
详解非极大值抑制算法之Python实现
目录
- 一、概述
- 二、NMS 在目标检测中的应用
- 2.1、人脸检测框重叠例子
- 2.2、目标检测 pipline
- 三、NMS 原理
- 3.1、重叠率(重叠区域面积比例IOU)阈值
- 3.2、代码示例
- 四、NMS loss
- 五、Soft-NMS
- 5.1、python代码实现
- 5.2、Caffe C++ 版实现
- 六、其它应用
一、概述
这里不讨论通用的NMS算法(参考论文《Efficient Non-Maximum Suppression》对1维和2维数据的NMS实现),而是用于目标检测中提取分数最高的窗口的。例如在行人检测中,滑动窗口经提取特征,经分类器分类识别后,每个窗口都会得到一个分数。但是滑动窗口会导致很多窗口与其他窗口存在包含或者大部分交叉的情况。这时就需要用到NMS来选取那些邻域里分数最高(是行人的概率最大),并且抑制那些分数低的窗口。
NMS在计算机视觉领域有着非常重要的应用,如视频目标跟踪、数据挖掘、3D重建、目标识别以及纹理分析等。
二、NMS 在目标检测中的应用
2.1、人脸检测框重叠例子

我们的目的就是要去除冗余的检测框,保留最好的一个.
有多种方式可以解决这个问题,Triggs et al. 建议使用Mean-Shift 算法,利用bbox的坐标和当前图片尺度的对数来检测bbox的多种模式.但效果可能并不如使用强分类器结合NMS的效果好.
2.2、目标检测 pipline
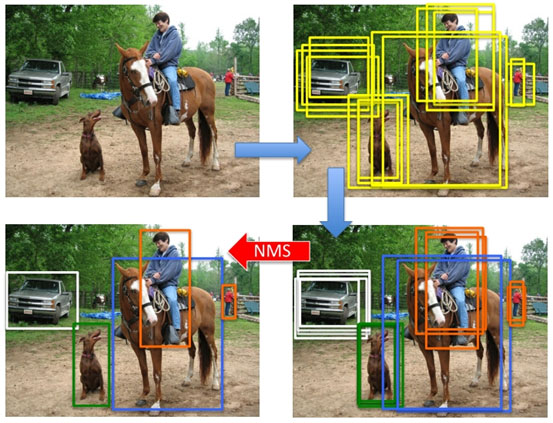
产生proposal后使用分类网络给出每个框的每类置信度,使用回归网络修正位置,最终应用NMS.
三、NMS 原理
对于Bounding Box的列表B及其对应的置信度S,采用下面的计算方式.选择具有最大score的检测框M,将其从B集合中移除并加入到最终的检测结果D中.通常将B中剩余检测框中与M的IoU大于阈值Nt的框从B中移除.重复这个过程,直到B为空.
3.1、重叠率(重叠区域面积比例IOU)阈值
常用的阈值是 0.3 ~ 0.5.
其中用到排序,可以按照右下角的坐标排序或者面积排序,也可以是通过SVM等分类器得到的得分或概率,R-CNN中就是按得分进行的排序.

就像上面的图片一样,定位一个车辆,最后算法就找出了一堆的方框,我们需要判别哪些矩形框是没用的。非极大值抑制的方法是:先假设有6个矩形框,根据分类器的类别分类概率做排序,假设从小到大属于车辆的概率 分别为A、B、C、D、E、F。
(1)从最大概率矩形框F开始,分别判断A~E与F的重叠度IOU是否大于某个设定的阈值;
(2)假设B、D与F的重叠度超过阈值,那么就扔掉B、D;并标记第一个矩形框F,是我们保留下来的。
(3)从剩下的矩形框A、C、E中,选择概率最大的E,然后判断E与A、C的重叠度,重叠度大于一定的阈值,那么就扔掉;并标记E是我们保留下来的第二个矩形框。
就这样一直重复,找到所有被保留下来的矩形框。
3.2、代码示例
在R-CNN中使用了NMS来确定最终的bbox,其对每个候选框送入分类器,根据分类器的类别分类概率做排序(论文中称为greedy-NMS).但其实也可以在分类之前运用简单版本的NMS来去除一些框.
python实现的单类别nms:py_cpu_nms.py.
def py_cpu_nms(dets, thresh): """Pure Python NMS baseline.""" #x1、y1、x2、y2、以及score赋值 x1 = dets[:, 0] y1 = dets[:, 1] x2 = dets[:, 2] y2 = dets[:, 3] scores = dets[:, 4] #每一个检测框的面积 areas = (x2 - x1 + 1) * (y2 - y1 + 1) #按照score置信度降序排序 order = scores.argsort()[::-1] keep = [] #保留的结果框集合 while order.size > 0: i = order[0] keep.append(i) #保留该类剩余box中得分最高的一个 #得到相交区域,左上及右下 xx1 = np.maximum(x1[i], x1[order[1:]]) yy1 = np.maximum(y1[i], y1[order[1:]]) xx2 = np.minimum(x2[i], x2[order[1:]]) yy2 = np.minimum(y2[i], y2[order[1:]]) #计算相交的面积,不重叠时面积为0 w = np.maximum(0.0, xx2 - xx1 + 1) h = np.maximum(0.0, yy2 - yy1 + 1) inter = w * h #计算IoU:重叠面积 /(面积1+面积2-重叠面积) ovr = inter / (areas[i] + areas[order[1:]] - inter) #保留IoU小于阈值的box inds = np.where(ovr <= thresh)[0] order = order[inds + 1] #因为ovr数组的长度比order数组少一个,所以这里要将所有下标后移一位 return keep
Faster R-CNN的MATLAB实现与python版实现一致,代码在这里:nms.m.另外,nms_multiclass.m是多类别nms,加了一层for循环对每类进行nms而已.
四、NMS loss
值的注意的是对多类别检测任务,如果对每类分别进行NMS,那么当检测结果中包含两个被分到不同类别的目标且其IoU较大时,会得到不可接受的结果。如下图所示:

