
浅谈C语言结构体
目录
- 前言
- 什么是结构体
- 结构体类型的声明
- 结构的自引用
- 结构体变量的定义和初始化
- 结构体的使用
- 结构体内存对齐
- 结构体传参
- 总结
前言
在C语言中,除了内置的许多数据类型,C语言还为我们提供了自定义的数据类型,其中就包括结构体这一数据类型。
今天就让我们来学习一下与结构体相关的知识吧!

什么是结构体
首先我们要知道,什么是结构体?
在现实生活中,每一个事物都是复杂的,拥有许多的属性,为了表示这些属性,我们不可能用单一的数据类型来表示。
例如:一只猫具有的属性有:年龄、体重、名字、品种等等。
为了描述这只猫的属性,我们可以用整型变量来记录年龄、用浮点型变量来记录体重,用字符数组来记录名字和体重等等。
但是,这就需要我们创建多个变量来表示这只猫。就以上面的栗子来说,如果我们只需要表示一只猫的属性,就需要创建四次变量,这倒也可以接收,但如果我们要表示100只猫呢?我们就不可能每一只猫都单独的创建四次变量了吧?
我们可以知道,每一次猫的属性基本上都是相同的,无外乎年龄、体重、名字、品种等等,那么我们可不可把这些属性抽象出来呢?答案是肯定的,这就是我们的结构体!
结构体类型的声明
结构体声明的格式如下:
struct tag
{
member-list;
}variable-list;
代码演示如下
struct Stu
{
char name[20];//名字
int age;//年龄
char sex[5];//性别
char id[20];//学号
};//分号不能丢
结构体有时候还可以进行特殊的声明
例如,不完全声明
//匿名结构体类型
struct
{
int a;
char b;
float c;
}x;
struct
{
int a;
char b;
float c;
}a[20], *p;
上面的两个结构在声明的时候省略掉了结构体标签(tag)。
那么,问题来了?
//在上面代码的基础上,下面的代码合法吗? p = &x;
答案是否定的。
编译器会把上面的两个声明当成完全不同的两个类型。
所以是非法的。
结构的自引用
在结构中包含一个类型为该结构本身的成员是否可以呢?
//代码1
struct Node
{
int data;
struct Node next;
};
//可行否?
上述代码是否可行呢?
答案也是否定的,结构体内部的成员变量不可包含结构体本身,否则就会无限套娃,死循环下去了。
当我们想要结构体里面还能有一个变量能够指向一个结构体的话,我们可以利用指针。
正确的自引用方式如下:
//代码2
struct Node
{
int data;
struct Node* next;
};
结构体变量的定义和初始化
有了结构体类型,那如何定义变量,其实很简单。
我们可以先声明结构体类型,然后直接再后面定义结构体。
也可以先声明结构体类型,然后单独的定义结构体。
我们可以再定义结构体的同时对其进行初始化。
还可以先单独定义一个结构体,然后再单独对其初始化。
具体看下面的代码演示:
struct Point
{
int x;
int y;
}p1; //声明类型的同时定义变量p1
struct Point p2; //定义结构体变量p2
//初始化:定义变量的同时赋初值。
struct Point p3 = {x, y};
struct Stu //类型声明
{
char name[15];//名字
int age; //年龄
};
struct Stu s = {"zhangsan", 20};//初始化
struct Node
{
int data;
struct Point p;
struct Node* next;
}n1 = {10, {4,5}, NULL}; //结构体嵌套初始化
struct Node n2 = {20, {5, 6}, NULL};//结构体嵌套初始化
结构体的使用
结构体的使用方法有两种:一是结构体直接使用成员变量,二是利用结构体指针来引用成员变量。
具体看下面的代码演示:
struct Stu
{
double sco;//分数
int age;//年龄
char sex;//性别
};//分号不能丢
int main(){
struct Stu s1;
struct Stu* p;
p = &s1;
//结构体直接访问成员变量
s1.age = 10;
s1.sco = 88.8;
s1.sex = 'N';
//通过结构体指针来访问
p->age = 20;
p->sco = 95.5;
p->sex = 'W';
return 0;
}
结构体内存对齐
在我们已经掌握了结构体的基本使用之后,我们来探讨一个更加深入的问题。
如何计算结构体的大小?
