
iOS监控笔记之启动crash
前言
相较于正常的崩溃问题,启动crash造成的损失要远远大得多。正常来说,如果有足够强健的构建发布系统,大多数时候能在版本上线之前及时发现问题并且修复,但是仍然存在小概率的线上意外。启动crash一般同时具备损害严重以及难以捕获两大特点
启动过程
从应用图标被用户点击开始,直到应用可以开始响应发生了很多事情。正常来说,尽管我们希望crash监控工具启动的尽可能早,但接入方往往总是等到launch事件之后才能启动工具,而在这个时间之前发生的崩溃就是启动crash,下面列出了在应用直到launch时,存在的可能发生启动crash的阶段:
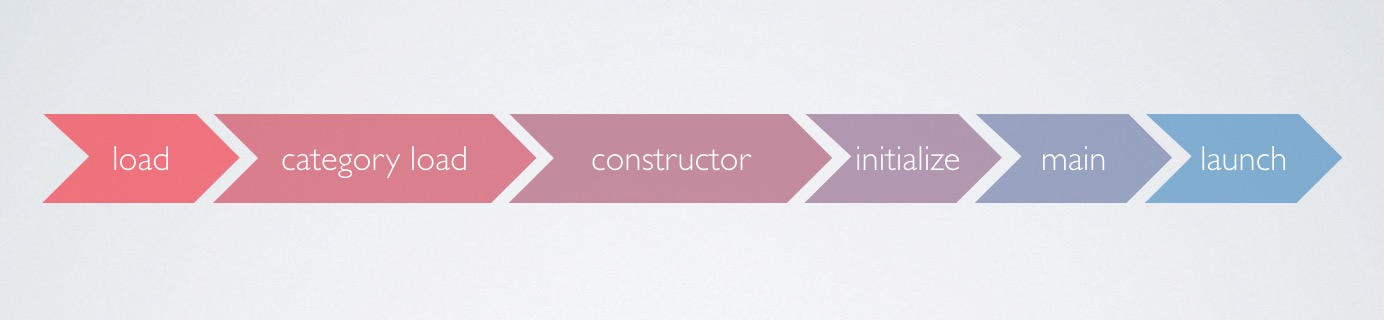
其中initialize的顺序可能在更早,但总是会在load和launch之间。从图中来说,如果我们想要监控启动crash,那么开始监控的时间点必须要放到load阶段,才能保证最好的监控效果
如何监控
最简单的方式是不管接入方愿不愿意启动crash监控,我们在load方法中直接启动监控功能。但是这样的做法会让应用面临四个风险点:
- 类似A/B的线上开关方案失去了对监控工具的控制能力
- crash监控启动存在崩溃问题,这将导致应用完全瘫痪
- load阶段类未加载完毕,启动工具过程的递归加载引发的崩溃无法监控
综合这些风险点,启动crash监控的方案应该满足这些条件:
- 启动过程不依赖类,避免递归加载造成的crash
- 一旦过程发生crash,能够保证日志记录的安全性
最终得出监控的流程图:
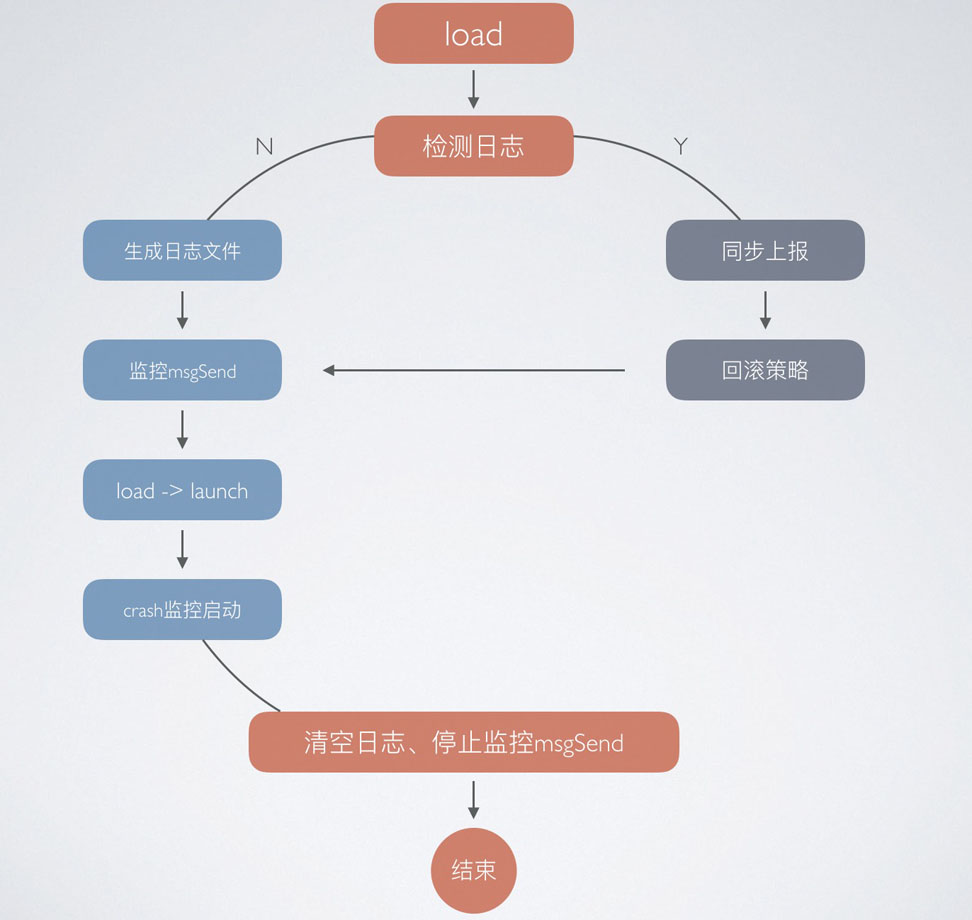
不依赖类
不依赖类意味着监控工具需要使用C接口来实现功能,虽然比较麻烦,但由于runtime的机制决定了所有方法调用最终要以objc_msgSend函数作为入口,因此如果能够hook掉这个函数并且实现一个调用栈结构,将所有调用入栈记录,那么追踪方法调用就不是难事。fishhook提供了hook掉函数的能力:
__unused static id (*orig_objc_msgSend)(id, SEL, ...);
__attribute__((__naked__)) static void hook_Objc_msgSend() {
/// save stack data
/// push msgSend
/// resume stack data
/// call origin msgSend
/// save stack data
/// pop msgSend
/// resume stack data
}
void observe_Objc_msgSend() {
struct rebinding msgSend_rebinding = { "objc_msgSend", hook_Objc_msgSend, (void *)&orig_objc_msgSend };
rebind_symbols((struct rebinding[1]){msgSend_rebinding}, 1);
}
实现msgSend
__naked__修饰的函数告诉编译器在函数调用的时候不使用栈保存参数信息,同时函数返回地址会被保存到LR寄存器上。由于msgSend本身就是用这个修饰符的,因此在记录函数调用的出入栈操作中,必须保证能够保存以及还原寄存器数据。msgSend利用x0 - x9的寄存器存储参数信息,可以手动使用sp寄存器来存储和还原这些参数信息:
/// 保存寄存器参数信息
#define save() \
