
C++char类型和输入输出优化
目录
- 1、char类型
- 2、getchar、putchar、cin.get、cout.put
- 3、输入输出中文
1、char类型
char的全称是character,也就是字符的意思。顾名思义,char类型是专门为了存储字符而设计的。
计算机存储数字非常方便,只需要将其转化成二进制即可。但存储字符就有点麻烦了,一般都是通过对字符进行数字化编码。这也就是为什么char类型本质上是另外一种整数,因为它存储的其实是字符的数字编码。
char一共有8个二进制位,即一个字节,理论上能够存储256个字符。基本上足够涵盖计算机当中所有的字母、标点符号以及数字,即ASCII码。
ASCII的全称是美国信息交换标准代码,它是一套电脑编码系统,包含了所有英文字母以及标点符号和一些特殊字符。全表一共有128个字符,刚好可以用一个char(有符号)来存储。
大家可以参考一下下表,Dec表示编号,Char表示字符。
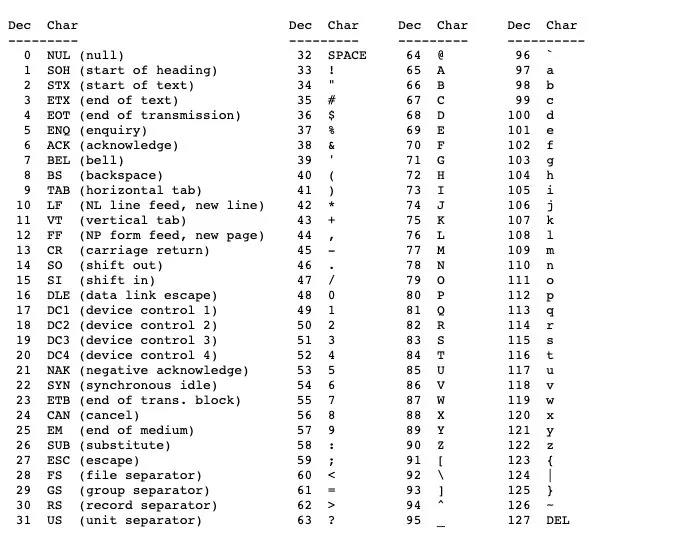
其中数字0的编号是48,字母a的编号是97,大写字母A的标号是65。
当我们把一个字符赋值给char型变量的时候,它会去查ASCII表,找到字符对应的编号。同样,当我们使用%c输出一个字符的时候,它也会去寻找char中存储的编码对应的符号进行输出。
既然字符在C++当中都是以数字的形式存储的,那么我们就可以对它来进行加减运算。
比如:
char c = 'a'; cout << ++c << endl;
得到的结果是'b',有加自然也有减,我们也可以对它做减法操作。
char c = 'b'; cout << --b << endl;
得到的结果就是'a'。
另外,我们还可以对于两个char类型的变量进行减法操作。比如用得比较多的就是将字符型的数字转成int型。
char c = '1'; int num = c - '0';
这样我们得到的num就是数字型的1。
再比如,我们还可以通过大于小于符号来判断char类型的范围:
char c = '1';
if (c >= '0' && c <= '9') {
cout << "c is a number" << endl;
}
2、getchar、putchar、cin.get、cout.put
getchar和putchar都是C语言当中专门面向字符IO的函数,也就是读入和输出字符的函数。
因为确定了处理的数据类型是字符,不需要额外的格式说明,因此getchar和putchar的效率要比scanf和printf更高。
所以在算法竞赛领域,有人为了提升程序的性能,丧心病狂地使用getchar代替scanf来读入数据。
我这里贴一段使用getchar来读入int型的代码,给大家做一个参考。这个属于标准的奇淫技巧,不推荐使用。
void read(int &x) {
int f = 1; x = 0; char s = getchar();
while (s < '0' || s > '9') {
if (s == '-') {
f = -1;
s = getchar();
}
}
while (s >= '0' && s <= '9') {
x = x * 10 + s - '0';
s = getchar();
}
x *= f;
}
cin.get和cout.put与getchar和putchar的用法类似,只不过是C++当中的特性。大家可以参考一下下面这个例子,就不过多赘述了。
char c; cin.get(c); cout.put(c);
3、输入输出中文
关于这一段我犹豫了很久要不要加,因为实在是没有相关经验,毕竟之前只刷题了。纠结了很久还是决定写上,因为这个问题对于不少同学应该挺重要的,尤其是想要做C++工程的同学。本人水平有限,勉强整理了一下各方资料,如有错误,欢迎指出~
其实直接在C++当中是可以直接输出中文的,这并不会有什么问题。
比如下列代码,是可以完美运行的:
