
C++哈希应用的位图和布隆过滤器
目录
- C++哈希应用的位图和布隆过滤器
- 一、位图
- 1.位图的概念
- 2.位图的面试题
- 3.位图的实现
- 4.位图的应用
- 二、布隆过滤器
- 1.布隆过滤器的提出
- 2.布隆过滤器的概念
- 3.布隆过滤器的插入
- 4.布隆过滤器的查找
- 5.布隆过滤器的删除
- 6.布隆过滤器的优点和缺点
- 三、海量数据面试题
- 1.哈希切割
- 2.位图应用
- 3.布隆过滤器
C++哈希应用的位图和布隆过滤器
一、位图
1.位图的概念
所谓位图,就是用每一位来存放某种状态,适用于海量数据,数据无重复的场景。通常是用来判断某个数据存不存在的。
2.位图的面试题
给40亿个不重复的无符号整数,没排过序。给一个无符号整数,如何快速判断一个数是否在这40亿个数中。【腾讯】
- 遍历,时间复杂度O(N)。
- 排序(O(NlogN)),利用二分查找: logN。
- 位图解决。
数据是否在给定的整形数据中,结果是在或者不在,刚好是两种状态,那么可以使用一个二进制比特位来代表数据是否存在的信息,如果二进制比特位为1,代表存在,为0代表不存在。比如:
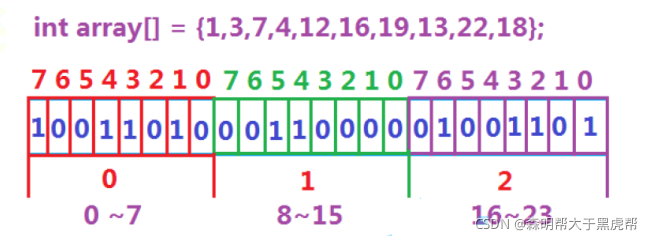
3.位图的实现
#include<iostream>
#include<vector>
#include<math.h>
namespace yyw
{
class bitset
{
public:
bitset(size_t N)
{
_bits.resize(N / 32 + 1, 0);
_num = 0;
}
//将x位的比特位设置为1
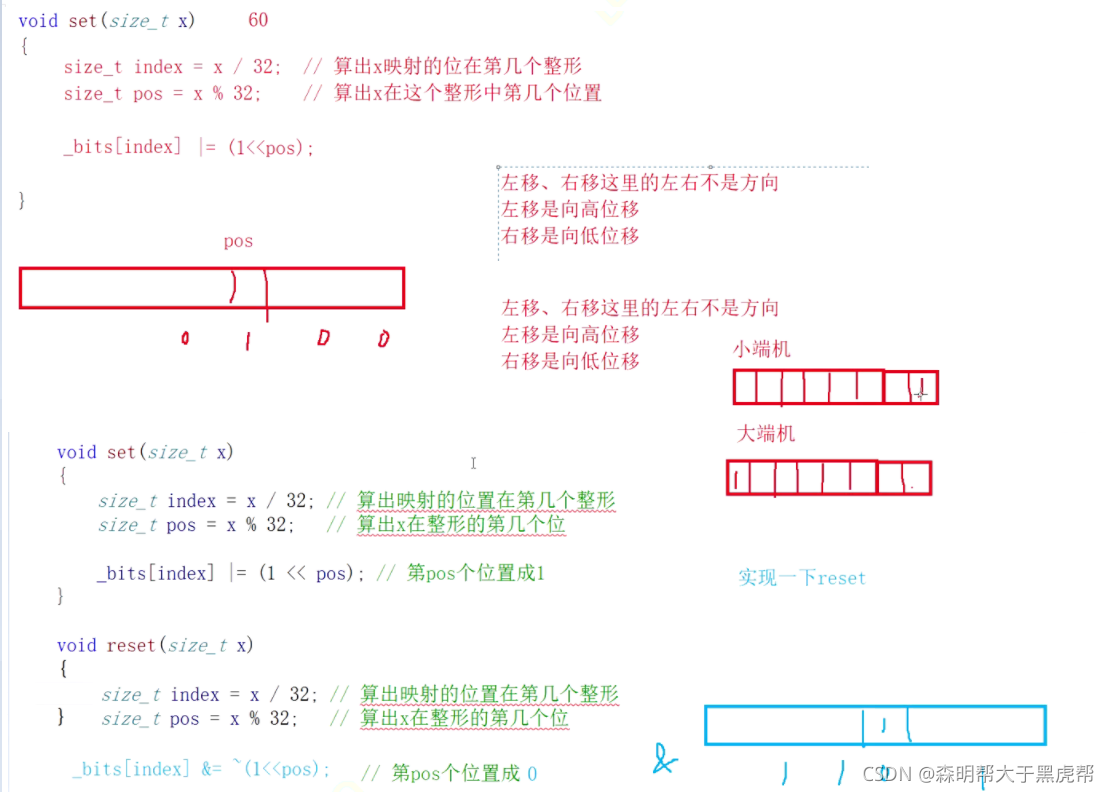
void set(size_t x)
{
size_t index = x / 32; //映射出x在第几个整形
size_t pos = x % 32; //映射出x在整形的第几个位置
