
C语言编程之预处理过程与define及条件编译
目录
- 名示常量#define
- 重定义常量
- 在#define中使用参数
- 预处理器粘合剂:##运算符
- 变参宏:… 和_ _ VAG_ARGS_ _
- 宏与函数
- 预处理指令
- #undef指令
- 从C预处理器的角度看已定义
- 条件编译
- offsetof函数
这张图描述了从源文件到可执行文件的整体步骤
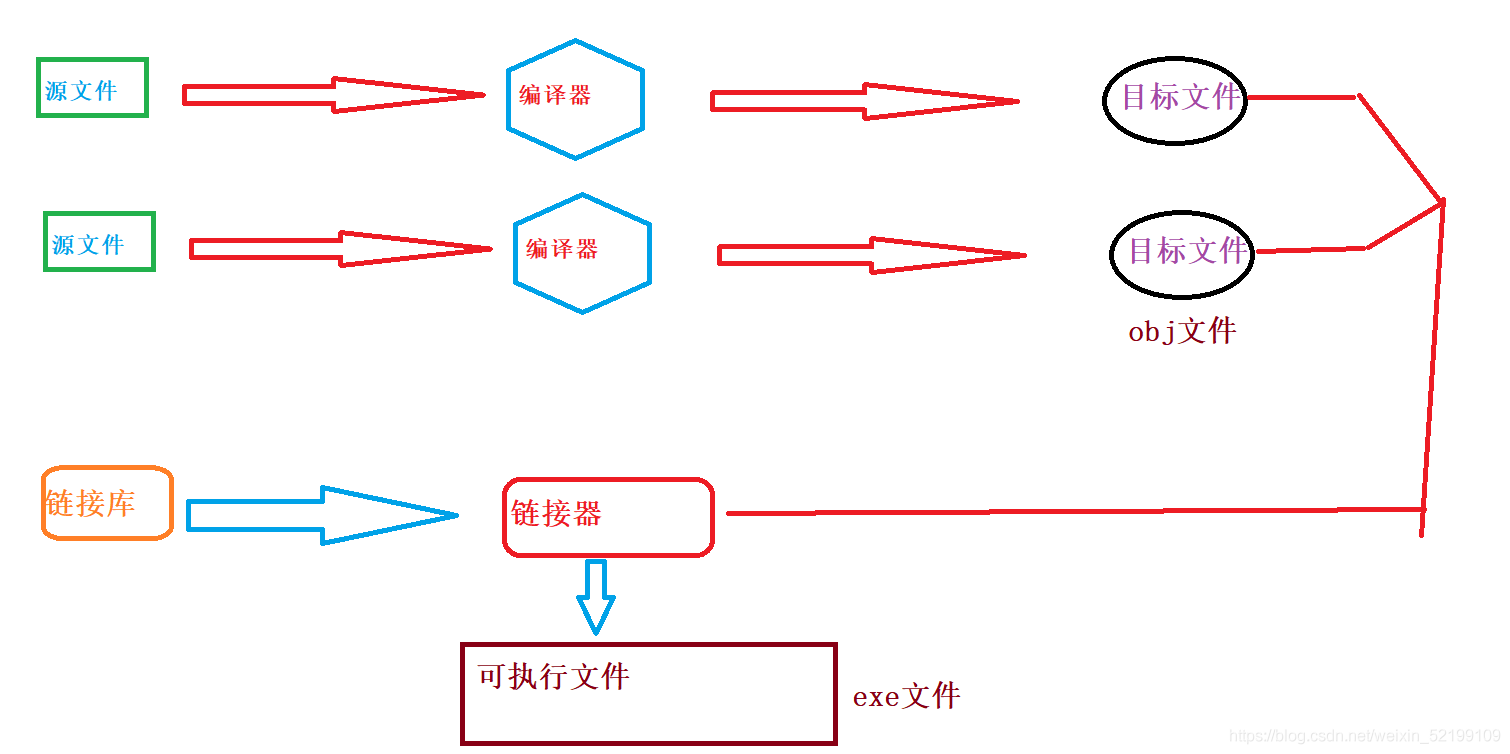
这张图展示了大体上步骤。
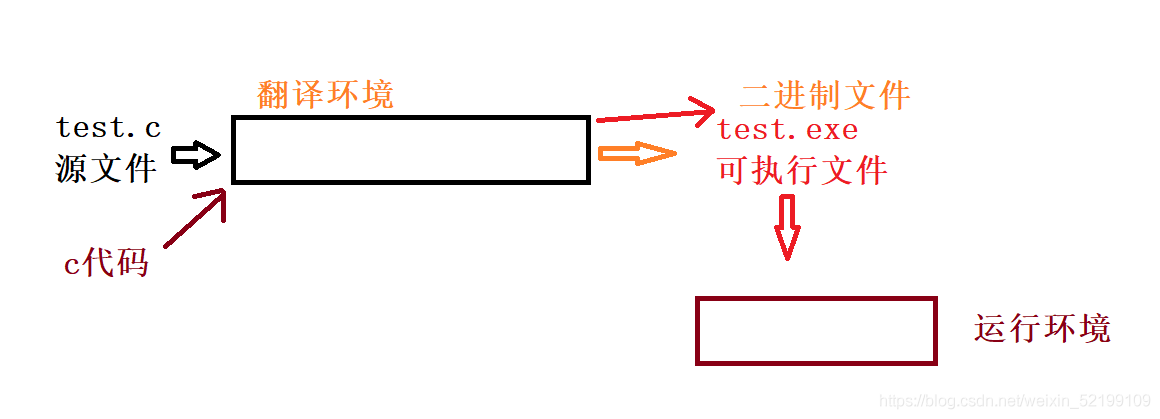
从代码到运行环境,编译器提供了翻译环境。在一个程序中,会存在多个文件 ,而每个源文件都会单独经过编译器处理。
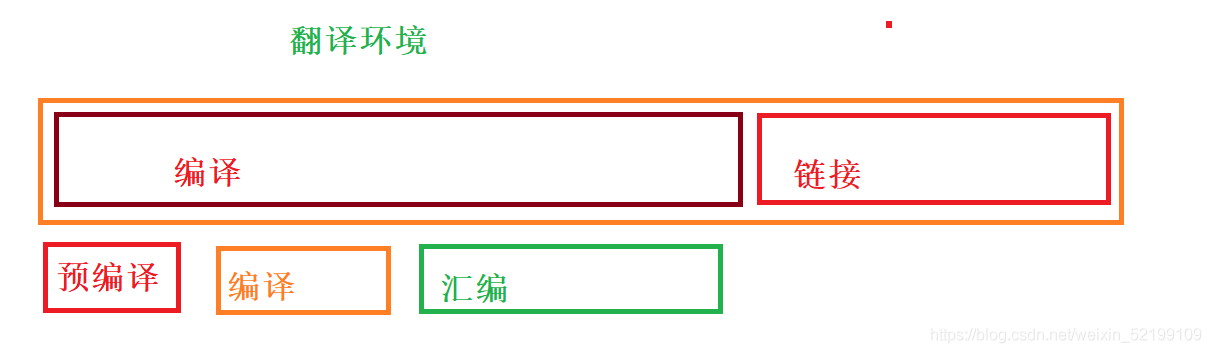
预编译:
1,会将#include等头文件所包含的内容,库函数全部拷贝过来
2,代码中注释的删除
3,由#define所定义的符号全部替换进代码中
对预处理指令的操作
编译:把C代码翻译成汇编代码
1,语法分析(判断是否存在语言的语法错误而造成无法编译)
2,词法分析
3,语义分析(分析每句代码的意思)
4,符号汇总(会将整个程序中的全局符号进行汇总)
汇编
1,形成符号表
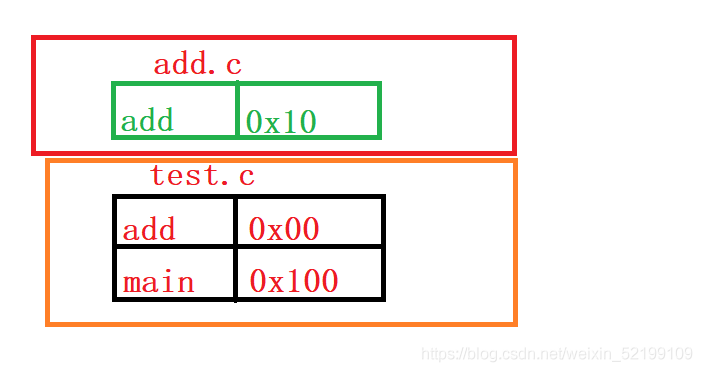
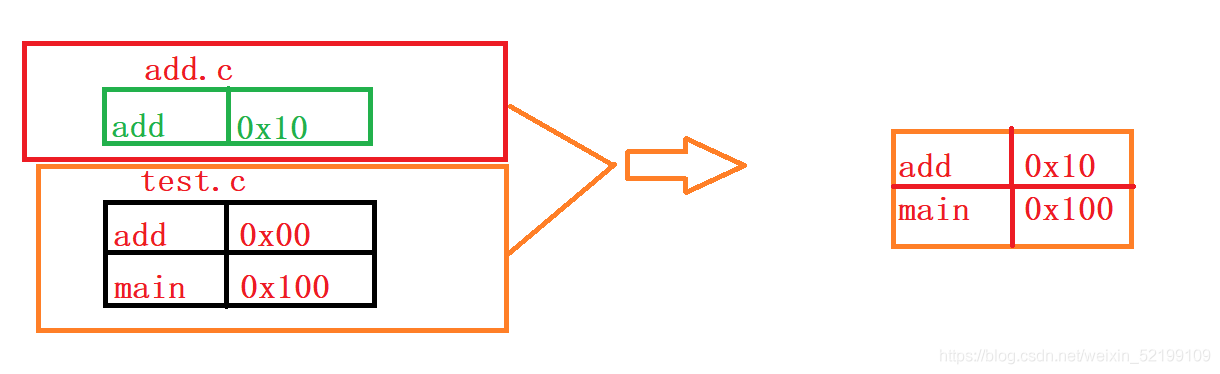
一个程序,两个文件test.c与add.c,在test.c中,有
