
Python 如何实现文件自动去重
Python 文件自动去重
平日里一来无聊,二来手巧,果然下载了好多无(luan)比(qi)珍(ba)贵(zao)的资料,搞得我小小的硬盘(已经扩到6T了)捉襟见肘,
有次无意间,发现有两个居然长得一毛一样,在房子这么小的情况下,我怎能忍两个一毛一样的东西不要脸皮的躺在我的硬盘里,果断搞掉一个,整理一下,本来想文件名一样的就保留一份,但问题出现了,居然有名字一样,内容却完全不一样的文件,想我背朝黄土面朝天吹着空调吃着西瓜下载下来的东西,删除是不可能的,这辈子都是不可能删除的。可是我也又不能把这数以亿计的文件挨个打开看看里面一样不一样吧,这个工程我大概够我做了好久好久了,有没有办法搞个软件帮帮我呢,答案是肯定的,要不然我也不用在这里写这个博客了(应该是苦逼的一个一个打开比较吧),说正题,Python提供了一个比较文件内容的东西,那就是。。。。。。。。。。哈希算法
MD5消息摘要算法(英语:MD5 Message-Digest Algorithm),一种被广泛使用的密码散列函数,可以产生出一个128位(16字节)的散列值(hash value),用于确保信息传输完整一致。MD5由美国密码学家罗纳德·李维斯特(Ronald Linn Rivest)设计,于1992年公开,用以取代MD4算法。
说了这么长,总结出来就一句,这玩意就是文件的指纹,几乎每个文件是唯一的(碰到重复的,恭喜你,可以去买彩票了),那我们就把这个指纹拿出来,一个一个比对,肯定不能会有漏网的文件,既不会错杀三千,也不使一文件漏网,原理上通了,那么我们就要去搞个代码来帮我完成这个工作,作为最好用的语言,Python就这样被我翻了牌子
# -*- coding:utf-8 -*-
import os
import hashlib
import time
import sys
#搞到文件的MD5
def get_ms5(filename):
m = hashlib.md5()
mfile = open(filename , "rb")
m.update(mfile.read())
mfile.close()
md5_value = m.hexdigest()
return md5_value
#搞到文件的列表
def get_urllist():
base = ("D:\\lwj\\spider\\pic\\")#这里就是你要清缴的文件们了
list = os.listdir(base)
urllist = []
for i in list:
url = base + i
urllist.append(url)
return urllist
#主函数
if __name__ == '__main__':
md5list = []
urllist = get_urllist()
print("test1")
for a in urllist:
md5 = get_ms5(a)
if(md5 in md5list):
os.remove(a)
print("重复:%s" % a)
else:
md5list.append(md5)
print("一共%s张照片" % len(md5list))
效果
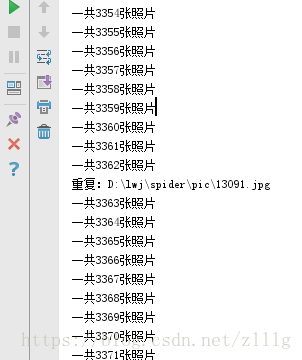
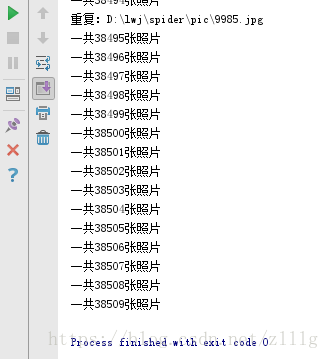
python3 大文件去重
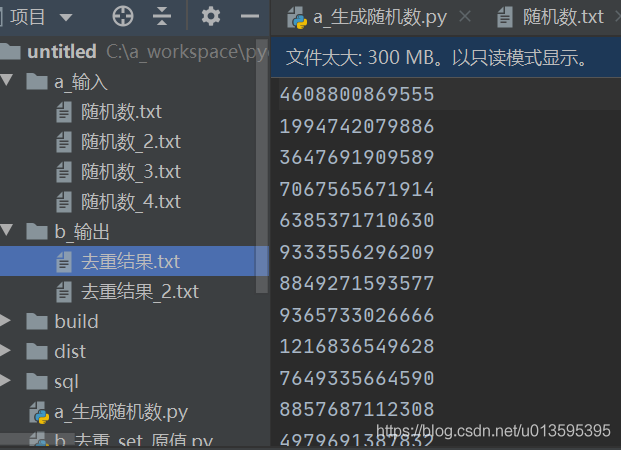
一、生成待去重数据
每行是固定位数的数字串
import os
from random import randint
#-- from u_工具 import *
print("———— 开始 ————")
#-- 打点()
# 用来配置的变量
位数 = 13
行数 = 500 * 10000
输出目录 = "./a_输入"
输出文件 = f"{输出目录}/随机数.txt"
# 预处理
_00 = "".join(["0" for i in range(位数 - 1)])
_100 = "1" + _00
最小值 = int(_100)
_1000 = _100 + "0"
最大值 = int(_1000)
if not os.path.exists(输出目录):
os.makedirs(输出目录)
#-- 输出文件 = 文件名防重_追加数字(输出文件)
# 实际处理
with open(输出文件,"a") as f:
for i in range(行数):
f.write(f"{randint(最小值, 最大值)}\n")
百分比 = (i+1) / 行数 * 100
