
从np.random.normal()到正态分布的拟合操作
先看伟大的高斯分布(Gaussian Distribution)的概率密度函数(probability density function):
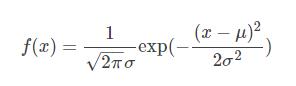
对应于numpy中:
numpy.random.normal(loc=0.0, scale=1.0, size=None)
参数的意义为:
loc:float
此概率分布的均值(对应着整个分布的中心centre)
scale:float
此概率分布的标准差(对应于分布的宽度,scale越大越矮胖,scale越小,越瘦高)
size:int or tuple of ints
输出的shape,默认为None,只输出一个值
我们更经常会用到的np.random.randn(size)所谓标准正态分布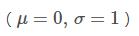
对应于np.random.normal(loc=0, scale=1, size)。
采样(sampling)
# 从某一分布(由均值和标准差标识)中获得样本 mu, sigma = 0, .1 s = np.random.normal(loc=mu, scale=sigma, size=1000)
也可使用scipy库中的相关api(这里的类与函数更符合数理统计中的直觉):
import scipy.stats as st mu, sigma = 0, .1 s = st.norm(mu, sigma).rvs(1000)
校验均值和方差:
>>> abs(mu < np.mean(s)) < .01
True
>>> abs(sigma-np.std(s, ddof=1)) < .01
True
# ddof,delta degrees of freedom,表示自由度
# 一般取1,表示无偏估计,
拟合
我们看使用matplotlib.pyplot便捷而强大的语法如何进行高斯分布的拟合:
import matplotlib.pyplot as plt
count, bins, _ = plt.hist(s, 30, normed=True)
# normed是进行拟合的关键
# count统计某一bin出现的次数,在Normed为True时,可能其值会略有不同
plt.plot(bins, 1./(np.sqrt(2*np.pi)*sigma)*np.exp(-(bins-mu)**2/(2*sigma**2), lw=2, c='r')
plt.show()
或者:
s_fit = np.linspace(s.min(), s.max()) plt.plot(s_fit, st.norm(mu, sigma).pdf(s_fit), lw=2, c='r')
np.random.normal()的含义及实例
这是个随机产生正态分布的函数。(normal 表正态)
先看一下官方解释:
有三个参数
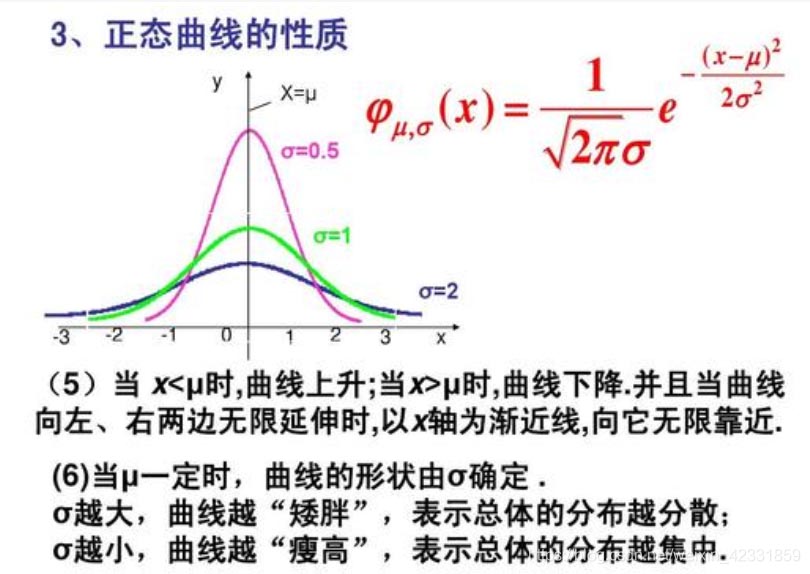
loc:正态分布的均值,对应着这个分布的中心.代表下图的μ
scale:正态分布的标准差,对应分布的宽度,scale越大,正态分布的曲线 越矮胖,scale越小,曲线越高瘦。 代表下图的σ
size:你输入数据的shape,例子:
下面展示一些 内联代码片。
// An highlighted block a=np.random.normal(0, 1, (2, 4)) print(a) 输出: [[-0.29217334 0.41371571 1.26816017 0.46474676] [ 1.33271487 0.80162296 0.47974157 -1.49748788]]
看这个图直观些:
以下为官方文档:


以上为个人经验,希望能给大家一个参考,也希望大家多多支持hwidc。