extern int add(int x,int y);//声明对该函数引用,在其他文件中找该函数。
在汇编时,各个文件都会形参函数符号表,但extern并不会形成地址标记,只是一个0x00。
链接:合并段表
符号表的合并与重定位检查各个函数及其定义声明
名示常量#define
define的预处理指令
#define MACRO substitution
预处理指令 宏 替换体
宏只是起到替换作用,在替换过程中不产生任何运算
举个例子
#define SUM 2+2 int num = SUM * SUM;
不了解的人可能会认为是
num=44;
但,实际是替换作用
num=2+22+2;
这就是宏只起到替换作用的意思。
再来介绍一个原理性概念
记号
从技术角度来看,可以把宏的替换体看作是记号型字符串。而不是字符型字符串。在C预处理器记号是宏定义的替换体的中单独的“词”,用空白把词分开。例如:
#define FOUR 2*2 #define FOURS 2 * 2
这两个对于预处理器要看预处理器把这个替换体看成什么。如果是字符型字符串,这空格也会是字符串的一部分。但如果是记号型字符串,空格就会被认为是分隔符,就和2*2是一个意思。总之要看编译器的规则。
总结一下
如果编译器理解替换体是字符型字符串,那么空格就会被认为是字符串的一部分
2 * 2就和2*2不是一个意思。
如果编译器理解为记号型字符串,那么空格就会被认为只是分隔符,并不影响。空格不算替换体的一部分
2 * 2和2乘2则是一个意思。
重定义常量
假设把MAX设为30,在文件中又把它重新定义为10.这个过程叫重定义常量但不同的标准有不同的规则。有一些允许重定义,但是会报警。ANSI标准则采用,只有新旧定义完全相同才允许重定义。