if 百分比 == int(百分比):
print(f"已完成{int(百分比)}%")
#-- 打点()
#-- print(f"\n总耗时:{计时(0)}")
print("———— 结束 ————")
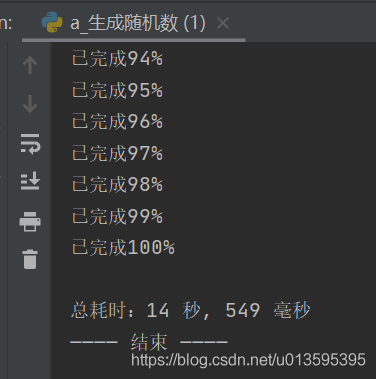
二、通过set按行去重
1. 按原值比较
(1)读取全部数据
(2)用split来分行
(3)通过set数据结构来去除重复数据
(4)将set的数据写入文件
import os
#-- from u_工具 import *
print("———— 开始 ————")
#-- 打点()
# 用来配置的变量
输入目录 = "./a_输入"
输出目录 = "./b_输出"
输出文件 = f"{输出目录}/去重结果.txt"
# 预处理
# 目录不存在就手动建立
if not os.path.exists(输出目录):
os.makedirs(输出目录)
if not os.path.exists(输入目录):
os.makedirs(输入目录)
#-- 输出文件 = 文件名防重_追加数字(输出文件)
# 获取待去重文件
待去重文件列表 = []
待去重文件列表 = [f"{输入目录}/{i}" for i in os.listdir(输入目录)]
#-- getDeepFilePaths(待去重文件列表,输入目录,"txt")
print(f"\n总共{len(待去重文件列表)}个文件")
换行符 = b"\n"
if platform.system().lower() == 'windows':
换行符 = b"\r\n"
# 实际处理
all_lines = []
文件个数 = 0
for 文件 in 待去重文件列表:
文件个数 += 1
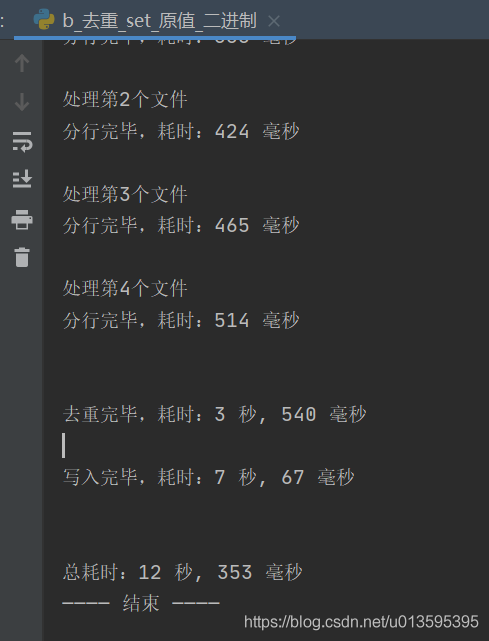
print(f"\n处理第{文件个数}个文件")
#-- 打点()
# (1)读全部
with open(文件, "rb") as f:
data = f.read()
# (2)split分行
lines = data.split(换行符)
all_lines.extend(lines)
#-- 打点()
#-- print(f"分行完毕,耗时:{计时()}")
# (3)集合去重
all_lines_set = set(all_lines)
all_lines_set.remove(b"")
#-- 打点()
#-- print(f"\n\n去重完毕,耗时:{计时()}")
# (4)循环写入
with open(输出文件,"ab") as f_rst:
for line in all_lines_set:
f_rst.write(line + 换行符)
#-- 打点()
#-- print(f"\n写入完毕,耗时:{计时()}")
print(f"\n输出文件:{输出文件}")
#-- 打点()
#-- print(f"\n\n总耗时:{计时(0)}")
print("———— 结束 ————")
附:
(2)用正则表达式来分行
import re
# (2)正则分行 二进制的话要加b, b''' '''
regx = '''[\w\~`\!\@\#\$\%\^\&\*\(\)\_\-\+\=\[\]\{\}\:\;\,\.\/\<\>\?]+'''
lines = re.findall(regx, data)
2. 按md5比较
import hashlib
import os
#-- from u_工具 import *
print("———— 开始 ————")
#-- 打点()
# 用来配置的变量
输入目录 = "./a_输入"
输出目录 = "./b_输出"
输出文件 = f"{输出目录}/去重结果.txt"
# 预处理
# 目录不存在就手动建立
if not os.path.exists(输出目录):
os.makedirs(输出目录)
if not os.path.exists(输入目录):
os.makedirs(输入目录)
#-- 输出文件 = 文件名防重_追加数字(输出文件)
# 获取待去重文件
待去重文件列表 = [f"{输入目录}/{i}" for i in os.listdir(输入目录)]
#-- 待去重文件列表 = []
#-- getDeepFilePaths(待去重文件列表,输入目录,"txt")
print(f"\n总共{len(待去重文件列表)}个文件")
def gen_md5(data):
md5 = hashlib.md5()
