
Python数据分析之pandas读取数据
一、三种数据文件的读取

二、csv、tsv、txt 文件读取
1)CSV文件读取:
语法格式:pandas.read_csv(文件路径)
CSV文件内容如下:
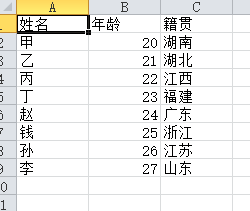
import pandas as pd file_path = "e:\\pandas_study\\test.csv" content = pd.read_csv(file_path) content.head() # 默认返回前5行数据 content.head(3) # 返回前3行数据 content.shape # 返回一个元组(总行数,总列数),总行数不包括标题行 content.index # 返回索引,是一个可迭代的对象<class 'pandas.core.indexes.range.RangeIndex'> content.column # 返回所有的列名 Index(['姓名', '年龄', '籍贯'], dtype='object') content.dtypes # 返回的是每列的数据类型 姓名 object 年龄 int64 籍贯 object dtype: object
2)CSV文件读取:
语法格式:pandas.read_csv(文件路径)
CSV文件内容如下:
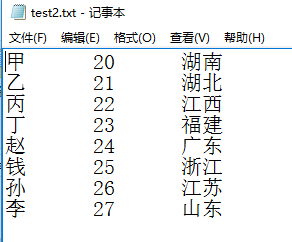
import pandas as pd file_path = "e:\\pandas_study\\test2.txt" content = pd.read_csv(file_path,sep='\t',header = None ,names= ['name','age','adress']) #参数说明: # header = None 表示没有标题行 # sep='\t' 表示去除分割符中的空格 # names= ['name','age','adress'] ,列名依次自定义为'name','age','adress' content.head() # 默认返回前5行数据 content.head(3) # 返回前3行数据 content.shape # 返回一个元组(总行数,总列数),总行数不包括标题行 content.index # 返回索引,是一个可迭代的对象<class 'pandas.core.indexes.range.RangeIndex'> content.column # 返回所有的列名 Index(['姓名', '年龄', '籍贯'], dtype='object') content.dtypes # 返回的是每列的数据类型
三、excel文件读取
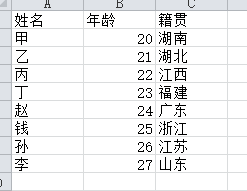
import pandas as pd file_path = "e:\\pandas_study\\test3.xlsx" content = pd.read_excel(file_path) content.head() # 默认返回前5行数据 content.head(3) # 返回前3行数据 content.shape # 返回一个元组(总行数,总列数),总行数不包括标题行 content.index # 返回索引,是一个可迭代的对象<class 'pandas.core.indexes.range.RangeIndex'> content.column # 返回所有的列名 Index(['姓名', '年龄', '籍贯'], dtype='object') content.dtypes # 返回的是每列的数据类型 姓名 object 年龄 int64 籍贯 object dtype: object
四、数据库表格读取
语法: pandas.read_sql(sql语句,数据库连接对象)
数据对象的创建,可以根据pymysql,cx_oracle等模块连接mysql或者oracle。
到此这篇关于Python数据分析之pandas读取数据的文章就介绍到这了,更多相关pandas读取数据内容请搜索hwidc以前的文章或继续浏览下面的相关文章希望大家以后多多支持hwidc!
【文章出处:美国cn2站群服务器 欢迎转载】