一种改进方式便是在损失函数中加入一部分NMS损失。NMS损失可以定义为与分类损失相同:
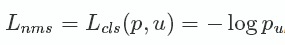
即真实列别u对应的log损失,p是C个类别的预测概率。实际相当于增加分类误差。
参考论文《Rotated Region Based CNN for Ship Detection》(IEEE2017会议论文)的Multi-task for NMS部分。
五、Soft-NMS
上述NMS算法的一个主要问题是当两个ground truth的目标的确重叠度很高时,NMS会将具有较低置信度的框去掉(置信度改成0),参见下图所示.
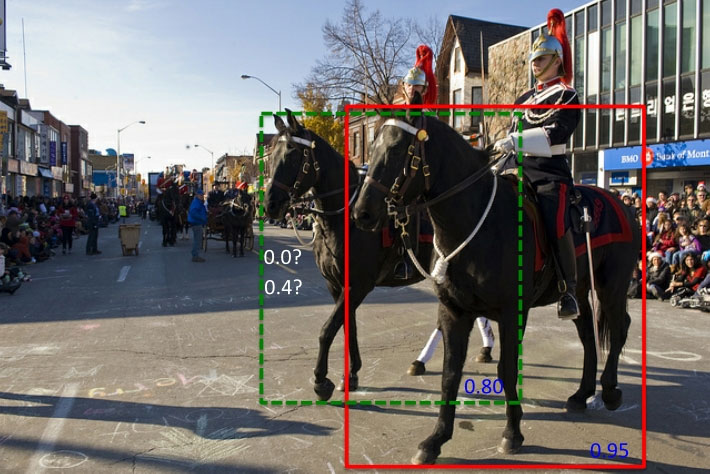
论文:《Improving Object Detection With One Line of Code》
改进之处:

改进方法在于将置信度改为IoU的函数:f(IoU),具有较低的值而不至于从排序列表中删去.
1.线性函数
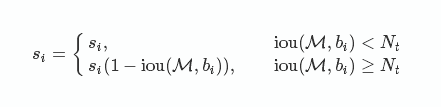
函数值不连续,在某一点的值发生跳跃.
2.高斯函数
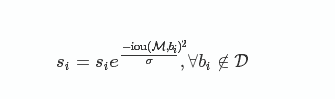
时间复杂度同传统的greedy-NMS,为
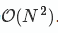
5.1、python代码实现
ua = float((tx2 - tx1 + 1) * (ty2 - ty1 + 1) + area - iw * ih) ov = iw * ih / ua #iou between max box and detection box if method == 1: # linear if ov > Nt: weight = 1 - ov else: weight = 1 elif method == 2: # gaussian weight = np.exp(-(ov * ov)/sigma) else: # original NMS if ov > Nt: weight = 0 else: weight = 1 # re-scoring 修改置信度 # boxes[pos, 4] = weight*boxes[pos, 4]
5.2、Caffe C++ 版实现
makefile/frcnn
效果
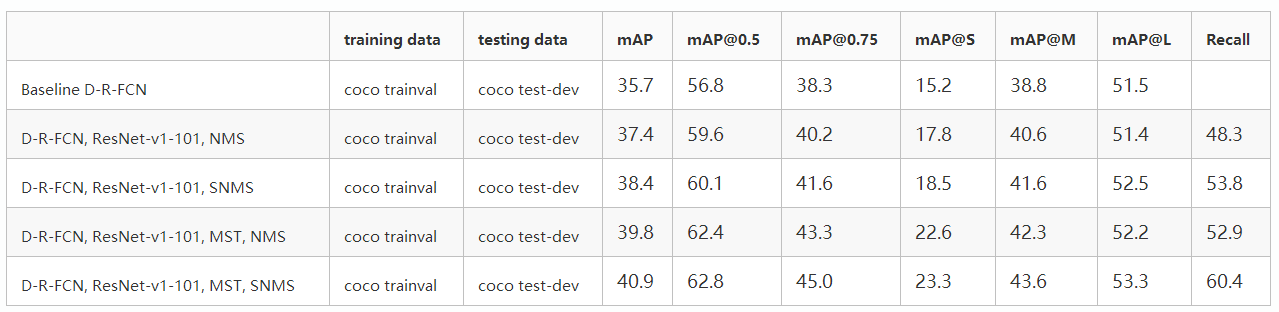
在基于proposal方法的模型结果上应用比较好,检测效果提升:

在R-FCN以及Faster-RCNN模型中的测试阶段运用Soft-NMS,在MS-COCO数据集上mAP@[0.5:0.95]能够获得大约1%的提升(详见这里). 如果应用到训练阶段的proposal选取过程理论上也能获得提升. 在自己的实验中发现确实对易重叠的目标类型有提高(目标不一定真的有像素上的重叠,切斜的目标的矩形边框会有较大的重叠).
而在SSD,YOLO等非proposal方法中没有提升.
六、其它应用
边缘检测:Canny算子中的非极大值抑制是沿着梯度方向进行的,即是否为梯度方向上的极值点;
特征点检测:在角点检测等场景下说的非极大值抑制,则是检测中心点处的值是否是某一个邻域内的最大值.
以上就是详解非极大值抑制算法之Python实现的详细内容,更多关于非极大值抑制 Python实现的资料请关注hwidc其它相关文章!
【文章原创作者:天门网站推广 提供,感恩】