if repr(type(data)) == "<class 'str'>":
data = data.encode('utf-8')
md5.update(data)
return md5.hexdigest()
# 实际处理
md5集 = set()
with open(输出文件, "a") as f_rst:
文件个数 = 0
for 文件 in 待去重文件列表:
文件个数 += 1
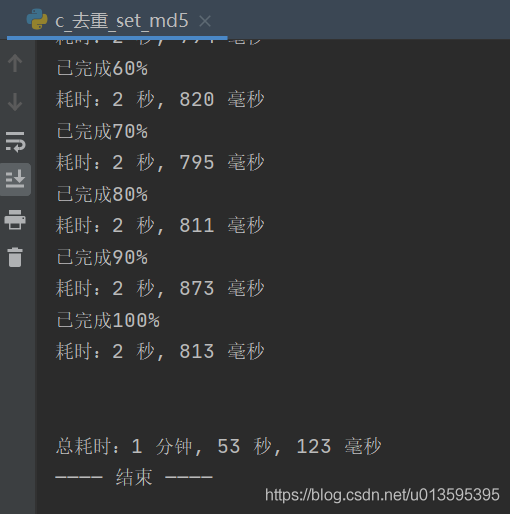
print(f"\n处理第{文件个数}个文件")
# 计算总行数
with open(文件, 'rb') as f:
行数 = 0
buf_size = 1024 * 1024
buf = f.read(buf_size)
while buf:
行数 += buf.count(b'\n')
buf = f.read(buf_size)
# 读取、分行、去重、写入
#-- 打点()
i = 0
for line_带换行 in open(文件):
i += 1
line = line_带换行.strip()
md5值 = gen_md5(line)
if md5值 not in md5集:
md5集.add(md5值)
f_rst.write(line_带换行)
百分比 = i / 行数 * 10
if 百分比 == int(百分比):
print(f"已完成{int(百分比)*10}%")
#-- 打点()
#-- print(f"耗时:{计时()}")
print(f"\n输出文件:{输出文件}")
#-- 打点()
#-- print(f"\n\n总耗时:{计时(0)}")
print("———— 结束 ————")
三、二路归并
import hashlib
import os
import platform
import queue
import shutil
from uuid import uuid1
from u_工具 import *
print("———— 开始 ————")
打点()
# 1.用来配置的变量
输入目录 = "./a_输入"
输出目录 = "./b_输出"
输出文件 = f"{输出目录}/去重结果.txt"
临时目录 = "./c_临时"
小文件大小 = 50 * 1024 * 1024 # 50M
# 2.预处理
# 目录不存在就手动建立
if not os.path.exists(输出目录):
os.makedirs(输出目录)
if not os.path.exists(输入目录):
os.makedirs(输入目录)
if not os.path.exists(临时目录):
os.makedirs(临时目录)
shutil.rmtree(临时目录)
os.makedirs(临时目录)
输出文件 = 文件名防重_追加数字(输出文件)
# 获取待去重文件
# 待去重文件列表 = [f"{输入目录}/{i}" for i in os.listdir(输入目录)]
待去重文件列表 = []
getDeepFilePaths(待去重文件列表,输入目录,"txt")
print(f"总共{len(待去重文件列表)}个文件")
换行符 = b"\n"
if platform.system().lower() == 'windows':
换行符 = b"\r\n"
# 3.实际处理
# (1)分割大文件
打点()
待排序文件列表 = []
待补全数据 = b""
for 文件 in 待去重文件列表:
with open(文件, 'rb') as f:
buf = f.read(小文件大小)
while buf:
data = buf.split(换行符,1)
新路径 = f"{临时目录}/无序_{序号(1)}_{uuid1()}.txt"
with open(新路径, 'ab') as ff:
ff.write(待补全数据 + data[0])
待排序文件列表.append(新路径)
try:
待补全数据 = data[1]
except:
待补全数据 = b""
buf = f.read(小文件大小)
新路径 = f"{临时目录}/无序_{序号(1)}_{uuid1()}.txt"
with open(新路径, 'ab') as ff:
ff.write(待补全数据 + 换行符)
待排序文件列表.append(新路径)
待补全数据 = b""
del buf,data,待补全数据
打点()
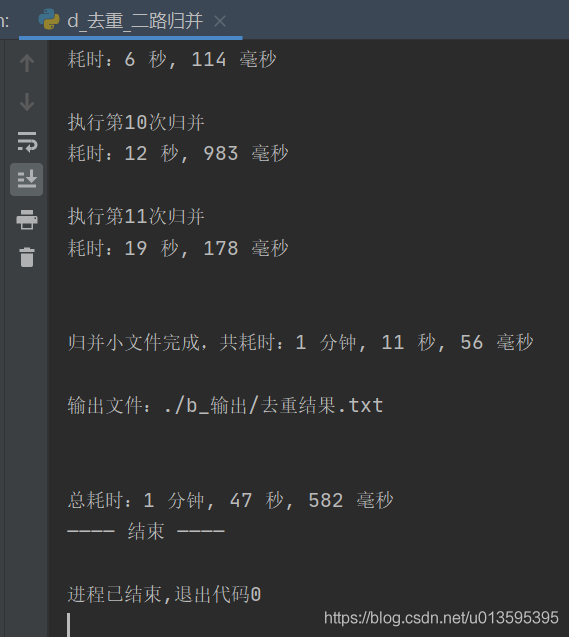
print(f"\n分割大文件完成,共耗时:{计时()}")
