reserve(newcode);
}
//插入操作
auto it = final_end;
while (it >= start+pos) {
*(it+1)=*it;
it--;
}
*iterator = var;
final_end++;
return iterator;
}
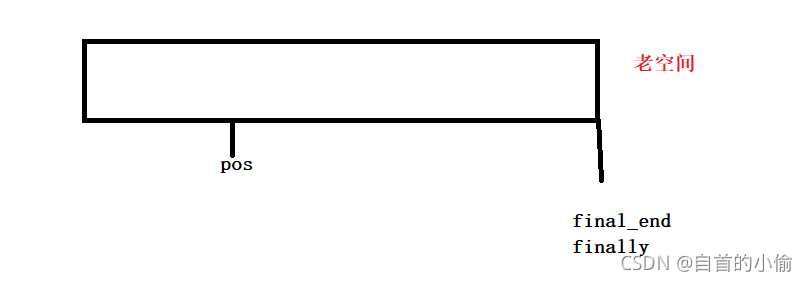
假设这是一段vector空间要在pos插入数据,但是刚刚好final_end和final在同一位置,这个容器满了,要对这这个容器做扩容操作。首先对开辟和这个空间的2呗大小的空间

接着把老空间数据拷贝到新空间中释放老空间。

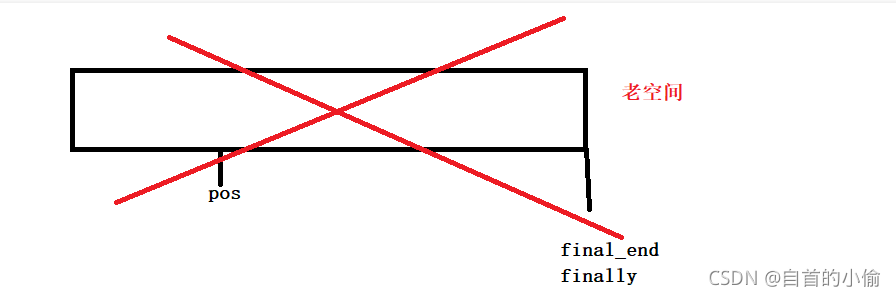
由于老空间释放了pos指向的内存不见了。pos指针就成了野指针。
这如何解决呢就是在老空间解决之间保存这个指针,接着让他重新指向新空间的原来位置。
而insert()函数返回了这个位置迭代器这为迭代器失效提供了方法,这个方法就是重新赋值。让这个指针重新指向该指向的位置。
5.对erase()数据删除时迭代器失效刨析
Iteratot erase(Iteratot iterator) {
assert(iterator <= final_end && iterator >= start);
auto it = iterator;
while (it <final_end) {
*it = *(it+1);
it++;
}
final_end--;
return iterator;
}
vector使用erase删除元素,其返回值指向下一个元素,但是由于vector本身的性质(存在一块连续的内存上),删掉一个元素后,其后的元素都会向前移动,所以此时指向下一个元素的迭代器其实跟刚刚被删除元素的迭代器是一样的。
以下为解决迭代器失效方案:
#include <vector>
#include <iostream>
using namespace std;
int main()
{
int a[] = {1, 4, 3, 7, 9, 3, 6, 8, 3, 3, 5, 2, 3, 7};
vector<int> vector_int(a, a + sizeof(a)/sizeof(int));
/*方案一*/
// for(int i = 0; i < vector_int.size(); i++)
// {
// if(vector_int[i] == 3)
// {
// vector_int.erase(vector_int.begin() + i);
// i--;
// }
// }
/*方案二*/
// for(vector<int>::iterator itor = vector_int.begin(); itor != vector_int.end(); ++itor)
// {
// if (*itor == 3)
// {
// vector_int.erase(itor);
// --itor;
// }
// }
/*方案三*/
vector<int>::iterator v = vector_int.begin();
while(v != vector_int.end())
{
if(*v == 3)
{
v = vector_int.erase(v);
cout << *v << endl;
}
else{
v++;
}
}
/*方案四*/
// vector<int>::iterator v = vector_int.begin();
// while(v != vector_int.end())
// {
// if(*v == 3)
// {
// vector_int.erase(v);
// }
// else{
// v++;
// }
// }
for(vector<int>::iterator itor = vector_int.begin(); itor != vector_int.end(); itor++)
{
cout << * itor << " ";
}
cout << endl;
return 0;
}
一共有四种方案。
方案一表明vector可以用下标访问元素,显示出其随机访问的强大。并且由于vector的连续性,且for循环中有迭代器的自加,所以在删除一个元素后,迭代器需要减1。
方案二与方案一在迭代器的处理上是类似的,不过对元素的访问采用了迭代器的方法。
方案三与方案四基本一致,只是方案三利用了erase()函数的返回值是指向下一个元素的性质,又由于vector的性质(连续的内存块),所以方案四在erase后并不需要对迭代器做加法。
以上就是C语言数据结构之vector底层实现机制解析的详细内容,更多关于C语言 vector底层机制的资料请关注海外IDC网其它相关文章!
【来源:http://www.nextecloud.cn/hk.html 转载请保留连接】