完全相同意味着替换体中必须记号完全相同,顺序也必须相同 。
#define MAX 2 * 3 #define MAX 2 * 3
这才允许
#define MAX 2 * 3 #define MAX 2*3
这不符合那个标准。(虽然我不知道这个标准的重定义有什么用,我比较菜)
注:根据一个大佬的建议,这类代码非常致命,非常不好,最好不使用。
在#define中使用参数
在#define中也可以创建外形和作用与函数类似的类函数宏。
带有函数的宏可以达到部分函数的作用。
#define SQUARE(X) X*X mul=SQUARE(2);
与函数调用有些相似。
同时最好使用足够多的括号去确保运算和结合性的正确。
mul=SQUARE(x++)
则会造成运算不符合要求。
用宏参数创建字符串:#运算符
#define PSQRA(X) printf("X is %d\n",((X)*(X));
#define PSQRB(X) printf("#X" is %d\n",((X)*(X));
这两个是可以打印出不同的效果
#作为一个预处理运算符,可以把记号转换成字符串,如果X是一个宏形参,那么#X就是“X”的字符串的形参名。
这叫字符串化
int y=50; PSQRA(y) X is 2500 PSQRB(Y) y is 2500 PSQRA(2+4) X is 36 PSQRB(2+4) 2+4 is 36
这就是区别。
预处理器粘合剂:##运算符
#运算符可以作用于宏的替换体
