
用Python进行栅格数据的分区统计和批量提取
有时候我们会有这样的想法,就是针对某个区域的栅格数据,要提取它的平均值或者其他统计指标,比如在一个省内提取多年的降雨数据,最后分区域地计算一些统计值,或者从多个栅格数据中提取某个区域的数值形成一个序列。为了方便,画一个示意图看看,比如就像提取这个区域中的某一个市的区域,然后形成一个序列数据,这就可以使用rasterstats库了,此外的分区统计也可以用这个库
这个实验使用的数据格式分别是栅格(*.tif)和矢量(.shp),之后的分区统计操作和栅格数据的提取都是源于这两类数据。为了能使用上这个rasterstats库,选择了在google colab平台运行脚本,因为安装库实在是太方便了,在win上老是安装不上的,在google notebook立马就搞定了,而且可以把数据存储到谷歌云盘,直接在notebook中就是可以链接使用的
那么现在就开始做测试,使用的数据就是左侧的栅格和矢量数据集
导入相关的模块
import geopandas as gpd import pandas as pd import numpy as np import matplotlib.pyplot as plt import rasterio import rasterstats from rasterio.plot import show # show()方法用来展示栅格图形 from rasterio.plot import show_hist # 用来展示直方图 import cartopy.crs as ccrs import cartopy.feature as cfeature from cartopy.mpl.ticker import LongitudeFormatter, LatitudeFormatter