_bits[index] |= (1 << pos);
_num++;
}
//将x位的比特位设置为0
void reset(size_t x)
{
size_t index = x / 32;
size_t pos = x % 32;
_bits[index] &= ~(1 << pos);
_num--;
}
//判断x位是否在不在
bool test(size_t x)
{
size_t index = x / 32;
size_t pos = x % 32;
return _bits[index] & (1 << pos);
}
//位图中比特位的总个数
size_t size()
{
return _num;
}
private:
std::vector<int> _bits;
size_t _num; //映射存储了多少个数据
};
void tes_bitset()
{
bitset bs(100);
bs.set(99);
bs.set(98);
bs.set(97);
bs.set(10);
for (size_t i = 0; i < 100; i++)
{
printf("[%d]:%d\n", i, bs.test(i));
}
//40亿个数据,判断某个数是否在数据中
//bs.reset(-1);
//bs.reset(pow(2, 32));
}
}
4.位图的应用
- 快速查找某个整形数据是否在一个集合中。
- 排序。
- 求两个集合的交集、并集等。
- 操作系统中磁盘块标记。
二、布隆过滤器
1.布隆过滤器的提出
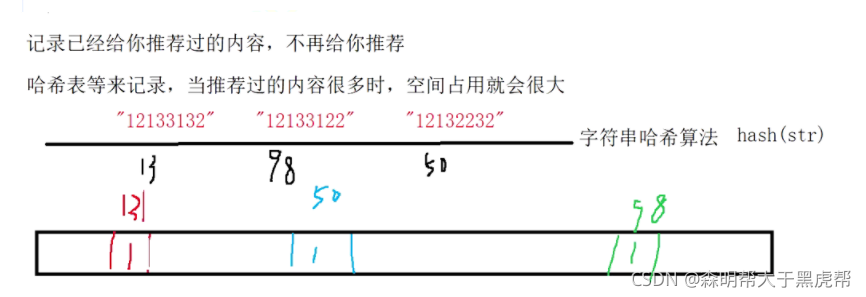
我们在使用新闻客户端看新闻时,它会给我们不停地推荐新的内容,它每次推荐时要去重,去掉那些已经看过的内容。问题来了,新闻客户端推荐系统如何实现推送去重的? 用服务器记录了用户看过的所有历史记录,当推荐系统推荐新闻时会从每个用户的历史记录里进行筛选,过滤掉那些已经存在的记录。 如何快速查找呢?
