
用python搭建一个花卉识别系统
目录
- 一.开源神经网络(AlexNet)
- 1.获取数据集
- 2.神经网络模型
- 3.训练神经网络
- 4.对模型进行预测
- 二、花卉识别系统搭建(flask)
- 1.构建页面:
- 2.调用神经网络模型
- 3.系统识别结果
- 4.启动系统:
- 三、总结
一.开源神经网络(AlexNet)
1.获取数据集
使用步骤如下:
* (1)在data_set文件夹下创建新文件夹"flower_data"
* (2)点击链接下载花分类数据集download.tensorflow.org/example\_im…
* (3)解压数据集到flower_data文件夹下
* (4)执行"split_data.py"脚本自动将数据集划分成训练集train和验证集val
split_data.py
import os
from shutil import copy, rmtree
import random
def mk_file(file_path: str):
if os.path.exists(file_path):
# 如果文件夹存在,则先删除原文件夹在重新创建
rmtree(file_path)
os.makedirs(file_path)
def main():
# 保证随机可复现
random.seed(0)
# 将数据集中10%的数据划分到验证集中
split_rate = 0.1
# 指向你解压后的flower_photos文件夹
cwd = os.getcwd()
data_root = os.path.join(cwd, "flower_data")
origin_flower_path = os.path.join(data_root, "flower_photos")
assert os.path.exists(origin_flower_path)
flower_class = [cla for cla in os.listdir(origin_flower_path)
if os.path.isdir(os.path.join(origin_flower_path, cla))]
# 建立保存训练集的文件夹
train_root = os.path.join(data_root, "train")
mk_file(train_root)
for cla in flower_class:
# 建立每个类别对应的文件夹
mk_file(os.path.join(train_root, cla))
# 建立保存验证集的文件夹
val_root = os.path.join(data_root, "val")
mk_file(val_root)
for cla in flower_class:
# 建立每个类别对应的文件夹
mk_file(os.path.join(val_root, cla))
for cla in flower_class:
cla_path = os.path.join(origin_flower_path, cla)
images = os.listdir(cla_path)
num = len(images)
# 随机采样验证集的索引
eval_index = random.sample(images, k=int(num*split_rate))
for index, image in enumerate(images):
if image in eval_index:
# 将分配至验证集中的文件复制到相应目录
image_path = os.path.join(cla_path, image)
new_path = os.path.join(val_root, cla)
copy(image_path, new_path)
else:
# 将分配至训练集中的文件复制到相应目录
image_path = os.path.join(cla_path, image)
new_path = os.path.join(train_root, cla)
copy(image_path, new_path)
print("\r[{}] processing [{}/{}]".format(cla, index+1, num), end="") # processing bar
print()
print("processing done!")
if __name__ == '__main__':
main()
2.神经网络模型
model.py
import torch.nn as nn
import torch
class AlexNet(nn.Module):
def __init__(self, num_classes=1000, init_weights=False):
super(AlexNet, self).__init__()
# 用nn.Sequential()将网络打包成一个模块,精简代码
self.features = nn.Sequential( # 卷积层提取图像特征
nn.Conv2d(3, 48, kernel_size=11, stride=4, padding=2), # input[3, 224, 224] output[48, 55, 55]
nn.ReLU(inplace=True), # 直接修改覆盖原值,节省运算内存
nn.MaxPool2d(kernel_size=3, stride=2), # output[48, 27, 27]
nn.Conv2d(48, 128, kernel_size=5, padding=2), # output[128, 27, 27]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 13, 13]
nn.Conv2d(128, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(192, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(192, 128, kernel_size=3, padding=1), # output[128, 13, 13]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 6, 6]
)
self.classifier = nn.Sequential( # 全连接层对图像分类
nn.Dropout(p=0.5), # Dropout 随机失活神经元,默认比例为0.5
nn.Linear(128 * 6 * 6, 2048),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(2048, 2048),
nn.ReLU(inplace=True),
nn.Linear(2048, num_classes),
)
if init_weights:
self._initialize_weights()
# 前向传播过程
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, start_dim=1) # 展平后再传入全连接层
x = self.classifier(x)
