
浅谈Pytorch 定义的网络结构层能否重复使用
前言:最近在构建网络的时候,有一些层参数一样,于是就没有定义新的层,直接重复使用了原来已经有的层,发现效果和模型大小都没有什么变化,心中产生了疑问:定义的网络结构层能否重复使用?因此接下来利用了一个小模型网络实验了一下。
一、网络结构一:(连续使用相同的层)
1、网络结构如下所示:
class Cnn(nn.Module):
def __init__(self):
super(Cnn, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(
in_channels = 3, #(, 64, 64, 3)
out_channels = 16,
kernel_size = 3,
stride = 1,
padding = 1
), ##( , 64, 64, 16)
nn.ReLU(),
nn.MaxPool2d(kernel_size = 2)
) ##( , 32, 32, 16)
self.conv2 = nn.Sequential(
nn.Conv2d(16,32,3,1,1),
nn.ReLU(),
nn.MaxPool2d(2)
)
self.conv3 = nn.Sequential(
nn.Conv2d(32,64,3,1,1),
nn.ReLU(),
nn.MaxPool2d(2)
)
self.conv4 = nn.Sequential(
nn.Conv2d(64,64,3,1,1),
nn.BatchNorm2d(64),
nn.ReLU(),
)
self.out = nn.Linear(64*8*8, 6)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = x.view(x.size(0),-1)
out = self.out(x)
return out
定义了一个卷积层conv4,接下来围绕着这个conv4做一些变化。打印一下网络结构:
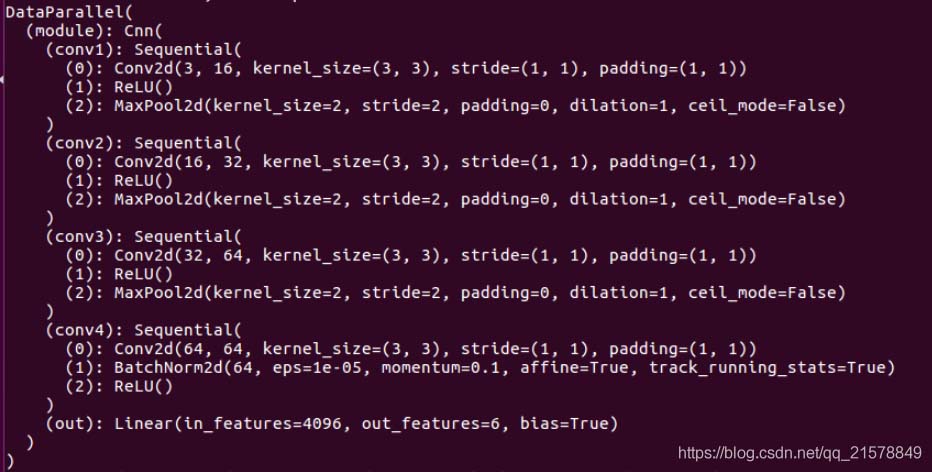
和想象中的一样,其中
nn.BatchNorm2d # 对应上面的 module.conv4.1.*
激活层没有参数所以直接跳过
2、改变一下forward():
连续使用两个conv4层:
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.conv4(x)
x = x.view(x.size(0),-1)
out = self.out(x)
return out
打印网络结构:
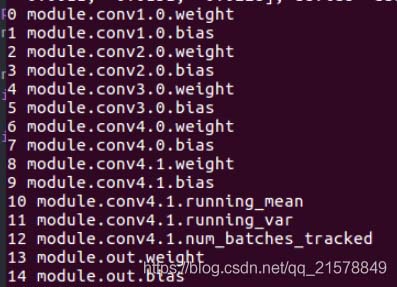
和1.1中的结构一样,conv4没有生效。
二、网络结构二:(间断使用相同的层)
网络结构多定义一个和conv4一样的层conv5,同时间断使用conv4:
self.conv4 = nn.Sequential(
nn.Conv2d(64,64,3,1,1),
nn.BatchNorm2d(64),
nn.ReLU(),
)
self.conv5 = nn.Sequential(
nn.Conv2d(64,64,3,1,1),
nn.BatchNorm2d(64),
nn.ReLU(),
)
self.out = nn.Linear(64*8*8, 6)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.conv5(x)
x = self.conv4(x)
x = x.view(x.size(0),-1)
out = self.out(x)
return out
打印网络结构:
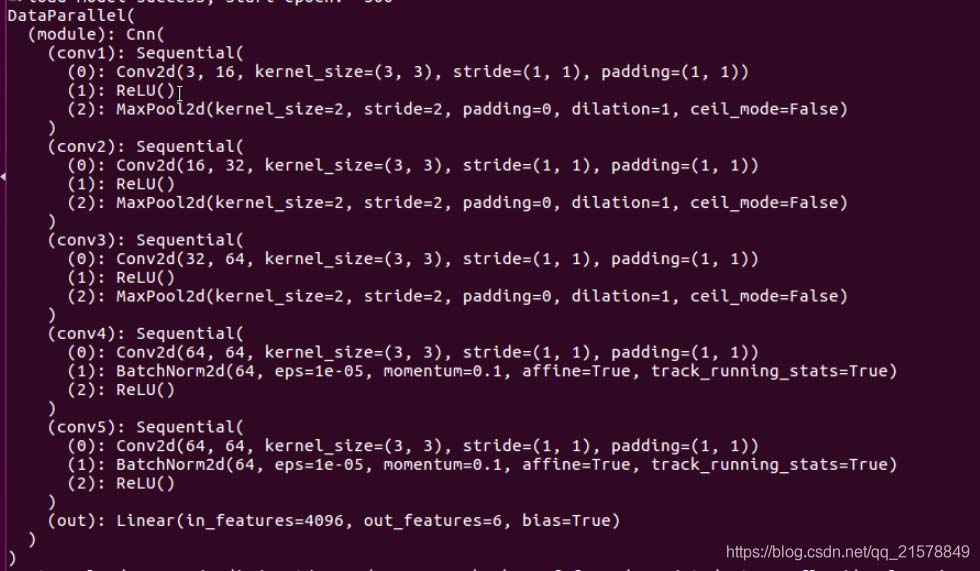