使用geopandas和rasterio分别读取矢量和栅格数据
# 使用geopandas读取矢量数据
districts = gpd.read_file('/content/drive/MyDrive/Datashpraster/Data/Districts/districts.shp')
# 使用rasterio读取栅格数据,栅格数据和矢量数据的坐标投影需要一致
raster = rasterio.open('/content/drive/MyDrive/Datashpraster/Data/Rainfall Data Rasters/2020-4-1.tif')
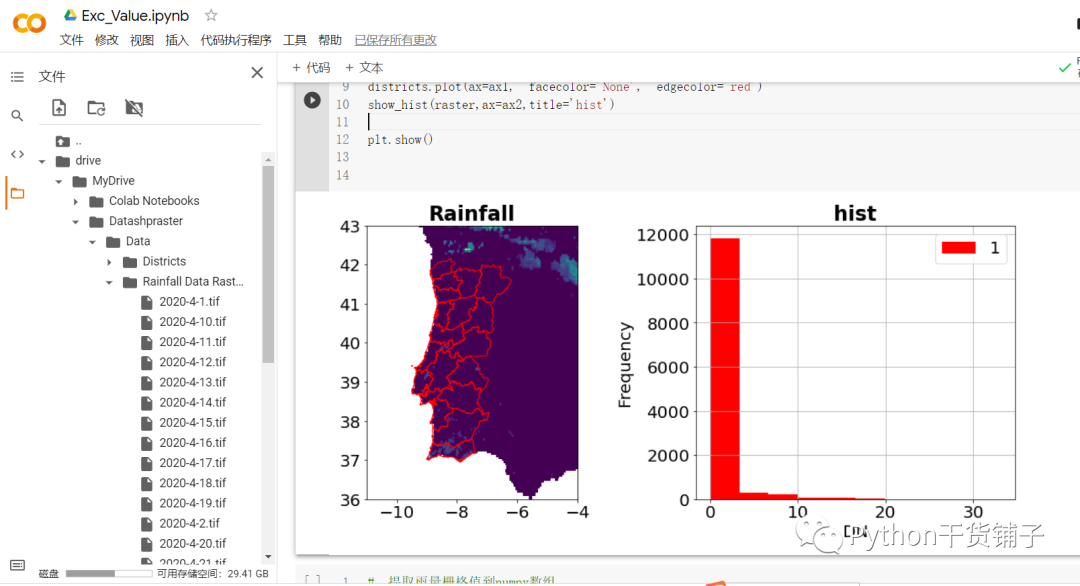
# 把矢量数据和栅格数据绘制到一个axis上,这个axis不是坐标轴,而是图形 plt.rcParams['font.family'] = 'Times New Roman' plt.rcParams['font.size'] = 20 fig, (ax1,ax2) = plt.subplots(1,2,figsize=(15,6)) show(raster, ax=ax1,title='Rainfall') # 读取进来的矢量数据可以直接调用gpd的plot()方法绘制 districts.plot(ax=ax1, facecolor='None', edgecolor='red') show_hist(raster,ax=ax2,title='hist') plt.show()
先绘制一下结果看看
