
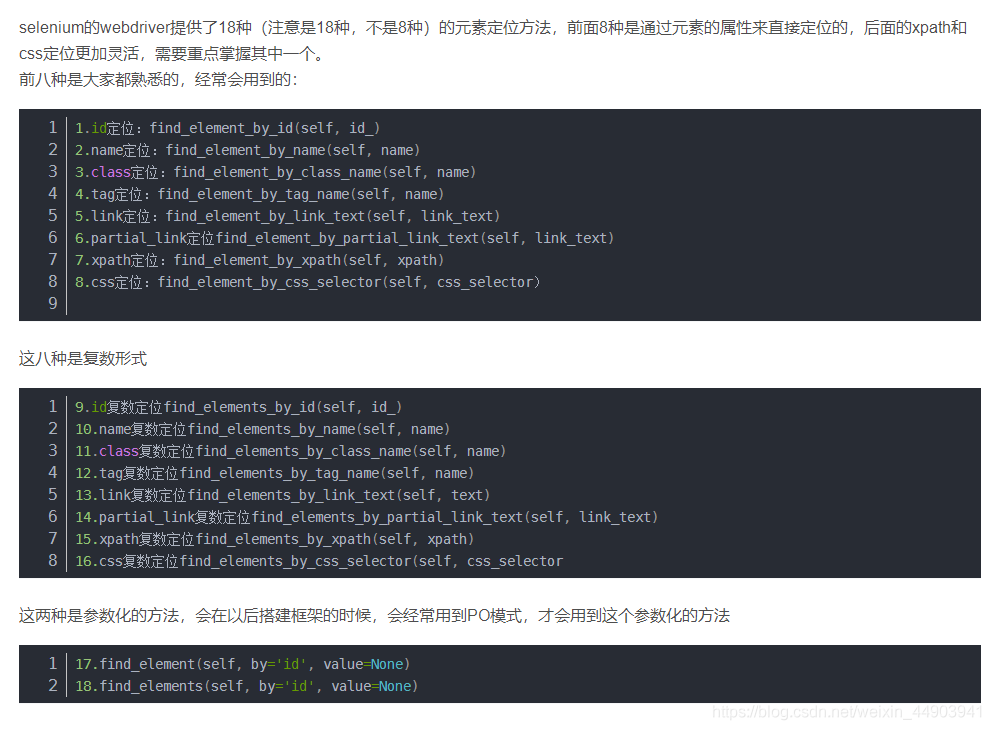
详解Python自动化中这八大元素定位
一、find_element_by_id()
find_element_by_id()
1.从上面定位到的元素属性中,可以看到有个id属性:id=“kw”,这里可以通过它的id属性定位到这个元素。
2.定位到搜索框后,用send_keys()方法,就可以输入文本。
from selenium import webdriver
driver = webdriver.Firefox()
driver.get("http://www.baidu.com")
# 通过id定位百度输入框,并输入'python'
ss = driver.find_element_by_id('kw')
ss.send_keys('python')
二、find_element_by_name()
find_element_by_name()
1.从上面定位到的元素属性中,可以看到有个name属性:name=“wd”,这里可以通过它的name属性单位到这个元素。
说明:这里运行后会报错,说明这个搜索框的name属性不是唯一的,无法通过name属性直接定位到输入框
from selenium import webdriver
driver = webdriver.Firefox()
driver.get("http://www.baidu.com")
# 通过name定位百度输入框,并输入'python'
ss = driver.find_element_by_name('wd')
ss.send_keys('python')
三、find_element_by_class_name()
find_element_by_class_name()
