
python csv一些基本操作总结
一、读取数据
csv.reader
csv.reader传入的可以是列表或者文件对象,返回的是一个可迭代的对象,需要使用for循环遍历
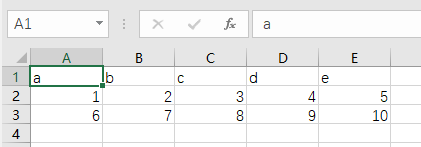
path = "C:\\Users\\A539\\Desktop\\1.csv"
with open(path, 'r') as fp:
lines = csv.reader(fp)
for line in lines:
print(line)
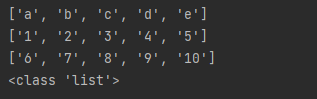
print(type(line))
line的格式为list
二、写入数据
csv.writer
将一个列表写入csv文件
list1 = [100, 200, 300, 400, 500]
list2 = [[500, 600, 700, 800, 900],
[50, 60, 70, 80, 90]]
with open(path, 'w',newline='')as fp:
writer = csv.writer(fp)
# 写入一行
writer.writerow(list1)
# 写入多行
writer.writerows(list2)
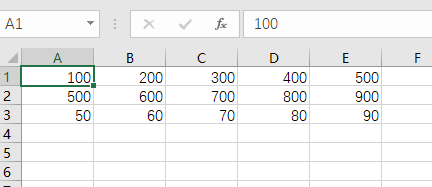
不加newline = ''会导致每行之间有一行空行
csv.DictWriter
写入字典
head = ['aa', 'bb', 'cc', 'dd', 'ee']
lines = [
{'aa': 10 , 'bb': 20, 'cc': 30, 'dd': 40, 'ee': 50},
{'aa': 100, 'bb': 200, 'cc': 300, 'dd': 400, 'ee': 500},
{'aa': 1000, 'bb': 2000, 'cc': 3000, 'dd': 4000, 'ee': 5000},
{'aa': 10000, 'bb': 20000, 'cc': 30000, 'dd': 40000, 'ee': 50000},
]
with open(path, 'w',newline='')as fp:
dictwriter = csv.DictWriter(fp, head)
dictwriter.writeheader()
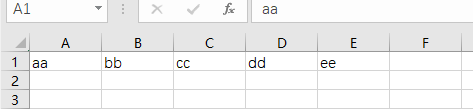
with open(path, 'w', newline='')as fp:
dictwriter = csv.DictWriter(fp, head)
dictwriter.writeheader()
dictwriter.writerows(lines)
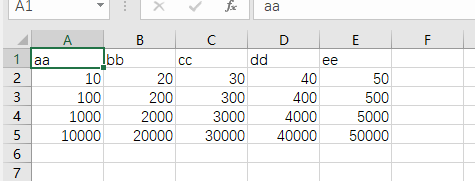
不覆盖原有内容写入
上述的写入都会覆盖原有的内容,要想保存之前的内容,将新内容附加到后面,只需要更改标志为'a+'
with open(path, 'a+', newline='')as fp:
dictwriter = csv.DictWriter(fp, head)
dictwriter.writeheader()
dictwriter.writerows(lines)
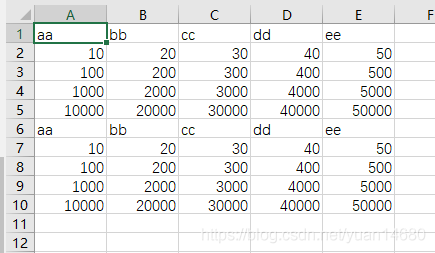
附
https://docs.python.org/2/library/csv.html#module-csv.
参考
csv模块的使用
到此这篇关于python csv一些基本操作总结的文章就介绍到这了,更多相关csv基本操作内容请搜索hwidc以前的文章或继续浏览下面的相关文章希望大家以后多多支持hwidc!