string str; cin >> str; cout << str << endl; cout << str.length() << endl;

只是为什么最后输出的长度是6?因为我是在Mac上跑的这段代码。在Mac当中默认使用utf-8编码,一个汉字的长度是3个字节。C++当中的字符串计算长度的时候统计的是字节的数量,所以两个汉字的长度是6。
如果我们是在源代码当中写入了中文,比如:
string str = "中文"; cout << str << endl;
这就可能一些问题,最常见的问题就是代码存储环境和运行环境的默认编码不同,比如IDE当中默认是utf-8编码,但是终端默认是gbk编码(windows系统常见)。这就会导致输出的结果是乱码。
解决方案是我们可以使用wchar_t,wchar_t即char的宽类型版本,它占据两个字节。可以用来存储unicode编码的字符:
const wchar_t* str = L"中文";
我们在中文两个字之前加上了L修饰符,它告诉编译器,这是一个宽字符,我们需要编译器根据locale来进行翻译。
locale是指根据计算机用户使用的语言、所在的国家或地区以及文化传统而定义的软件运行时的语言环境。可以将locale理解为一系列环境变量。locale环境变量值的格式为language_area.charset。languag表示语言,例如英语或中文;area表示使用该语言的地区,例如美国或者中国大陆;charset表示字符集编码,例如UTF-8或者GBK。
这些环境变量会对日期格式,数字格式,货币格式,字符处理等多个方面产生影响。在Linux系统下打开Terminal,输入locale命令,就可查看当前系统使用的语言环境。
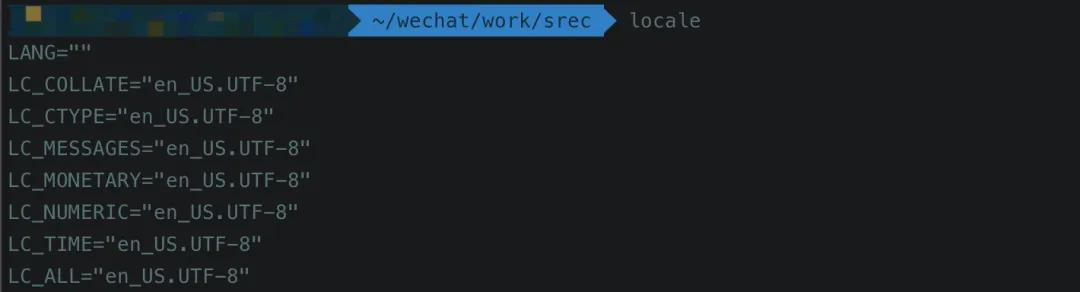
locale的结果包含12类,我在网上也找到了表格:
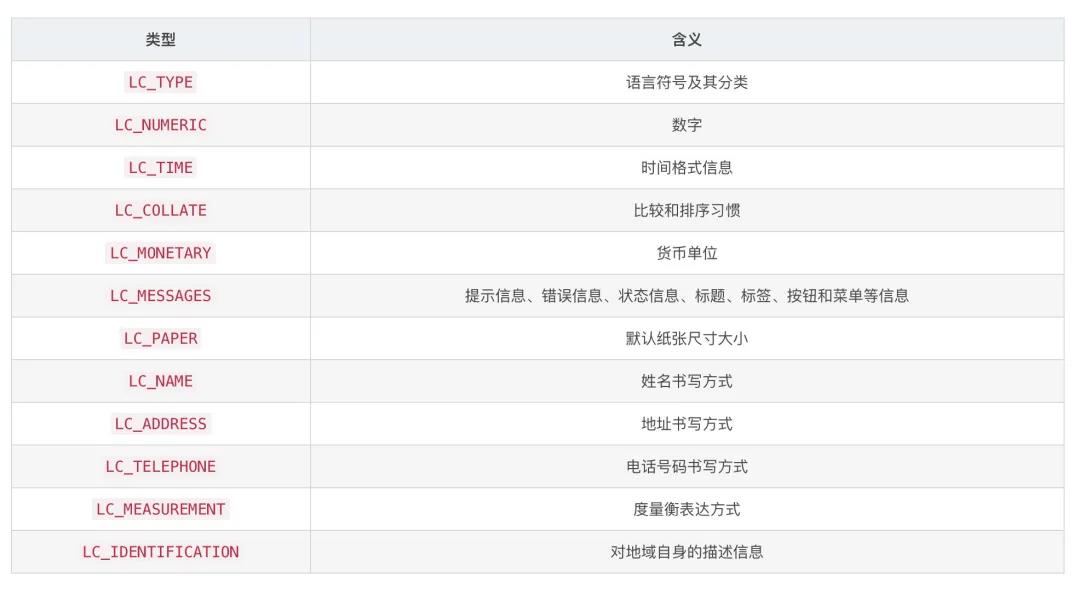
LANG指的是未设置的默认值,大部分程序应用LANGUAGE指定的语言作为界面语言。LC_ALL同时设置所有的内容,并且其优先级比每个内容单独设置的优先级都高,而LANG的优先级最低。
cin和cout可以看成是针对char的流,所以不适合应用在wchar_t类型的处理上。与之对应我们应该使用wcin和wcout。而wcout默认采用的是C local,并不认识中文,所以我们要先对wcout的local进行设置。将其设置成和运行环境的local一致。
大约有以下几种设置方法:
#include <codecvt>
const wchar_t* str = L"中文";
// 使用默认local
locale loc("");
wcout.imbue(loc);
// 使用local命令显示的结果
locale loc("en_US.UTF-8");
wcout.imbue(loc);
// 使用标准facet
locale utf8(locale(), new codecvt_utf8_utf16<wchar_t> );
wcout.imbue(utf8);
// 使用系统local
locale sys_loc("");
wcout.imbue(sys_loc);
wcout << str << endl;
cout << wcslen(str) << endl;
我们可以使用wcslen来计算宽字节字符串的长度,它输出的结果是2,而不是6。
C++当中的编码设置是一个很大的问题,因为在刷题当中几乎不会遇到,我们这里也只是做一个浅尝辄止的讨论。大家如果有需要,可自行深入研究。
到此这篇关于C++char类型和输入输出优化的文章就介绍到这了,更多相关C++char类型和输入输出优化内容请搜索海外IDC网以前的文章或继续浏览下面的相关文章希望大家以后多多支持海外IDC网!
注:文章转自微信公众号:Coder梁(ID:Coder_LT)
【文章出处:香港多ip服务器 复制请保留原URL】