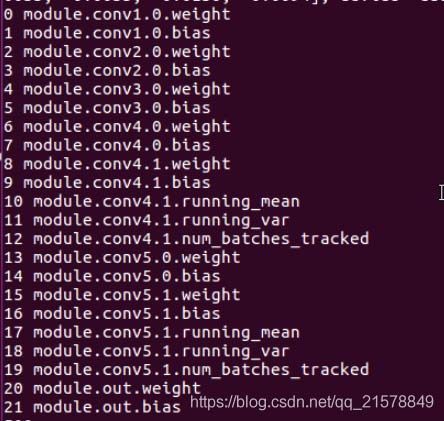
果不其然,新定义的conv5有效,conv4还是没有生效。
本来以为,使用重复定义的层会像conv4.0,conv4.1,…这样下去,看样子是不能重复使用定义的层。
Pytorch_5.7 使用重复元素的网络--VGG
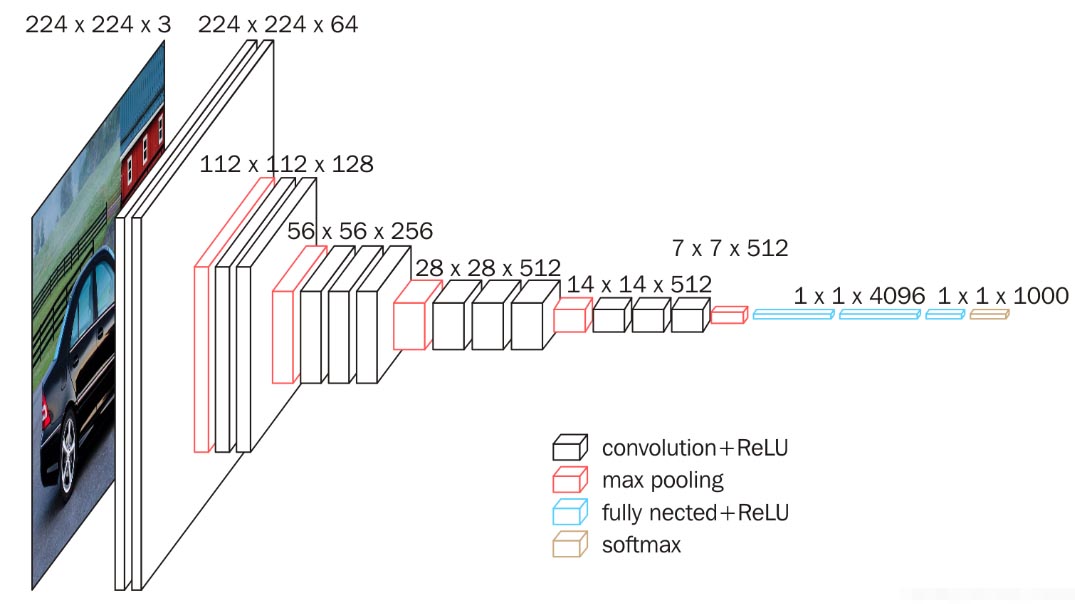
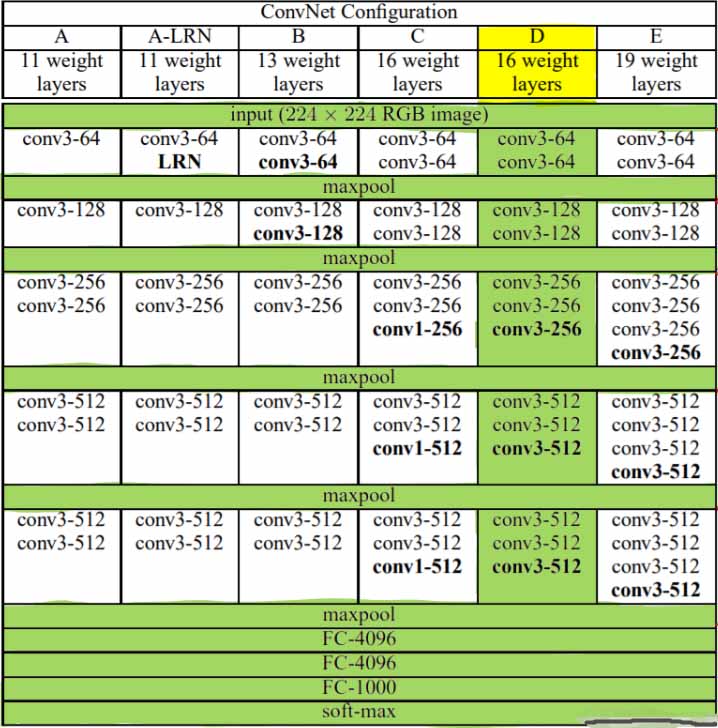
5.7.1 VGG块
VGG引入了Block的概念 作为模型的基础模块
import time
import torch
from torch import nn, optim
import pytorch_deep as pyd
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
def vgg_block(num_convs, in_channels, out_channels):
blk = []
for i in range(num_convs):
if i == 0:
blk.append(nn.Conv2d(in_channels, out_channels,kernel_size=3, padding=1))
else:
blk.append(nn.Conv2d(out_channels, out_channels,kernel_size=3, padding=1))
blk.append(nn.ReLU())
blk.append(nn.MaxPool2d(kernel_size=2, stride=2)) # 这⾥会使宽⾼减半
return nn.Sequential(*blk)
实现VGG_11网络
8个卷积层和3个全连接
def vgg_11(conv_arch, fc_features, fc_hidden_units=4096):
net = nn.Sequential()
# 卷积层部分
for i, (num_convs, in_channels, out_channels) in enumerate(conv_arch):
# 每经过⼀个vgg_block都会使宽⾼减半
net.add_module("vgg_block_" + str(i+1),vgg_block(num_convs, in_channels, out_channels))
# 全连接层部分
net.add_module("fc", nn.Sequential(
pyd.FlattenLayer(),
nn.Linear(fc_features,fc_hidden_units),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(fc_hidden_units,fc_hidden_units),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(fc_hidden_units, 10)
))
return net
ratio = 8 small_conv_arch = [(1, 1, 64//ratio), (1, 64//ratio, 128//ratio),(2, 128//ratio, 256//ratio),(2, 256//ratio, 512//ratio), (2, 512//ratio,512//ratio)] fc_features = 512 * 7 * 7 # c * fc_hidden_units = 4096 # 任意 net = vgg_11(small_conv_arch, fc_features // ratio, fc_hidden_units //ratio) print(net)