1.从上面定位到的元素属性中,可以看到有个class属性:class=“s_ipt”,这里可以通过它的class属性定位到这个元素。
from selenium import webdriver
driver = webdriver.Firefox()
driver.get('http://www.baidu.com')
#通过class定位百度输入框,并输入'python'
driver.find_element_by_class_name('s_ipt').send_keys('python')
四、find_element_by_tag_name()
find_element_by_tag_name()
1.从上面定位到的元素属性中,可以看到每个元素都有tag(标签)属性,如搜索框的标签属性,就是最前面的input。
2.很明显,在一个页面中,相同的标签有很多,所以一般不用标签来定位。以下例子,仅供参考和理解,运行肯定报错。
from selenium import webdriver
driver = webdriver.Firefox()
driver.get('http://www.baidu.com')
#通过tag(标签)定位百度输入框,并输入'python'
ss = driver.find_element_by_tag_name('input')
ss.send_keys('python')
五、find_element_by_link_text()
1.定位百度页面上"hao123"这个按钮
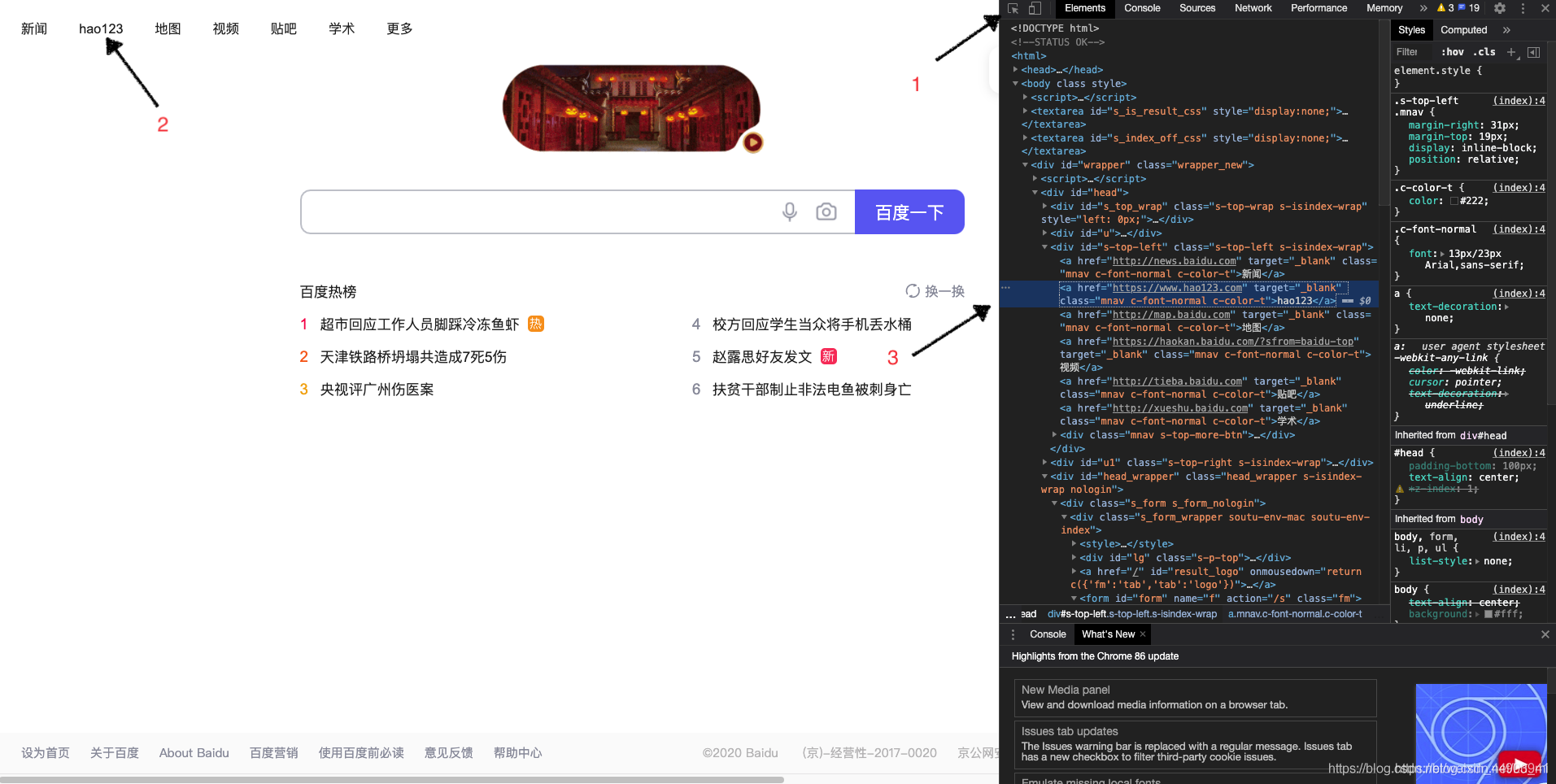
查看页面元素:
