
python实现跳表SkipList的示例代码
跳表
跳表,又叫做跳跃表、跳跃列表,在有序链表的基础上增加了“跳跃”的功能,由William Pugh于1990年发布,设计的初衷是为了取代平衡树(比如红黑树)。
Redis、LevelDB 都是著名的 Key-Value 数据库,而Redis中 的 SortedSet、LevelDB 中的 MemTable 都用到了跳表。
对比平衡树,跳表的实现和维护会更加简单,跳表的搜索、删除、添加的平均时间复杂度是 O(logn)。
跳表的结构如图所示:
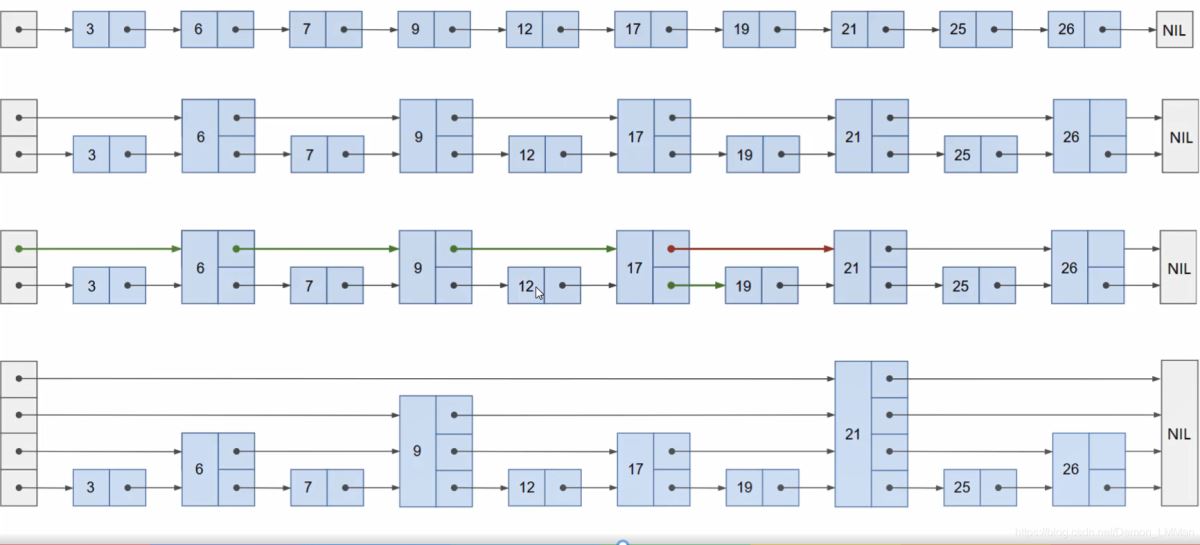
可以发现,对于一个节点Node,其含有多个next指针,不同索引的next分别代表不同层次的下一个节点,下次是节点类Node的python定义:
class Node():
def __init__(self,key,value,level):
'''
:param level:每个node对应的nexts层数不同
'''
self.key=key
self.value=value
self.nexts=[None]*level#节点类型next指针,初始值为空
def __str__(self):
#return "[key:"+str(self.key)+", value:"+str(self.value)+" len:"+str(len(self.nexts))+"]"
return "["+str(self.key)+","+str(self.value)+","+str(len(self.nexts))+"]"
关于添加、删除、查找见一下完整代码:
'''
跳表 Skip List ,其初衷是为了替代红黑树
'''
import random
import mkl_random
import time
class SkipList():
def __init__(self):
#头节点不存储任何数据
self.MAX_LEVEL = 32 # 最大level层数
self.__first=SkipList.Node(None, None, self.MAX_LEVEL)#头节点
self.__level=0#实际的level层数
self.__size=0#Jiedian个数
self.__p=0.25#用于生成添加节点时的随机level
return
class Node():
def __init__(self,key,value,level):
'''
:param level:每个node对应的nexts层数不同
'''
self.key=key
self.value=value
self.nexts=[None]*level
def __str__(self):
#return "[key:"+str(self.key)+", value:"+str(self.value)+" len:"+str(len(self.nexts))+"]"
return "["+str(self.key)+","+str(self.value)+","+str(len(self.nexts))+"]"
def get(self,key):
'''
:param key:
:return: key对应的value
'''
self.keyCheck(key)
node=self.__first
for level in range(self.__level - 1,-1,-1):
#在该层查找,key大于节点的key向前查找
while node.nexts[level] and node.nexts[level].key<key:
node=node.nexts[level]
if node.nexts[level] and node.nexts[level].key==key:#相等则找到,否则向下寻找
return node.nexts[level].value
return None
def put(self,key,value):
'''
return:原来的value,原来不存在key则为空
'''
self.keyCheck(key)
prev=[None]*self.__level
node=self.__first
for i in range(self.__level - 1, -1, -1):
while node.nexts[i] and node.nexts[i].key<key:
node=node.nexts[i]
if node.nexts[i] and node.nexts[i].key==key:
oldValue=node.nexts[i].value
node.nexts[i].value=value
return oldValue
prev[i]=node#保存当前level小于key的node
newLevel=self.randomLevel()