- 用哈希表存储用户记录,缺点:浪费空间。
- 用位图存储用户记录,缺点:不能处理哈希冲突。
- 将哈希与位图结合,即布隆过滤器。
2.布隆过滤器的概念
布隆过滤器是由布隆(Burton Howard Bloom)在1970年提出的 一种紧凑型的、比较巧妙的概率型数据结构,特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”,它是用多个哈希函数,将一个数据映射到位图结构中。此种方式不仅可以提升查询效率,也可以节省大量的内存空间。
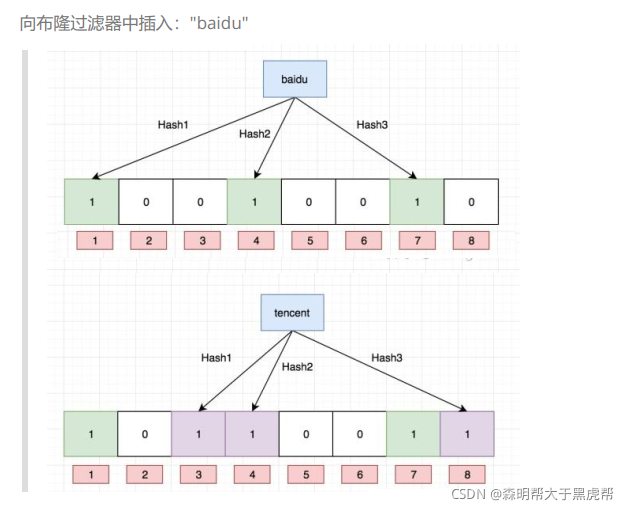
3.布隆过滤器的插入
布隆过滤器底层是位图:
struct HashStr1
{
//BKDR1
size_t operator()(const std::string& str)
{
size_t hash = 0;
for (size_t i = 0; i < str.size(); i++)
{
hash *= 131;
hash += str[i];
}
return hash;
}
};
struct HashStr2
{
//RSHash
size_t operator()(const std::string& str)
{
size_t hash = 0;
size_t magic = 63689; //魔数
for (size_t i = 0; i < str.size();i++)
{
hash *= magic;
hash += str[i];
magic *= 378551;
}
return hash;
}
};
struct HashStr3
{
//SDBHash
size_t operator()(const std::string& str)
{
size_t hash = 0;
for (size_t i = 0; i < str.size(); i++)
{
hash *= 65599;
hash += str[i];
}
return hash;
}
};
//假设布隆过滤器元素类型为K,如果类型为K要自己配置仿函数
template<class K,class Hash1=HashStr1,class Hash2=HashStr2,class Hash3=HashStr3>
class bloomfilter
{
public:
bloomfilter(size_t num)
:_bs(5*num)
, _N(5*num)
{
}
void set(const K& key)
{
size_t index1 = Hash1()(key) % _N;
size_t index2 = Hash2()(key) % _N;
size_t index3 = Hash3()(key) % _N;
_bs.set(index1); //三个位置都设置为1
_bs.set(index2);
_bs.set(index3);
}
}
4.布隆过滤器的查找