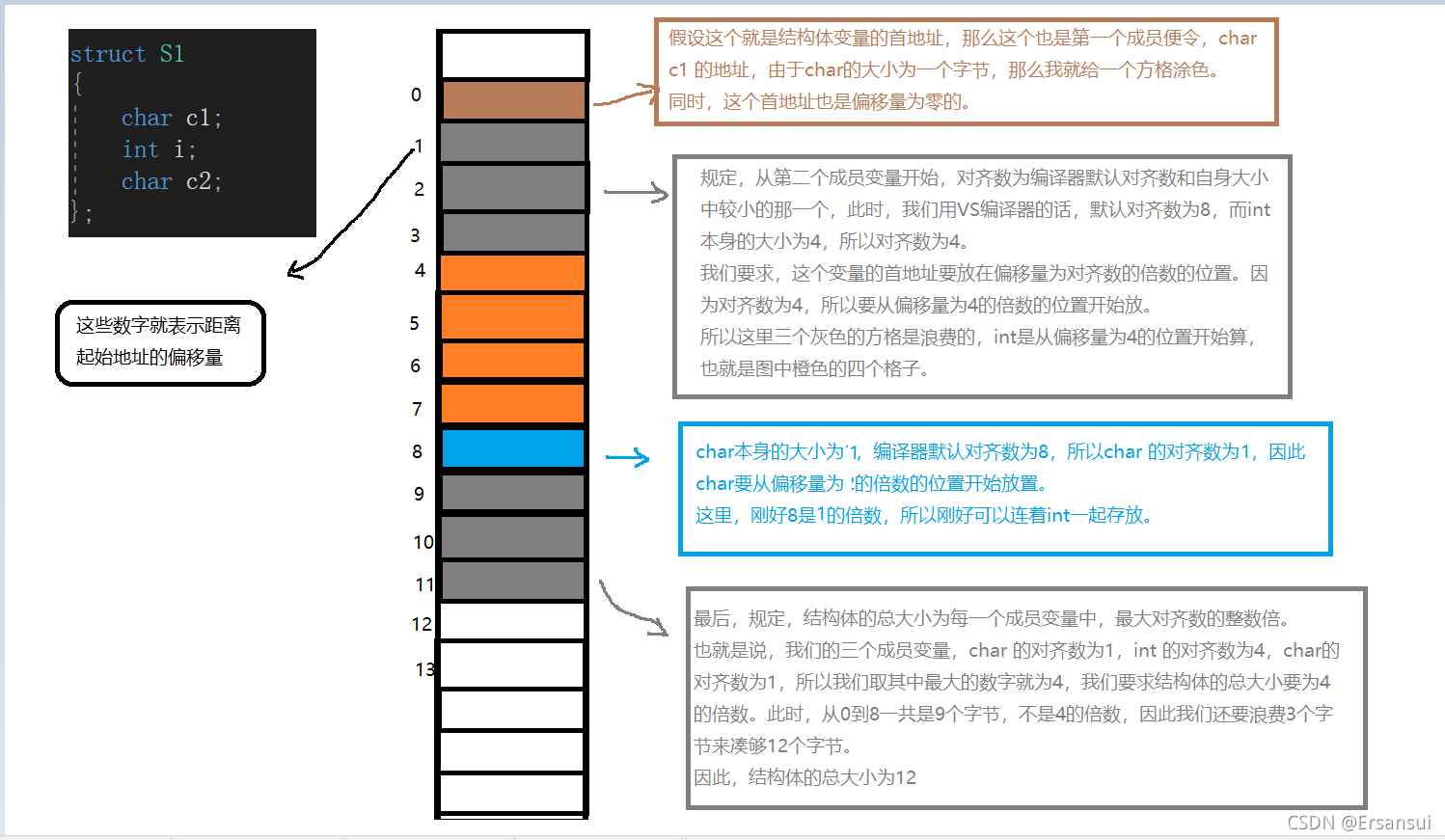
struct S1
{
char c1;
int i;
char c2;
};
printf("%d\n", sizeof(struct S1));
小伙伴们你们认为上述代码的结构是多少呢?
如果你简单的认为是:1+4+1 = 6,那么你就错啦!
这段代码在VS编译器的默认情况下的运行结果为:12
为什么会这样呢?
这是因为,在内存中,存在着结构体对齐!
结构体对齐规则如下:
第一个成员始终在与结构体变量偏移量为0处。其他成员变量要对齐到对齐数的整数倍的地址处。对齐数 = 编译器默认的一个对齐数 与 该成员变量本身大小的较小值。结构体总大小为最大对齐数(每个成员变量都有一个对齐数)的整数倍。如果嵌套了结构体的情况,嵌套的结构体对齐到自己的最大对齐数的整数倍处,结构体的整体大小就是所有最大对齐数(含嵌套结构体的对齐数)的整数倍。
提示:VS编译器默认的对齐数为8
我们回看上面那段代码,并画图分析。
注意
我们可以修改编译器的默认对齐数,我们只需要加上这样一句代码就可以
//这里的数字就是我们想要修改称为的大小 //例如这里我们就修改称为了4 #pragma pack(4)
以上就是结构体对齐的相关知识,由于这一部分内容比较难,所以小伙伴们一定要多加练习哦!
结构体传参
我们先看一段代码
struct S
{
int data[1000];
int num;
};
struct S s = {{1,2,3,4}, 1000};
//结构体传参
void print1(struct S s)
{
printf("%d\n", s.num);
}
//结构体地址传参
void print2(struct S* ps)
{
printf("%d\n", ps->num);
}
int main()
{
print1(s); //传结构体
print2(&s); //传地址
return 0;
}
上面的 print1 和 print2 函数哪个好些?
答案显然是printf2函数。
原因如下:
函数传参的时候,参数是需要压栈,会有时间和空间上的系统开销。如果传递一个结构体对象的时候,结构体过大,参数压栈的的系统开销比较大,所以会导致性能的下降。
因此
我们在结构体传参的时候,需要传结构体的地址。
总结
本篇文章就到这里了,希望能够给你带来帮助,也希望您能够多多关注海外IDC网的更多内容!
【原URL http://www.yidunidc.com/mggfzq.html 请说明出处】