读取栅格数据:
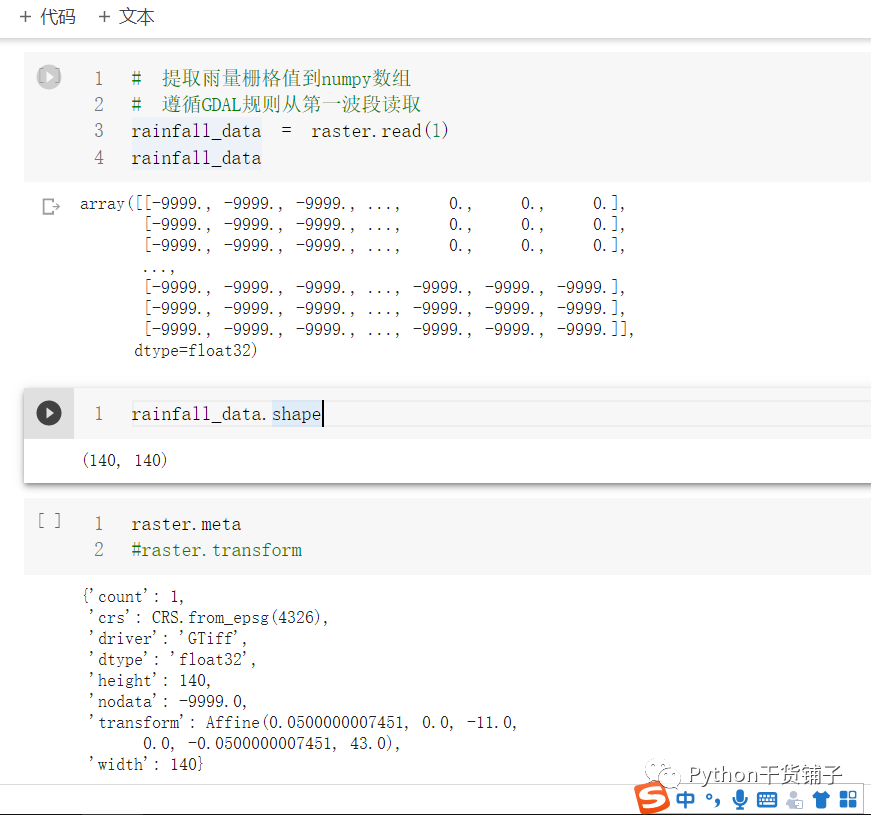
# 提取雨量栅格值到numpy数组 # 遵循GDAL规则从第一波段读取 rainfall_data = raster.read(1) rainfall_data
开始分区统计:
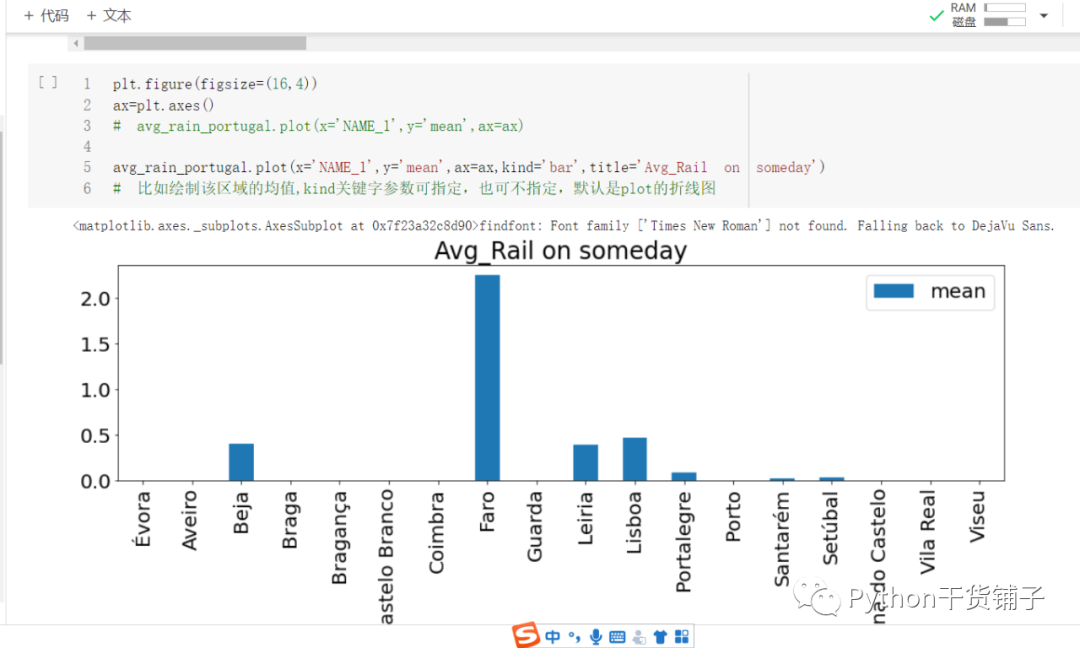
# 设置坐标变换信息 affine = raster.transform # 准备开始进行空间分区计算 # 第一个参数是矢量分区,第二个是栅格,第三个是坐标变换信息,第四个是统计均值 avg_rallrain = rasterstats.zonal_stats(districts,rainfall_data,affine=affine,stats=['mean'],geojson_out=True) # avg_rallrain # 除了统计平均值之外,还有最大最小值那些
绘制一下,只是一个简单的图形而已
当然第二部分更有意思,就是从多个分散的栅格数据中提取数据形成一个序列
,就是这些tif数据
loop这些栅格数据集:
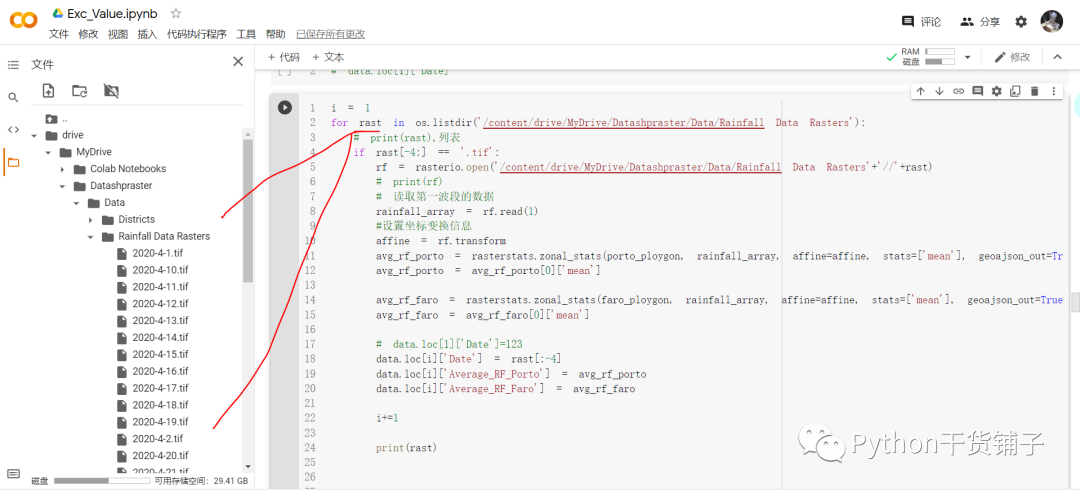
获得提取到的结果,没错,就是这么一个序列数据,然后就是绘图了
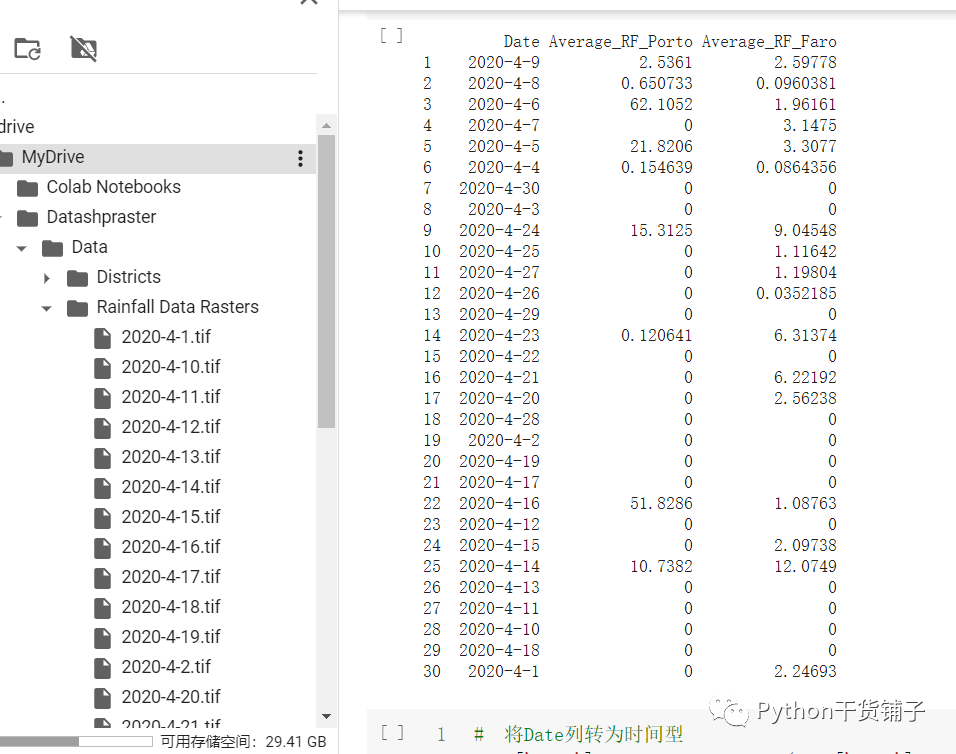
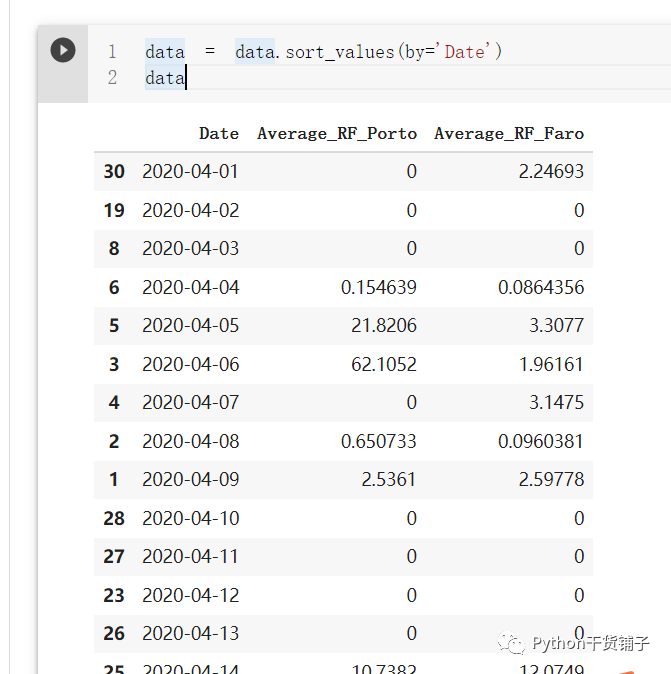
转换数据格式