<a class="mnav" target="_blank" href="http://www.hao123.com" rel="external nofollow" >hao123</a>
2.从元素属性可以分析出,有个href = "http://www.hao123.com
说明它是个超链接,对于这种元素,可以用以下方法:
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('http://www.baidu.com')
#通过tlink(超链接)定位百度输入框,并点击
driver.find_element_by_link_name('hao123').click()
六、find_element_by_partial_link_text()
1.有时候一个超链接它的字符串可能比较长,如果输入全称的话,会显示很长,这时候可以用一模糊匹配方式,截取其中一部分字符串就可以了
2.如“hao123”,只需输入“ao123”也可以定位到
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('http://www.baidu.com')
#通过partial_link定位百度输入框,并点击(partial_link是一种模糊匹配的方式)
driver.find_element_by_partial_link_name('hao123').click()
七、find_element_by_xpath()
1.以上定位方式都是通过元素的某个属性来定位的,如果一个元素它既没有id、name、class属性也不是超链接,这么办呢?或者说它的属性很多重复的。这个时候就可以用xpath解决。
2.xpath是一种路径语言,跟上面的定位原理不太一样,首先第一步要先学会查看一个元素的xpath。
- 对于谷歌浏览器来说,有自己 的xpath解析工具:鼠标移到需要查看的html源码上,右击
- 选择copy
- copy xpath,就是源码的xpath路径
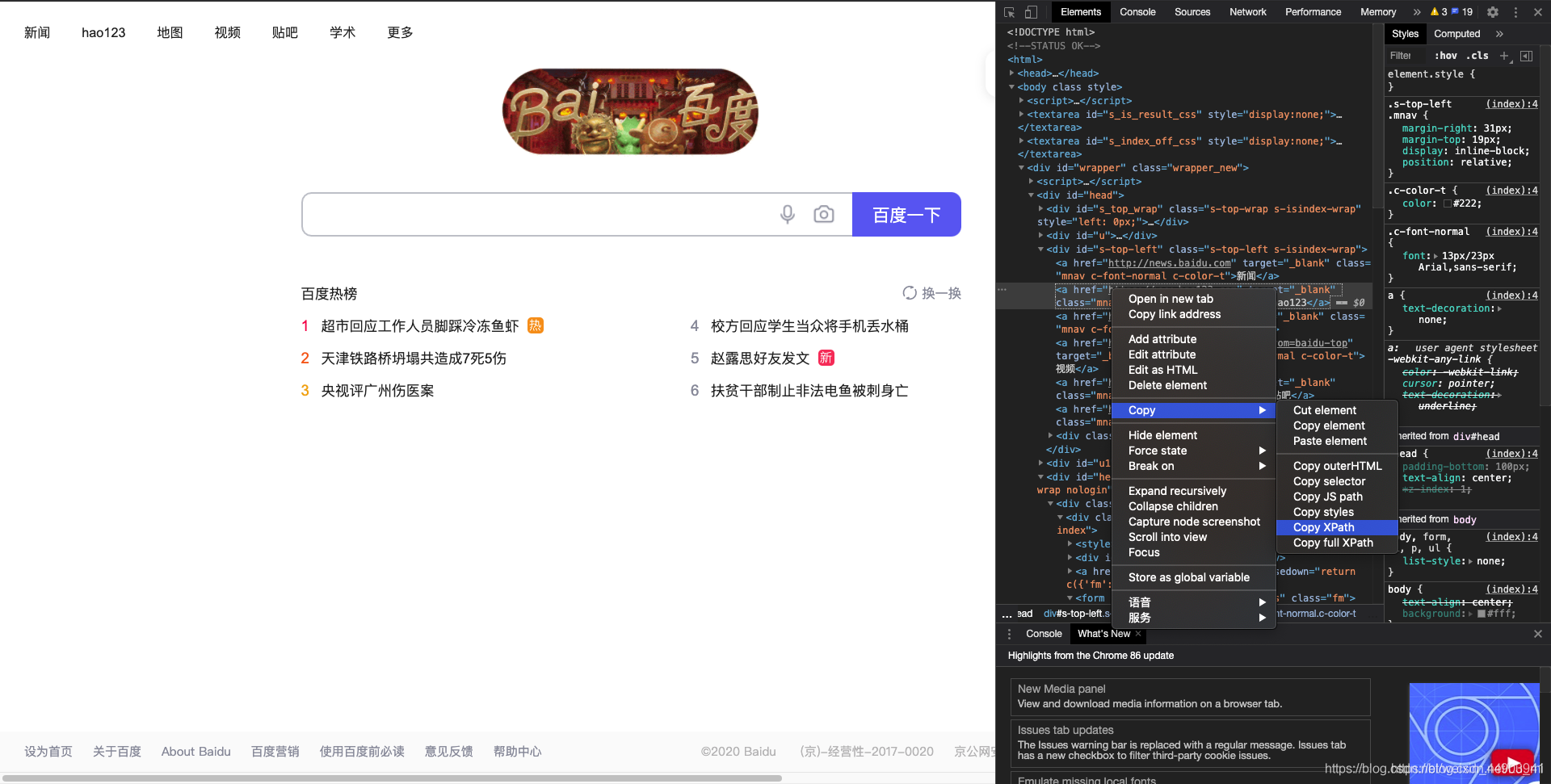
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('http://www.baidu.com')
#通过xpath地址定位百度输入框,并点击(xpath地址即为赋值过来的地址)
driver.find_element_by_xpath('//*[@id="s-top-left"]/a[2]').click()
八、find_element_by_css_selector()
1.css是另外一种语法,比xpath更为简洁,但是不太好理解。这里先学会如何用工具查看,后续的教程再深入讲解
- 对于谷歌浏览器来说,同样有自己 的css解析工具:鼠标移到需要查看的html源码上,右击
- 选择copy
- copy selector,就是源码的css路径
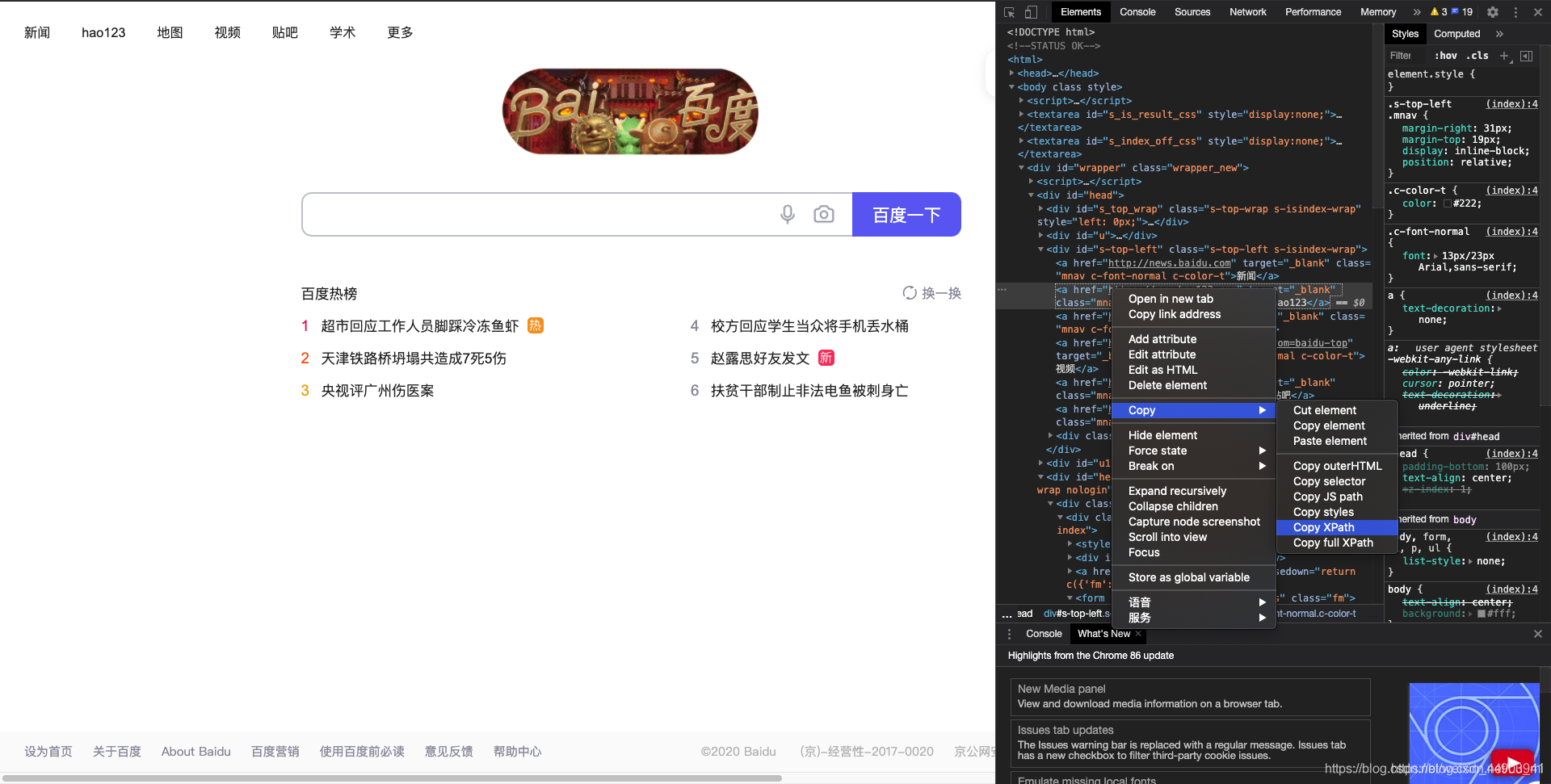
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('http://www.baidu.com')
#通过css地址定位百度输入框,并点击
driver.find_element_by_xpath('#s-top-left > a:nth-child(2)').click()
总结:
到此这篇关于详解Python自动化中这八大元素定位的文章就介绍到这了,更多相关Python元素定位内容请搜索hwidc以前的文章或继续浏览下面的相关文章希望大家以后多多支持hwidc!