__asm volatile ( \
"stp x8, x9, [sp, #-16]!\n" \
"stp x6, x7, [sp, #-16]!\n" \
"stp x4, x5, [sp, #-16]!\n" \
"stp x2, x3, [sp, #-16]!\n" \
"stp x0, x1, [sp, #-16]!\n");
/// 还原寄存器参数信息
#define resume() \
__asm volatile ( \
"ldp x0, x1, [sp], #16\n" \
"ldp x2, x3, [sp], #16\n" \
"ldp x4, x5, [sp], #16\n" \
"ldp x6, x7, [sp], #16\n" \
"ldp x8, x9, [sp], #16\n" );
/// 函数调用,value传入函数地址
#define call(b, value) \
__asm volatile ("stp x8, x9, [sp, #-16]!\n"); \
__asm volatile ("mov x12, %0\n" :: "r"(value)); \
__asm volatile ("ldp x8, x9, [sp], #16\n"); \
__asm volatile (#b " x12\n");
/// msgSend必须使用汇编实现
__attribute__((__naked__)) static void hook_Objc_msgSend() {
save()
__asm volatile ("mov x2, lr\n");
__asm volatile ("mov x3, x4\n");
call(blr, &push_msgSend)
resume()
call(blr, orig_objc_msgSend)
save()
call(blr, &pop_msgSend)
__asm volatile ("mov lr, x0\n");
resume()
__asm volatile ("ret\n");
}
日志记录
常规的I/O处理不能保证crash发生的数据安全,因此mmap是最适合用于此场景的方案。mmap能保证即便是应用发生了不可抗拒的崩溃时,也能完成将文件写入IO的工作。另外我们只需记录class和selector的调用栈信息,在不存在递归算法的情况下,只需要很小的内存使用就能记录这些数据:
time_t ts = time(NULL); const char *filePath = [NSSearchPathForDirectoriesInDomains(NSDocumentDirectory, NSUserDomainMask, YES).lastObject stringByAppendingString: [NSString stringWithFormat: @"%d", ts]].UTF8String; unsigned char *buffer = NULL; int fileDescriptor = open(filePath, O_RDWR, 0); buffer = (unsigned char *)mmap(NULL, MB * 4, PROT_READ|PROT_WRITE, MAP_FILE|MAP_SHARED, fileDescriptor, 0);
buffer就是我们写入数据的缓冲区,为了保证调用栈的信息准确,每次调用函数信息出入栈的时候,都需要更新缓冲区的数据。一个可行的方式是每个调用记录添加一个@符号前缀,总是保存最后一个调用记录的此符号下标,出栈时清除该下标之后的所有数据即可