# 将Date列转为时间型 data['Date'] = pd.to_datetime(data['Date'], infer_datetime_format=True) # print(data) data['Date'] = data['Date'].dt.date print(data)
绘图结果就是简单的图形而已
# 准备绘制图形 fig,(ax1,ax2)= plt.subplots(2,1,figsize=(18,6)) plt.rcParams['font.size'] = 15 data.plot(x='Date', y='Average_RF_Porto', ax=ax1, kind='bar', title='Avg_Rail_Porto') data.plot(x='Date', y='Average_RF_Faro', ax=ax2, kind='bar', title='Avg_Rail_Faro',color='red') #自动调整图形的分布 plt.tight_layout() plt.show()
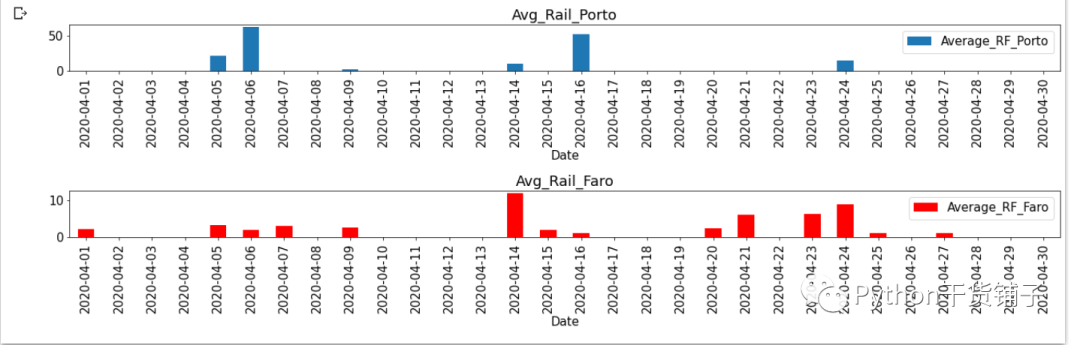
结果就这样一个序列图,目的就是从栅格提取指定的研究区,然后提取栅格的值,再来绘图
虽然感觉不是那么花里胡哨的图,但这个应该还是比较实用的,特别是大批量提取栅格值的时候。由于在google colab里面操作的步骤比较多,中间可能有省略的地方,但重要的应该都在文中了,当然也可以迁移运用到其他地方,也可以查看一下这个第三方库的教程,比如read(1)是什么意思,官网的docs就写得有,实在是很方便的
以上就是用Python进行栅格数据的分区统计和批量提取的详细内容,更多关于Python 栅格数据的分区统计和批量提取 的资料请关注hwidc其它相关文章!
【宜昌网站推广 提供 转载请保留URL】