布隆过滤器的思想是将一个元素用多个哈希函数映射到一个位图中,因此被映射到的位置的比特位一定为1。所以可以按照以下方式进行查找:分别计算每个哈希值对应的比特位置存储的是否为零,只要有一个为零,代表该元素一定不在哈希表中,否则可能在哈希表中。
bool test(const K& key)
{
size_t index1 = Hash1()(key) % _N;
if (_bs.test(index1) == false)
{
return false;
}
size_t index2 = Hash1()(key) % _N;
if (_bs.test(index2) == false)
{
return false;
}
size_t index3 = Hash3()(key) % _N;
if (_bs.test(index3) == false)
{
return false;
}
return true; //但是这里也不一定是真的在,还有可能存在误判
//判断不在是正确的,判断在可能存在误判
}
注意:布隆过滤器如果说某个元素不存在时,该元素一定不存在,如果该元素存在时,该元素可能存在,因为有些哈希函数存在一定的误判。
比如:在布隆过滤器中查找"alibaba"时,假设3个哈希函数计算的哈希值为:1、3、7,刚好和其他元素的比特位重叠,此时布隆过滤器告诉该元素存在,但实该元素是不存在的。
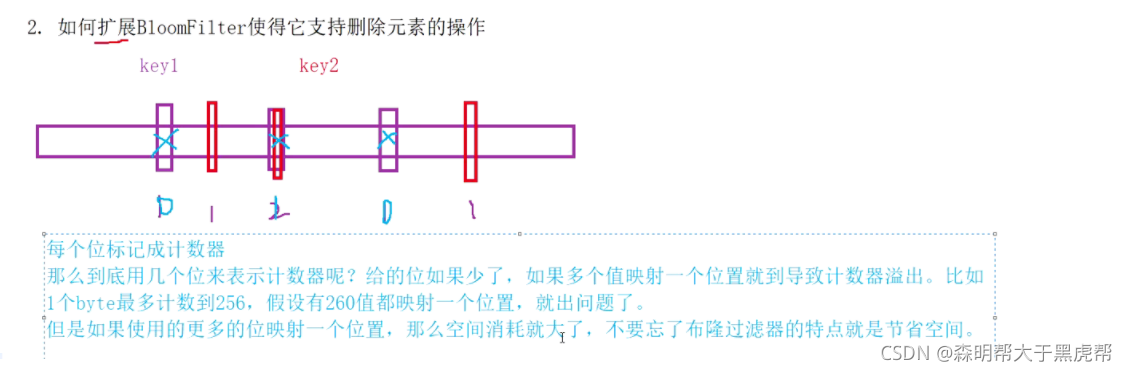
5.布隆过滤器的删除
布隆过滤器不能直接支持删除工作,因为在删除一个元素时,可能会影响其他元素。
比如:删除上图中"tencent"元素,如果直接将该元素所对应的二进制比特位置0,“baidu”元素也被删除了,因为这两个元素在多个哈希函数计算出的比特位上刚好有重叠。

一种支持删除的方法:将布隆过滤器中的每个比特位扩展成一个小的计数器,插入元素时给k个计数器(k个哈希函数计算出的哈希地址)加一,删除元素时,给k个计数器减一,通过多占用几倍存储空间的代价来增加删除操作。
缺陷:
- 无法确认元素是否真正在布隆过滤器中。
- 存在计数回绕。
6.布隆过滤器的优点和缺点
- 优点:节省空间,高效,可以标注存储任意类型
- 缺点;存在误判,不支持删除
位图
- 优点:节省空间
- 缺点:只能处理整形
三、海量数据面试题
1.哈希切割
①给一个超过100G大小的log file, log中存着IP地址, 设计算法找到出现次数最多的IP地址? 与上题条件相同,如何找到top K的IP?如何直接用Linux系统命令实现?
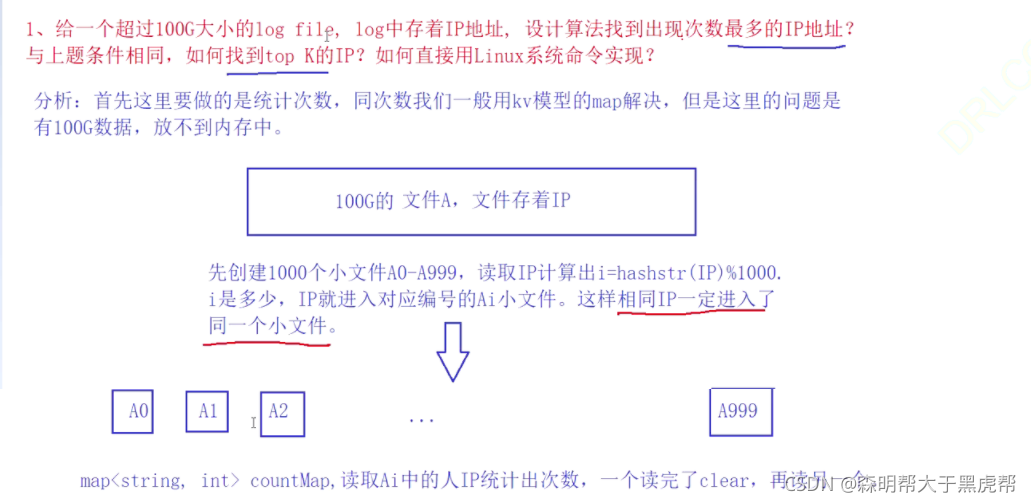
2.位图应用
①给定100亿个整数,设计算法找到只出现一次的整数?

②给两个文件,分别有100亿个整数,我们只有1G内存,如何找到两个文件交集?
- 方案1:将其中一个文件1的整数映射到一个位图中,读取另外一个文件2中的整数,判断在在不在位图,在就是交集。消耗50OM内存
- 方案2:将文件1的整数映射到位图1中,将文件2的整数映射到位图2中,然后将两个位图中的数按位与。与之后为l1的位就是交集。消耗内存1G。
③位图应用变形:1个文件有100亿个int,1G内存,设计算法找到出现次数不超过2次的所有整数?