static inline void push_msgSend(id _self, Class _cls, SEL _cmd, uintptr_t lr) {
_lastIdx = _length;
buffer[_lastIdx] = '@';
......
}
static inline void pop_msgSend(id _self, SEL _cmd, uintptr_t lr) {
......
buffer[_lastIdx] = '\0';
_length = _lastIdx;
size_t idx = _lastIdx - 1;
while (idx >= 0) {
if (buffer[idx] == '@') {
_lastIdx = idx;
break;
}
idx--;
}
}
清空日志
由于msgSend的调用非常频繁,这种监控方案并不适合长时间启动,因此需要在某个时机关闭监控。由于正常的崩溃监控启动时也可能会存在crash,监听becomeActive通知来关闭功能是最合适的选择,因为此时已经过了launch启动崩溃监控工具的阶段,可以保证该工具本身是正常使用的:
[[NSNotificationCenter defaultCenter] addObserver: self selector: @selector(closeMsgSendObserve) name: UIApplicationDidBecomeActiveNotification object: nil];
- (void)closeMsgSendObserve {
close(fileDescriptor);
munmap(buffer, MB * 4);
[[NSFileManager defaultManager] removeItemAtPath: _logPath error: nil];
}
回滚
当需要回滚时,说明已经发生了启动crash,此时根据日志内容,也有不同的处理方式:
日志文件是空文件
这种情况是最危险的情况,如果日志文件为空,说明文件已经建立,但是还没有产生任何方法调用。很有可能在fishhook的处理过程中存在crash,此时应该直接关闭监控方案,即便不是它的原因,并且快速增发版本
日志文件不为空
如果日志文件不为空,说明成功的监控到了crash,此时应该同步上传日志文件,快速反馈到业务方及时止损。首先止损手段都应该采用同步的方式,保证应用能够继续运行,根据情况不同,止损的回滚方式包括以下:
- 如果crash发生在并不干扰正常业务执行的功能组件中,可以通过A/B线上开关关闭对应的功能,前提是功能组件使用开关控制
- 崩溃处代码已经干扰正常业务执行,但是错误代码短,可以尝试通过服务器下发patch包动态修复错误代码,但是patch包要提防引入其他问题
- 在A/B Test和patch包都无法解决问题的情况下,假如项目采用了合理的组件化设计,通过路由转发来使用h5完成应用的正常运行
- 缺少动态修复的手段且crash不干扰正常业务执行,考虑停止一切插件、辅助组件运行
- 缺少动态修复的手段,包括1, 2, 3的方案。可考虑通过第三方越狱市场提供逆向包,提示用户下载安装
- 缺少动态修复的手段,包括1, 2, 3的方案。增发版本快速止损,使用Test Flight分批次快速让用户恢复使用
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,如果有疑问大家可以留言交流,谢谢大家对海外IDC网的支持。