
C++基础算法基于哈希表的索引堆变形
目录
- 问题来源
- 问题简述
- 问题分析
- 代码展示
问题来源
此题来自于Hackerrank中的QHEAP1问题,考查了对堆结构的充分理解。成功完成此题,对最大堆或者最小堆的基本操作实现就没什么太大问题了。
问题简述
实现一个最小堆,对3种类型的输入能给出正确的操作:
- “1 v” - 表示往堆中增加一个值为v的元素
- “2 v” - 表示删去堆中值为v的元素
- “3” - 表示打印出堆中最小的那个元素
注意:题目保证了要删的元素必然是在堆中的,并且在任何时刻,堆中不会有重复的元素。
输入格式:
第1行的值表示共有q个操作,然后再接下来的q行中,每行都有上述3中操作中的任意一种。
比如:
******************输入*******************
5
1 4
1 9
3
2 4
3
******************输出*******************
4
9
问题分析
对于一个最小堆来说,其满足的性质是只要每个子树中的父亲节点的元素小于其左孩子节点和右孩子节点的元素即可,比如下图所示的这样:

图1:最小堆示例图
没错,最小堆根部的元素必然是树中最小的那个元素。除了满足上述的条件之外,最小堆还必须是一颗完全二叉树。也正是由于这个完全二叉树的性质,最小堆是可以用数组来实现的,比如上图的这个最小堆就可以表示成
data = { 5, 8, 20, 10, 35, 12, 50, 15, 16 };
从树结构中不难看出索引之间有关系
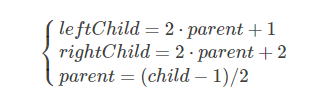
这是我们在更新堆信息时最重要的公式,第3个式子的除法是取整的,所以左右孩子都一样。
如果只需要满足操作”1 v”和操作”3”的话,上述这些就已经完全够用了,难点在于这里需要我们对堆中指定的元素进行删除”2 v”。讲道理,这并不是一个最小堆所应该有的操作,最小堆只要管住最小的那个值就好了,其他的结构怎么样,最小堆并不关心。不过,既然题目故意这么出了,要来刁难我们,我们也只能迎难而上了。
借助于索引堆的想法,我们用一个哈希表来记录每一个元素在堆中的索引位置,这样,我们在删除时只需要 O(1) 的复杂度就可以找到要删除的元素了,而删除的过程是 O(log(n)) 的复杂度。
还是以上面那组数据为例,我们希望记录的是如下的信息。
data = { 5, 8, 20, 10, 35, 12, 50, 15, 16 };
mp = {{20, 2}, {35, 4}, {8, 1}, {5, 0}, {16, 8}, {50, 6}, {12, 5}, {10, 3}, {15, 7}};
哈希表中元素的顺序完全无所谓,只要元素中的对应关系正确即可,所以上面的这个是我乱编的,具体的顺序和插入元素的顺序有关系。
代码展示
最后,来展示一下完整的代码,把下面这个代码直接复制粘贴到题目中去Submit是没问题的。
#include <vector>
#include <iostream>
#include <unordered_map>
using namespace std;
class myHeap{
private:
//作为堆的数组
vector<int> data;
//用于存放<元素值,在堆中的索引>的哈希表
unordered_map<int, int> mp;
//堆中元素的个数
int size;
private:
//上移操作,将元素小的顺着树结构往上移
void _shiftUp(int index){
if (index >= size || index < 0)
return;
while (index != 0){
int newIndex = (index - 1) / 2;
if (data[newIndex] > data[index]){
//更新哈希表中存放的索引
mp[data[newIndex]] = index;
mp[data[index]] = newIndex;
//更新堆中元素的位置
swap(data[newIndex], data[index]);
index = newIndex;
}
else
break;
}
return;
}
//下移操作,将元素大的顺着树结构往下移
void _shiftDown(int index){
if (index >= size || index < 0)
return;
while (index * 2 + 1 < size){
int newIndex = index * 2 + 1;
//选择左节点和右节点中比较小的那个元素
if (newIndex + 1 < size && data[newIndex + 1] < data[newIndex])
newIndex++;
if (data[newIndex] > data[index])
break;
//更新哈希表中存放的索引
mp[data[newIndex]] = index;
mp[data[index]] = newIndex;
//更新堆中元素的位置
swap(data[newIndex], data[index]);
index = newIndex;
}
return;
}
public:
myHeap(){
size = 0;
}
//添加元素
void add(int d){
data.push_back(d);
mp[d] = size++;
_shiftUp(mp[d]);
}
//删除元素
void del(int d){
int index = mp[d];
mp[d] = size - 1;
mp[data[size - 1]] = index;
swap(data[index], data[size - 1]);
size--;
data.pop_back();
_shiftUp(index);
_shiftDown(index);
mp.erase(d);
}
//打印堆中最小值
void showMin(){
cout << data[0] << endl;
}
};
int main() {
/* Enter your code here. Read input from STDIN. Print output to STDOUT */
int q;
cin >> q;
myHeap h;
for (int i = 0; i < q; i++){
int index;
cin >> index;
if (index == 1){
int v;
cin >> v;
h.add(v);
}
else if (index == 2){
int v;
cin >> v;
h.del(v);
}
else if (index == 3){
h.showMin();
}
}
}
如有不足,还请指正~
以上就是C++基础算法基于哈希表的索引堆变形的详细内容,更多关于C++算法哈希表索引堆变形的资料请关注海外IDC网其它相关文章!
【文章出处http://www.nextecloud.cn/kt.html欢迎转载】