return x
# 网络权重初始化,实际上 pytorch 在构建网络时会自动初始化权重
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d): # 若是卷积层
nn.init.kaiming_normal_(m.weight, mode='fan_out', # 用(何)kaiming_normal_法初始化权重
nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0) # 初始化偏重为0
elif isinstance(m, nn.Linear): # 若是全连接层
nn.init.normal_(m.weight, 0, 0.01) # 正态分布初始化
nn.init.constant_(m.bias, 0) # 初始化偏重为0
3.训练神经网络
train.py
# 导入包
import torch
import torch.nn as nn
from torchvision import transforms, datasets, utils
import matplotlib.pyplot as plt
import numpy as np
import torch.optim as optim
from model import AlexNet
import os
import json
import time
# 使用GPU训练
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
with open(os.path.join("train.log"), "a") as log:
log.write(str(device)+"\n")
#数据预处理
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224), # 随机裁剪,再缩放成 224×224
transforms.RandomHorizontalFlip(p=0.5), # 水平方向随机翻转,概率为 0.5, 即一半的概率翻转, 一半的概率不翻转
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"val": transforms.Compose([transforms.Resize((224, 224)), # cannot 224, must (224, 224)
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}
#导入、加载 训练集
# 导入训练集
#train_set = torchvision.datasets.CIFAR10(root='./data', # 数据集存放目录
# train=True, # 表示是数据集中的训练集
# download=True, # 第一次运行时为True,下载数据集,下载完成后改为False
# transform=transform) # 预处理过程
# 加载训练集
#train_loader = torch.utils.data.DataLoader(train_set, # 导入的训练集
# batch_size=50, # 每批训练的样本数
# shuffle=False, # 是否打乱训练集
# num_workers=0) # num_workers在windows下设置为0
# 获取图像数据集的路径
data_root = os.path.abspath(os.path.join(os.getcwd(), "../..")) # get data root path 返回上上层目录
image_path = data_root + "/jqsj/data_set/flower_data/" # flower data_set path
# 导入训练集并进行预处理
train_dataset = datasets.ImageFolder(root=image_path + "/train",
transform=data_transform["train"])
train_num = len(train_dataset)
# 按batch_size分批次加载训练集
train_loader = torch.utils.data.DataLoader(train_dataset, # 导入的训练集
batch_size=32, # 每批训练的样本数
shuffle=True, # 是否打乱训练集
num_workers=0) # 使用线程数,在windows下设置为0
#导入、加载 验证集
# 导入验证集并进行预处理
validate_dataset = datasets.ImageFolder(root=image_path + "/val",
transform=data_transform["val"])
val_num = len(validate_dataset)
# 加载验证集
validate_loader = torch.utils.data.DataLoader(validate_dataset, # 导入的验证集
batch_size=32,
shuffle=True,
num_workers=0)
# 存储 索引:标签 的字典
# 字典,类别:索引 {'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4}
flower_list = train_dataset.class_to_idx
# 将 flower_list 中的 key 和 val 调换位置
cla_dict = dict((val, key) for key, val in flower_list.items())
# 将 cla_dict 写入 json 文件中
json_str = json.dumps(cla_dict, indent=4)
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
#训练过程
net = AlexNet(num_classes=5, init_weights=True) # 实例化网络(输出类型为5,初始化权重)
net.to(device) # 分配网络到指定的设备(GPU/CPU)训练
loss_function = nn.CrossEntropyLoss() # 交叉熵损失
optimizer = optim.Adam(net.parameters(), lr=0.0002) # 优化器(训练参数,学习率)
save_path = './AlexNet.pth'
best_acc = 0.0
for epoch in range(150):
########################################## train ###############################################
net.train() # 训练过程中开启 Dropout
running_loss = 0.0 # 每个 epoch 都会对 running_loss 清零
time_start = time.perf_counter() # 对训练一个 epoch 计时