- 本题跟上面的第1题思路是一样的
- 本题找的不超过2次的,也就是要找出现1次和2次的
- 本题还是用两个位表示一个数,分为出现0次00表示,出现1次的01表示―出现2次的10表示出现3次及3次以上的用11表示
3.布隆过滤器
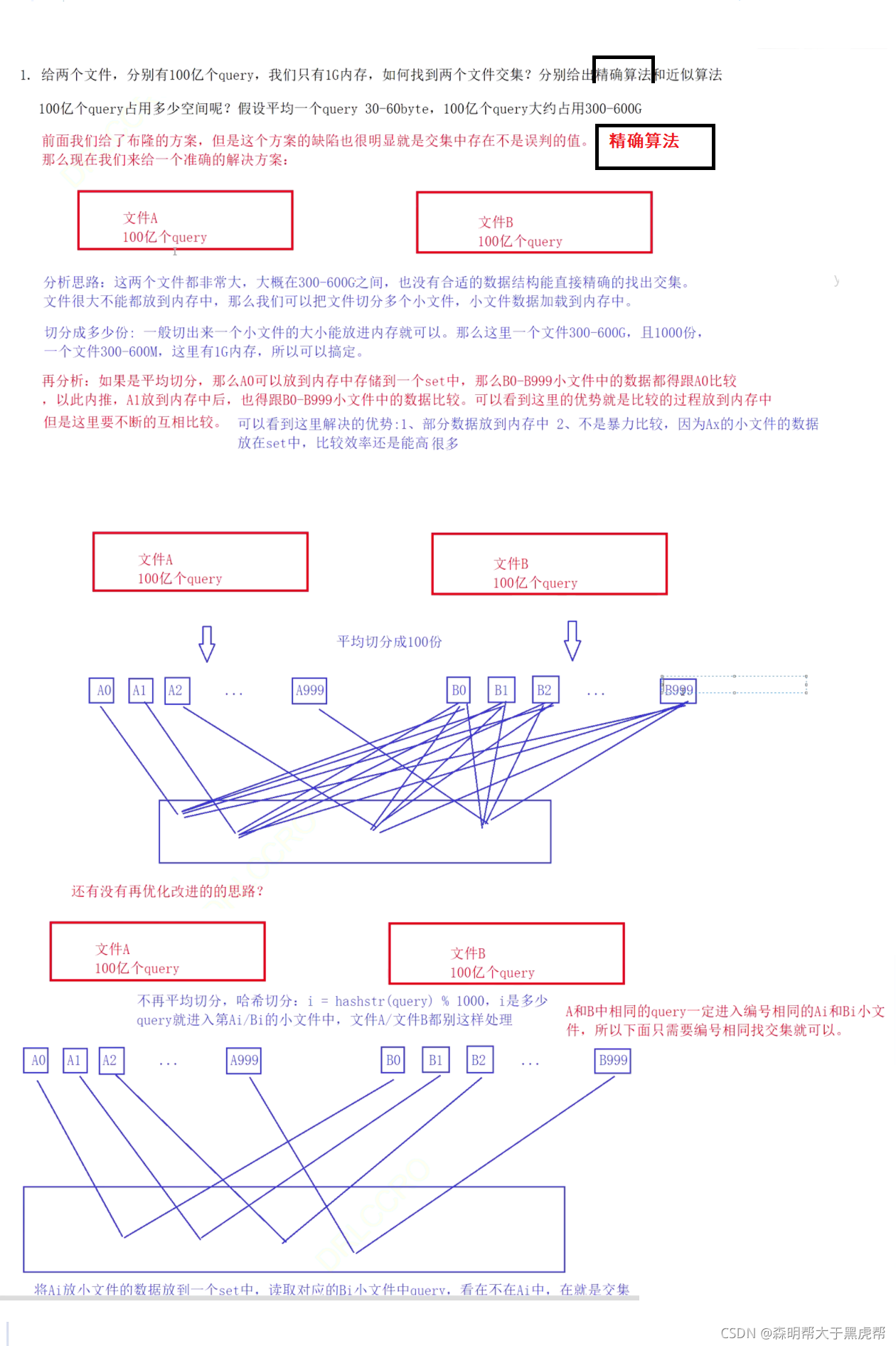
①给两个文件,分别有100亿个query,我们只有1G内存,如何找到两个文件交集?分别给出精确算法和近似算法?
②如何扩展BloomFilter使得它支持删除元素的操作?
到此这篇关于C++哈希应用的位图和布隆过滤器的文章就介绍到这了,更多相关C++哈希应用位图与布隆过滤器内容请搜索海外IDC网以前的文章或继续浏览下面的相关文章希望大家以后多多支持海外IDC网!
【来源:http://www.nextecloud.cn/hk.html 转载请保留连接】