Sequential(
(vgg_block_1): Sequential(
(0): Conv2d(1, 8, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(vgg_block_2): Sequential(
(0): Conv2d(8, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(vgg_block_3): Sequential(
(0): Conv2d(16, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU()
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(vgg_block_4): Sequential(
(0): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU()
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(vgg_block_5): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU()
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(fc): Sequential(
(0): FlattenLayer()
(1): Linear(in_features=3136, out_features=512, bias=True)
(2): ReLU()
(3): Dropout(p=0.5)
(4): Linear(in_features=512, out_features=512, bias=True)
(5): ReLU()
(6): Dropout(p=0.5)
(7): Linear(in_features=512, out_features=10, bias=True)
)
)
训练数据
batch_size = 32 # 如出现“out of memory”的报错信息,可减⼩batch_size或resize train_iter, test_iter = pyd.load_data_fashion_mnist(batch_size,resize=224) lr, num_epochs = 0.001, 5 optimizer = torch.optim.Adam(net.parameters(), lr=lr) pyd.train_ch5(net, train_iter, test_iter, batch_size, optimizer,device, num_epochs)
training on cuda epoch 1, loss 0.5166, train acc 0.810, test acc 0.872,time 57.6 sec epoch 2, loss 0.1557, train acc 0.887, test acc 0.902,time 57.9 sec epoch 3, loss 0.0916, train acc 0.900, test acc 0.907,time 57.7 sec epoch 4, loss 0.0609, train acc 0.912, test acc 0.915,time 57.6 sec epoch 5, loss 0.0449, train acc 0.919, test acc 0.914,time 57.4 sec
以上为个人经验,希望能给大家一个参考,也希望大家多多支持hwidc。
【本文转自:天门网站优化提供,感恩】