而##运算符也可以作用。
#define NUMBER(n) X##n NUMBER(4)可展开为x4
例如
#include <stdio.h>
#define XNAME(N) x##N
#define PRINT(N) pritnf("x"#N"=%d\n",x##N);
int main(void)
{
int XNAME(1) = 10;//x1=10
int XNAME(2) = 20;//x2=10
int x3 = 0;
PRINT(1);//printf("x1=%d",x1);
PRINT(2);//printf("x2=%d",x2);
PRINT(3);//printf("x3=%d",x3);
}
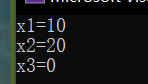
变参宏:… 和_ _ VAG_ARGS_ _
一些函数可以接受数量可变的参数(就是没有固定传递的参数的数量,如printf()和scanf())。而宏也可以拥有这样的能力。
#define PR(...) printf(_ _VAG_ARGS_ _)
PR("HELLO WORLD");//printf("HELLO WORLD");
PR("x1=%d,x2=%d",10,20);//printf(""x1=%d,x2=%d",10,20);
相当于这样的效果。
省略号只能代替最后的宏参数。不能在省略号加其他参数。
#define PR(x,...,y) #x #_ _VAG_ARGS_ _ #y
是不被允许的。
宏与函数
有相当一部分的宏可以起到和函数一样的效果,但到底该怎么选呢?