for step, data in enumerate(train_loader, start=0): # 遍历训练集,step从0开始计算
images, labels = data # 获取训练集的图像和标签
optimizer.zero_grad() # 清除历史梯度
outputs = net(images.to(device)) # 正向传播
loss = loss_function(outputs, labels.to(device)) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 优化器更新参数
running_loss += loss.item()
# 打印训练进度(使训练过程可视化)
rate = (step + 1) / len(train_loader) # 当前进度 = 当前step / 训练一轮epoch所需总step
a = "*" * int(rate * 50)
b = "." * int((1 - rate) * 50)
with open(os.path.join("train.log"), "a") as log:
log.write(str("\rtrain loss: {:^3.0f}%[{}->{}]{:.3f}".format(int(rate * 100), a, b, loss))+"\n")
print("\rtrain loss: {:^3.0f}%[{}->{}]{:.3f}".format(int(rate * 100), a, b, loss), end="")
print()
with open(os.path.join("train.log"), "a") as log:
log.write(str('%f s' % (time.perf_counter()-time_start))+"\n")
print('%f s' % (time.perf_counter()-time_start))
########################################### validate ###########################################
net.eval() # 验证过程中关闭 Dropout
acc = 0.0
with torch.no_grad():
for val_data in validate_loader:
val_images, val_labels = val_data
outputs = net(val_images.to(device))
predict_y = torch.max(outputs, dim=1)[1] # 以output中值最大位置对应的索引(标签)作为预测输出
acc += (predict_y == val_labels.to(device)).sum().item()
val_accurate = acc / val_num
# 保存准确率最高的那次网络参数
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net.state_dict(), save_path)
with open(os.path.join("train.log"), "a") as log:
log.write(str('[epoch %d] train_loss: %.3f test_accuracy: %.3f \n' %
(epoch + 1, running_loss / step, val_accurate))+"\n")
print('[epoch %d] train_loss: %.3f test_accuracy: %.3f \n' %
(epoch + 1, running_loss / step, val_accurate))
with open(os.path.join("train.log"), "a") as log:
log.write(str('Finished Training')+"\n")
print('Finished Training')
训练结果后,准确率是94%
训练日志如下:

4.对模型进行预测
predict.py
import torch
接着对其中一个花卉图片进行识别,其结果如下:

可以看到只有一个识别结果(daisy雏菊)和准确率1.0是100%(范围是0~1,所以1对应100%)
为了方便使用这个神经网络,接着我们将其开发成一个可视化的界面操作
二、花卉识别系统搭建(flask)
1.构建页面:
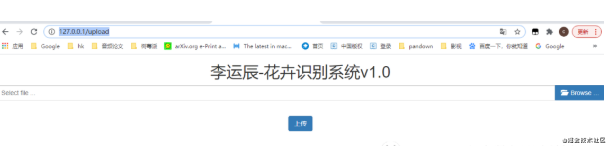
2.调用神经网络模型
main.py
# coding:utf-8
from flask import Flask, render_template, request, redirect, url_for, make_response, jsonify
from werkzeug.utils import secure_filename
import os
import time
###################
#模型所需库包
import torch
from model import AlexNet
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
import json
# read class_indict
try:
json_file = open('./class_indices.json', 'r')
class_indict = json.load(json_file)
except Exception as e:
print(e)
exit(-1)
# create model
model = AlexNet(num_classes=5)
# load model weights
model_weight_path = "./AlexNet.pth"
#, map_location='cpu'
model.load_state_dict(torch.load(model_weight_path, map_location='cpu'))
# 关闭 Dropout
model.eval()
###################
from datetime import timedelta
# 设置允许的文件格式
ALLOWED_EXTENSIONS = set(['png', 'jpg', 'JPG', 'PNG', 'bmp'])
def allowed_file(filename):
return '.' in filename and filename.rsplit('.', 1)[1] in ALLOWED_EXTENSIONS
app = Flask(__name__)
# 设置静态文件缓存过期时间
app.send_file_max_age_default = timedelta(seconds=1)
#图片装换操作
def tran(img_path):
# 预处理
data_transform = transforms.Compose(
[transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# load image
img = Image.open("pgy2.jpg")
#plt.imshow(img)
# [N, C, H, W]
img = data_transform(img)
# expand batch dimension
img = torch.unsqueeze(img, dim=0)
return img
@app.route('/upload', methods=['POST', 'GET']) # 添加路由
def upload():
path=""
if request.method == 'POST':
f = request.files['file']
if not (f and allowed_file(f.filename)):
return jsonify({"error": 1001, "msg": "请检查上传的图片类型,仅限于png、PNG、jpg、JPG、bmp"})
basepath = os.path.dirname(__file__) # 当前文件所在路径
path = secure_filename(f.filename)
upload_path = os.path.join(basepath, 'static/images', secure_filename(f.filename)) # 注意:没有的文件夹一定要先创建,不然会提示没有该路径
# upload_path = os.path.join(basepath, 'static/images','test.jpg') #注意:没有的文件夹一定要先创建,不然会提示没有该路径
print(path)
img = tran('static/images'+path)
##########################
#预测图片
with torch.no_grad():
# predict class
output = torch.squeeze(model(img)) # 将输出压缩,即压缩掉 batch 这个维度
predict = torch.softmax(output, dim=0)
predict_cla = torch.argmax(predict).numpy()
res = class_indict[str(predict_cla)]
pred = predict[predict_cla].item()
#print(class_indict[str(predict_cla)], predict[predict_cla].item())
res_chinese = ""
if res=="daisy":
res_chinese="雏菊"
if res=="dandelion":
res_chinese="蒲公英"
if res=="roses":
res_chinese="玫瑰"
if res=="sunflower":
res_chinese="向日葵"
if res=="tulips":
res_chinese="郁金香"
#print('result:', class_indict[str(predict_class)], 'accuracy:', prediction[predict_class])
##########################
f.save(upload_path)
pred = pred*100
return render_template('upload_ok.html', path=path, res_chinese=res_chinese,pred = pred, val1=time.time())
return render_template('upload.html')
if __name__ == '__main__':
# app.debug = True
app.run(host='127.0.0.1', port=80,debug = True)
3.系统识别结果
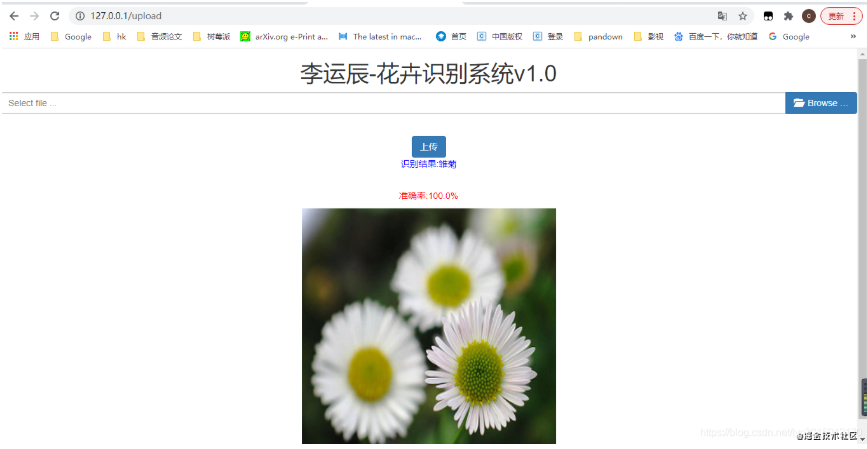
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>李运辰-花卉识别系统v1.0</title>
<link rel="stylesheet" type="text/css" href="../static/css/bootstrap.min.css" rel="external nofollow" >
<link rel="stylesheet" type="text/css" href="../static/css/fileinput.css" rel="external nofollow" >
<script src="../static/js/jquery-2.1.4.min.js"></script>
<script src="../static/js/bootstrap.min.js"></script>
<script src="../static/js/fileinput.js"></script>
<script src="../static/js/locales/zh.js"></script>
</head>
<body>
<h1 align="center">李运辰-花卉识别系统v1.0</h1>
<div align="center">
<form action="" enctype='multipart/form-data' method='POST'>
<input type="file" name="file" class="file" data-show-preview="false" style="margin-top:20px;"/>
<br>
<input type="submit" value="上传" class="button-new btn btn-primary" style="margin-top:15px;"/>
</form>
<p style="size:15px;color:blue;">识别结果:{{res_chinese}}</p>
</br>
<p style="size:15px;color:red;">准确率:{{pred}}%</p>
<img src="{{ './static/images/'+path }}" width="400" height="400" alt=""/>
</div>
</body>
</html>
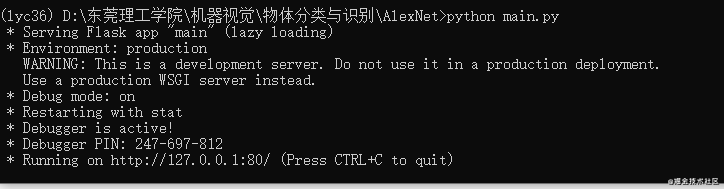
4.启动系统:
python main.py
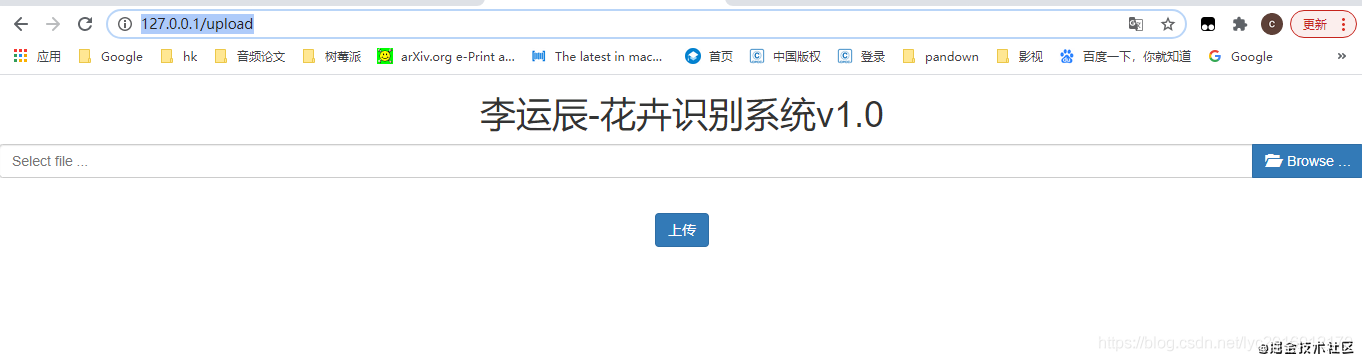
接着在浏览器在浏览器里面访问
http://127.0.0.1/upload
出现如下界面:
最后来一个识别过程的动图

三、总结
ok,这个花卉系统就已经搭建完成了,是不是超级简单,我也是趁着修了这个机器视觉这么课,才弄这么一个系统,回顾一下之前的知识,哈哈哈。
以上就是用python搭建一个花卉识别系统的详细内容,更多关于python 花卉识别系统的资料请关注hwidc其它相关文章!