
使用Pytorch实现two-head(多输出)模型的操作
如何使用Pytorch实现two-head(多输出)模型
1. two-head模型定义
先放一张我要实现的模型结构图:
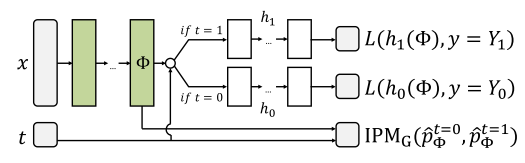
如上图,就是一个two-head模型,也是一个但输入多输出模型。该模型的特点是输入一个x和一个t,h0和h1中只有一个会输出,所以可能这不算是一个典型的多输出模型。
2.实现所遇到的困难 一开始的想法:
这不是很简单嘛,做一个判断不就完了,t=0时模型为前半段加h0,t=1时模型为前半段加h1。但实现的时候傻眼了,发现在真正前向传播的时候t是一个tensor,有0有1,没法儿进行判断。
灵机一动,又生一法:把这个模型变为三个模型,前半段是一个模型(r),后面的h0和h1分别为另两个模型。把数据集按t=0和1分开,分别训练两个模型:r+h0和r+h1。
但是后来搜如何进行模型串联,发现极为麻烦。
3.解决方案
后来在pytorch的官方社区中看到一个极为简单的方法:
(1) 按照一般的多输出模型进行实现,代码如下:
def forward(self, x):
#三层的表示层
x = F.elu(self.fcR1(x))
x = F.elu(self.fcR2(x))
x = F.elu(self.fcR3(x))
#two-head,两个head分别进行输出
y0 = F.elu(self.fcH01(x))
y0 = F.elu(self.fcH02(y0))
y0 = F.elu(self.fcH03(y0))
y1 = F.elu(self.fcH11(x))
y1 = F.elu(self.fcH12(y1))
y1 = F.elu(self.fcH13(y1))
return y0, y1
这样就相当实现了一个多输出模型,一个x同时输出y0和y1.
训练的时候分别训练,也即分别建loss,代码如下:
f_out_y0, _ = net(x0)
_, f_out_y1 = net(x1)
#实例化损失函数
criterion0 = Loss()
criterion1 = Loss()
loss0 = criterion0(f_y0, f_out_y0, w0)
loss1 = criterion1(f_y1, f_out_y1, w1)
print(loss0.item(), loss1.item())
#对网络参数进行初始化
optimizer.zero_grad()
loss0.backward()
loss1.backward()
#对网络的参数进行更新
optimizer.step()
先把x按t=0和t=1分为x0和x1,然后分别送入进行训练。这样就实现了一个two-head模型。
4.后记
我自以为多输出模型可以分为以下两类:
多个输出不同时获得,如本文情况。
多个输出同时获得。
多输出不同时获得的解决方法上文已说明。多输出同时获得则可以通过把y0和y1拼接起来一起输出来实现。
补充:PyTorch 多输入多输出模型构建
本篇教程基于 PyTorch 1.5版本
直接上代码!
import torch
import torch.nn as nn
from torch.autograd import Variable
import torch.distributed as dist
import torch.utils.data as data_utils
class Net(nn.Module):
def __init__(self, n_input, n_hidden, n_output):
super(Net, self).__init__()
self.hidden1 = nn.Linear(n_input, n_hidden)
self.hidden2 = nn.Linear(n_hidden, n_hidden)
self.predict1 = nn.Linear(n_hidden*2, n_output)
self.predict2 = nn.Linear(n_hidden*2, n_output)
def forward(self, input1, input2): # 多输入!!!
out01 = self.hidden1(input1)
out02 = torch.relu(out01)
out03 = self.hidden2(out02)
out04 = torch.sigmoid(out03)
out11 = self.hidden1(input2)
out12 = torch.relu(out11)
out13 = self.hidden2(out12)
out14 = torch.sigmoid(out13)
out = torch.cat((out04, out14), dim=1) # 模型层拼合!!!当然你的模型中可能不需要~
out1 = self.predict1(out)
out2 = self.predict2(out)
return out1, out2 # 多输出!!!
net = Net(1, 20, 1)
x1 = torch.unsqueeze(torch.linspace(-1, 1, 100), dim=1) # 请不要关心这里,随便弄一个数据,为了说明问题而已
y1 = x1.pow(3)+0.1*torch.randn(x1.size())
x2 = torch.unsqueeze(torch.linspace(-1, 1, 100), dim=1)
y2 = x2.pow(3)+0.1*torch.randn(x2.size())
x1, y1 = (Variable(x1), Variable(y1))
x2, y2 = (Variable(x2), Variable(y2))
optimizer = torch.optim.SGD(net.parameters(), lr=0.1)
loss_func = torch.nn.MSELoss()
for t in range(5000):
prediction1, prediction2 = net(x1, x2)
loss1 = loss_func(prediction1, y1)
loss2 = loss_func(prediction2, y2)
loss = loss1 + loss2 # 重点!
optimizer.zero_grad()
loss.backward()
optimizer.step()
if t % 100 == 0:
print('Loss1 = %.4f' % loss1.data,'Loss2 = %.4f' % loss2.data,)
至此搞定!
以上为个人经验,希望能给大家一个参考,也希望大家多多支持hwidc。