宏和函数可以达到同样效果。宏比函数要简单一些,同时,在编译器的消耗时间也要远小于函数。但是稍有不慎就会产生一些副作用,导致结果不可预测。
宏与函数的比较实际上就是关于时间与空间的比较。
宏在预编译的时候会生成内联代码,也就是会在程序中替换生成语句。如果调用20次,则会在程序中插入20行代码。
但如果调用函数20次,函数也只有一份副本,节省了相当一部分空间。但执行函数时,要调用,再执行,再返回,远比宏插入内联语句消耗的时间要多。
宏较函数也存在缺陷
- 当宏较大时会增加代码长度。
- 宏是无法调试(在预编译的时候就已完成替换),可能会出现问题。
- 宏由于不要求类型,会造成不严谨(这也是对于函数的一个好处,函数传参会要求参数类型,而宏只会将参数当作字符串处理,只要是int或float类型都可以)
- 宏可能会带来运算符优先级的问题,使运算不可预测。
自己按照情况去使用。如果使用宏容易出现副作用,那还是调用函数吧。
但要记住以下几点
1,记住宏名中不允许有空格,但在替换字符串中可以有空格。ANSI C允许在参数列表中使用空格。
2,用括号把宏的参数和替换体括起来,正确展开,防止出现副作用。
3,一般用大写字母表示宏常量,一般不全大写表示宏函数
4,如果用宏来加快函数的运行速度,要先确定宏和函数之间是否有差距。且,如果只使用一次那对速度加快影响不大。最好在多重嵌套中使用。
预处理指令
当编译器碰上#include 指令时,会查看后面文件名并把内容添加到当前文件中。
#include <stdio.h>//查找系统目录文件 #include "mtfile.h"//查找当前工作目录 #include "/usr/biff/file.h"//查找/usr/biff/目录
不同的系统有不同的规则,但<>与“”的规则是不变的。
通过头文件的引用,我们才能使用各种函数。头文件中有各种函数的声明。再通过库文件去调用函数的原型。
#undef指令
可以通过该指令去向之前#define定义的宏
#include <stdio.h>
#define MAX 10
#undef MAX
int main(void)
{
printf("%d", MAX);
}

直接报错
#undef可以取消,某个宏的定义,可以用用来防止某个宏被重复定义,造成错误。
从C预处理器的角度看已定义
预处理器在处理标识符时遵循相同规则。当预处理器发现一个标识符时,会将其当作已定义或未定义。而这里的已定义是由预处理器决定。如果该标识符是由define定义的且没有undef取消,那就是已定义。如果是定义的某个全局变量,那就是未定义(对预处理器而言)。
#define定义的宏的作用域从文件开头开始,延申至文件结尾或者遇到#undef取消定义,如果跨文件使用,那使用的位置要在#include引用的文件后。
条件编译
就跟条件判断语句有着类似的意思。
#ifdef , #else , #endif
举个例子
#include <stdio.h>
#define MAX 10
#undef MAX
#ifdef MAX
#include <string.h>
#define MIN 10
#endif //
int main(void)
{
printf("%d", MIN);
}

结果就是这个。
但屏蔽#undef
#include <stdio.h>
#define MAX 10
//#undef MAX
#ifdef MAX
#include <string.h>
#define MIN 10
#endif //
int main(void)
{
printf("%d", MIN);
}
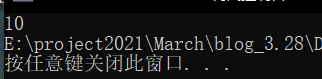
可以运行。
条件编译指令与条件判断语句类似。
只不过,条件判断语句是判读是否执行,
二条件编译指令是判断是否进行预编译。
#endif用来结束该指令的范围
再引入一个指令
#ifndef DEBUG
如果DEBUG未定义就执行编译,如果已定义就不执行。
还有这几个指令,非常接近条件判断语句
#if ,#elif ,#else
#if和#elif与if和else if类似。但它们的后面接整形常量表达式。
0为假,非0为真
都是判断是否进行预编译
可以通过条件编译指令去防止某些文件被多次调用导致问题出现
#ifndef _FILE_H #define _FILE_H 文件内容 。 。 #endif
或者直接使用
#pragma once //可以保证文件只是使用一次
offsetof函数
size_t offsetof( structName, memberName );
用于测算结构体成员相对于起始位置的偏移量
实现
#define OFFSETOF(structName,memberName) (int)&(((struct structName*)0)->memberName)
从0地址处,开始向成员访问再取地址在强转成整形。
以上就是C语言编程之预处理过程与define及条件编译的详细内容,更多关于C语言预处理的资料请关注海外IDC网其它相关文章!
【本文由:日本cn2服务器 提供 转载请保留URL】