# (2)排序小文件
打点()
序号_重置(1)
待归并文件队列 = queue.Queue()
for 文件 in 待排序文件列表:
with open(文件, "rb") as f:
data = f.read()
data = set(data.split(换行符))
if b"" in data:
data.remove(b"")
if 换行符 in data:
data.remove(换行符)
data = sorted(data)
新路径 = f"{临时目录}/有序_{序号(1)}_{uuid1()}.txt"
with open(新路径, 'ab') as ff:
for line in data:
ff.write(line + 换行符)
待归并文件队列.put(新路径)
os.remove(文件)
del data
打点()
print(f"\n排序小文件完成,共耗时:{计时()}")
# (3)归并小文件
打点("归并前")
序号_重置(1)
个数 = 待归并文件队列.qsize()
归并次数 = 个数 - 1
print(f"\n\n归并共{归并次数}次")
当前次数 = 0
while 个数 > 1:
当前次数 += 1
print(f"\n执行第{当前次数}次归并")
文件路径a = 待归并文件队列.get()
文件路径b = 待归并文件队列.get()
新文件路径 = f"{临时目录}/{序号(1)}_{uuid1()}.txt"
if 当前次数 == 归并次数:
新文件路径 = 输出文件
with open(文件路径a,"rb") as 文件a, open(文件路径b,"rb") as 文件b, open(新文件路径,"wb") as ff:
# region 归并操作
is_a_over = False
is_b_over = False
a = 文件a.readline().strip()
b = 文件b.readline().strip()
last = None
while not (is_a_over and is_b_over):
if is_a_over:
b = 文件b.readline()
if not b:
is_b_over = True
else:
ff.write(b)
elif is_b_over:
a = 文件a.readline()
if not a:
is_a_over = True
else:
ff.write(a)
else:
# region 处理初始赋值
if not a:
is_a_over = True
if not b:
is_b_over = True
continue
else:
ff.write(b + 换行符)
continue
if not b:
is_b_over = True
ff.write(a + 换行符)
continue
# endregion
if a <= b:
if a == b or a == last:
a = 文件a.readline().strip()
if not a:
is_a_over = True
ff.write(b + 换行符)
continue
else:
last = a
ff.write(last + 换行符)
a = 文件a.readline().strip()
if not a:
is_a_over = True
ff.write(b + 换行符)
continue
else:
if b == last:
b = 文件b.readline().strip()
if not b:
is_b_over = True
ff.write(a + 换行符)
continue
else:
last = b
ff.write(last + 换行符)
b = 文件b.readline().strip()
if not b:
is_b_over = True
ff.write(a + 换行符)
continue
# endregion
待归并文件队列.put(新文件路径)
os.remove(文件路径a)
os.remove(文件路径b)
个数 = 待归并文件队列.qsize()
打点()
print(f"耗时:{计时()}")
打点("归并后")
print(f"\n\n归并小文件完成,共耗时:{计时('归并前','归并后')}")
print(f"\n输出文件:{输出文件}")
打点()
print(f"\n\n总耗时:{计时(0)}")
print("———— 结束 ————")
以上为个人经验,希望能给大家一个参考,也希望大家多多支持hwidc。
【本文转自:鄂州网站推广 转载请保留连接】