newNode=SkipList.Node(key,value,newLevel)
for i in range(newLevel):
if i<self.__level:
newNode.nexts[i]=prev[i].nexts[i]
prev[i].nexts[i]=newNode
else:
self.__first.nexts[i]=newNode
self.__size+=1
self.__level=max(self.__level, newLevel)
return None
def remove(self,key):
'''
:return: 节点对应的value值,不存在则返回None
'''
self.keyCheck(key)
prev=[None]*self.__level
node=self.__first
flag=False#该节点是否被查找到
for i in range(self.__level - 1, -1, -1):
while node.nexts[i] and node.nexts[i].key<key:
node=node.nexts[i]
if node.nexts[i].key==key:
flag=True
prev[i]=node
if not flag:
return None
removedNode=node.nexts[0]#需要被删除的节点
for i in range(len(removedNode.nexts)):#该nexts一定小于等于prev的长度
prev[i].next[i]=removedNode.nexts[i]
self.__size-=1
newLevel=self.__level
while newLevel>0 and not self.__first.nexts[newLevel - 1]:
newLevel-=1
self.__level=newLevel
return removedNode.value
def keyCheck(self, key):
'''
限制传入key不能为空
'''
if key!=0 and not key:
raise AttributeError("key can not be None")
def size(self):
return self.__size
def isEmpty(self):
return self.__size == 0
def randomLevel(self):#生成一个随机的层数
level=1
while mkl_random.rand()<self.__p and level<self.MAX_LEVEL:
level+=1
return level
def __str__(self):
result=""
for i in range(self.__level - 1, -1, -1):
result+=str(i)
node = self.__first
while node.nexts[i]:
result+=str(node.nexts[i])
node=node.nexts[i]
result+='\n'
print("level:"+str(self.__level))
return result
def showFirst(self):
for item in self.__first.nexts:
print(item,end=' ')
print()
def timeCalculate(container, size:int):
begin=time.time()
for i in range(size):
if isinstance(container,dict):
container[i]= i * 3
else:
container.put(i, i * 3)
error_count = 0
for i in range(size):
if container.get(i) != i * 3:
#print("wrong " + str(i) + ":" + str(skipList.get(i)))
error_count+=1
end=time.time()
print(type(container))
print(f'error rate:{float(error_count) / size:0.5f}')
print(f'time cost:{float(end-begin)*1000:0.3f} ms')
if __name__=='__main__':
timeCalculate({},1000000)
timeCalculate(SkipList(),10000)
到此这篇关于python实现跳表SkipList的文章就介绍到这了,更多相关python 跳表SkipList内容请搜索hwidc以前的文章或继续浏览下面的相关文章希望大家以后多多支持hwidc!