
Python实现生活常识解答机器人
一、问答平台
这个「生活常识解答」机器人采用的是:阿里达摩院发布的语言模型PLUG(最近刚发布的,目前是测试阶段),地址链接如下:
https://nlp.aliyun.com/portal#/BigText_chinese

该模型参数规模达270亿,采用1TB以上高质量中文文本训练数据,包括了新闻、小说、诗歌、常识问答等类型。
先来看一下原页面效果
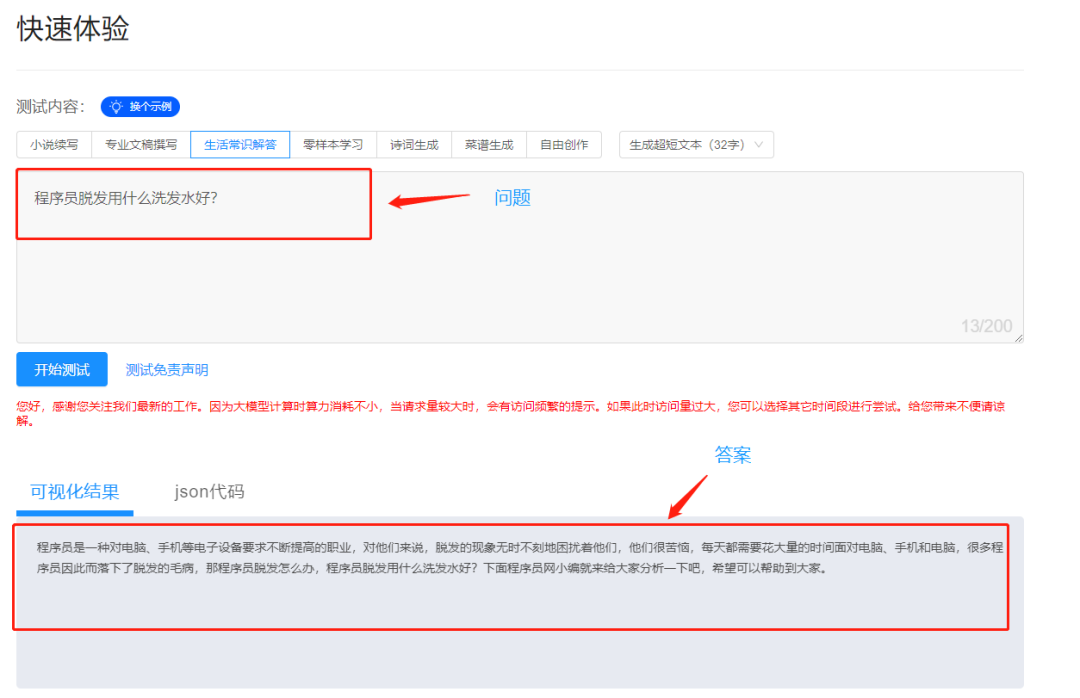
这里是需要登录阿里云账号,登录之后可以在网页进行测试问答!
因此我们下面将通过抓包方式获取这个问答的请求链接,然后在python代码中requests发送post请求去进行提问,然后返回结果(答案)。
二、抓包
在浏览器里面F12,点击network,然后点击一下提问,获取链接。
首先是发送的参数(提问)
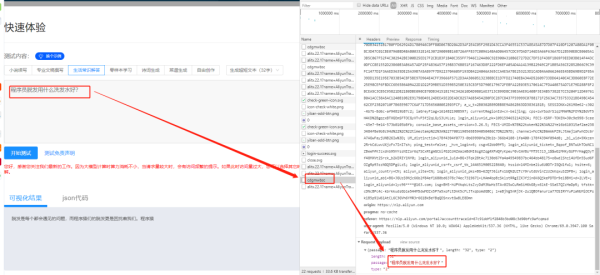
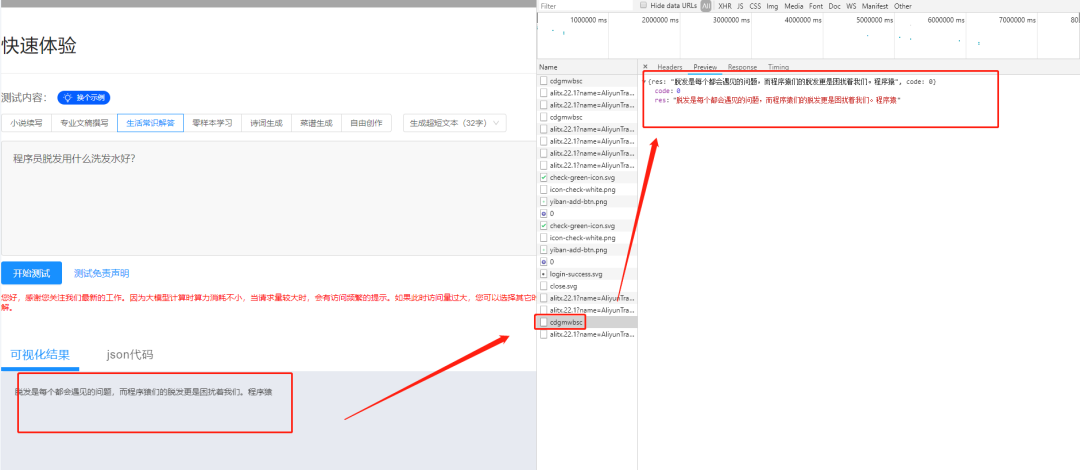
然后是返回的json数据
请求链接
https://nlp.aliyun.com/otherApi/yymx/cdgmwbsc
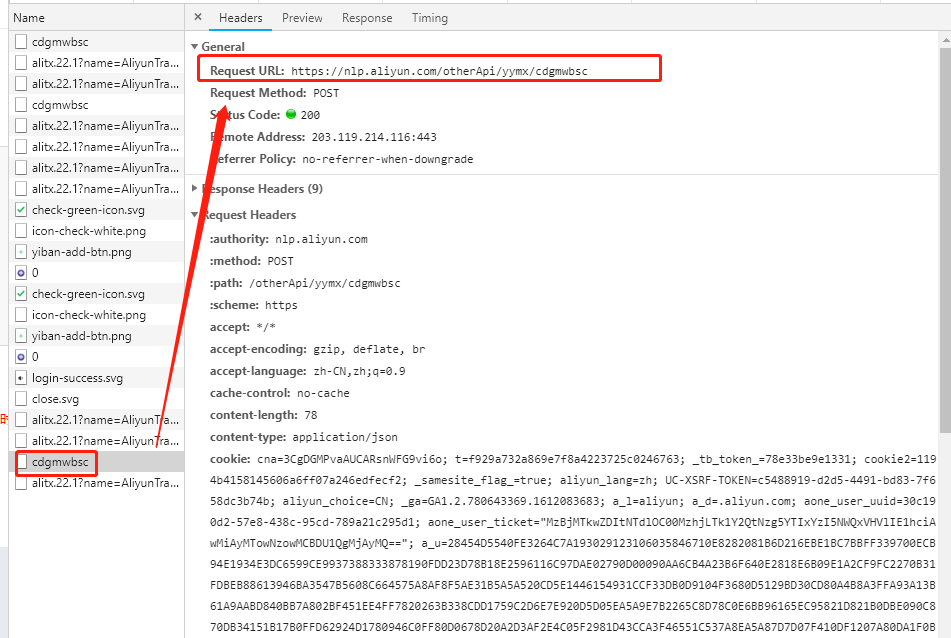
因此这个数据包的相关信息(请求链接,参数,返回结果)我们已经知道了,下面开始编写python代码
三、编写代码
首先是导入python库和请求头
import requests
import json
header={
'content-type':'application/json',
'cookie':'上面页面中你自己的cookie',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3947.100 Safari/537.36',
}
经过测试,有用的请求头参数是上面三个(content-type、cookie、User-Agent),缺一不可。
参数(其中q是问题,length是返回答案长度,type是对应常识问题)
q = "程序员脱发用什么洗发水好?"
data = {
'length':'128',
'type':'2',
'passage':q,
}
发送请求
url = "https://nlp.aliyun.com/otherApi/yymx/cdgmwbsc" text = requests.post(url,data = json.dumps(data),headers=header).json() print(text['res'])
返回结果

下面为了能够多轮提问,将请求部分代码放到循环中(如果输入是exit则退出循环)

四、小结
今天阿辰主要就教大家用Python爬虫去搭建一个「生活常识解答」机器人。
这个机器人主要是依托于“阿里达摩院发布的语言模型PLUG”,通过爬虫的方式,发送post请求(提问),然后返回json数据(回答)。轻松实现多轮提问。
到此这篇关于Python实现生活常识解答机器人的文章就介绍到这了,更多相关Python机器人内容请搜索hwidc以前的文章或继续浏览下面的相关文章希望大家以后多多支持hwidc!