
pytorch Dropout过拟合的操作
如下所示:
import torch
from torch.autograd import Variable
import matplotlib.pyplot as plt
torch.manual_seed(1)
N_SAMPLES = 20
N_HIDDEN = 300
# training data
x = torch.unsqueeze(torch.linspace(-1, 1, N_SAMPLES), 1)
y = x + 0.3 * torch.normal(torch.zeros(N_SAMPLES, 1), torch.ones(N_SAMPLES, 1))
x, y = Variable(x), Variable(y)
# test data
test_x = torch.unsqueeze(torch.linspace(-1, 1, N_SAMPLES), 1)
test_y = test_x + 0.3 * torch.normal(torch.zeros(N_SAMPLES, 1), torch.ones(N_SAMPLES, 1))
test_x = Variable(test_x, volatile=True)
test_y = Variable(test_y, volatile=True)
# show data
# plt.scatter(x.data.numpy(), y.data.numpy(), c='magenta', s=50, alpha=0.5, label='train')
# plt.scatter(test_x.data.numpy(), test_y.data.numpy(), c='cyan', s=50, alpha=0.5, label='test')
# plt.legend(loc='upper left')
# plt.ylim((-2.5, 2.5))
# plt.show()
net_overfitting = torch.nn.Sequential(
torch.nn.Linear(1, N_HIDDEN),
torch.nn.ReLU(),
torch.nn.Linear(N_HIDDEN, N_HIDDEN),
torch.nn.ReLU(),
torch.nn.Linear(N_HIDDEN, 1),
)
net_dropped = torch.nn.Sequential(
torch.nn.Linear(1, N_HIDDEN),
torch.nn.Dropout(0.5),
torch.nn.ReLU(),
torch.nn.Linear(N_HIDDEN, N_HIDDEN),
torch.nn.Dropout(0.5),
torch.nn.ReLU(),
torch.nn.Linear(N_HIDDEN, 1),
)
print(net_overfitting)
print(net_dropped)
optimizer_ofit = torch.optim.Adam(
net_overfitting.parameters(),
lr = 0.01,
)
optimizer_drop = torch.optim.Adam(
net_dropped.parameters(),
lr = 0.01,
)
loss_func = torch.nn.MSELoss()
plt.ion()
for t in range(500):
pred_ofit = net_overfitting(x)
pred_drop = net_dropped(x)
loss_ofit = loss_func(pred_ofit, y)
loss_drop = loss_func(pred_drop, y)
optimizer_ofit.zero_grad()
optimizer_drop.zero_grad()
loss_ofit.backward()
loss_drop.backward()
optimizer_ofit.step()
optimizer_drop.step()
if t % 10 == 0:
net_overfitting.eval()
net_dropped.eval()
plt.cla()
test_pred_ofit = net_overfitting(test_x)
test_pred_drop = net_dropped(test_x)
plt.scatter(x.data.numpy(), y.data.numpy(), c='magenta', s=50, alpha=0.3, label='train')
plt.scatter(test_x.data.numpy(), test_y.data.numpy(), c='cyan', s=50, alpha=0.3, label='test')
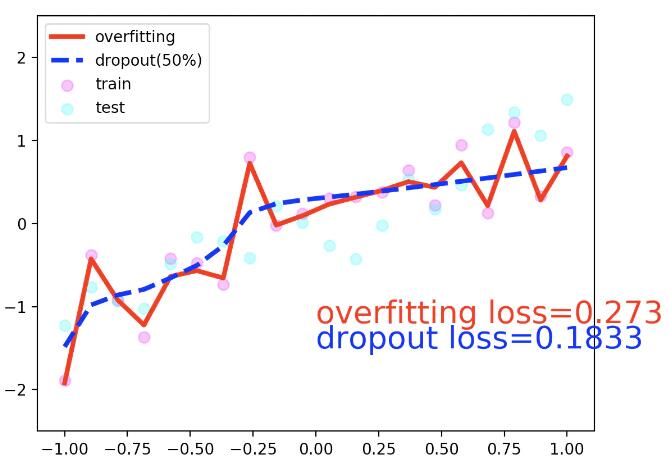
plt.plot(test_x.data.numpy(), test_pred_ofit.data.numpy(), 'r-', lw=3, label='overfitting')
plt.plot(test_x.data.numpy(), test_pred_drop.data.numpy(), 'b--', lw=3, label='dropout(50%)')
plt.text(0, -1.2, 'overfitting loss=%.4f' % loss_func(test_pred_ofit, test_y).data[0], fontdict={'size': 20, 'color': 'red'})
plt.text(0, -1.5, 'dropout loss=%.4f' % loss_func(test_pred_drop, test_y).data[0], fontdict={'size': 20, 'color': 'blue'})
plt.legend(loc='upper left'); plt.ylim((-2.5, 2.5));plt.pause(0.1)
net_overfitting.train()
net_dropped.train()
plt.ioff()
plt.show()
补充:pytorch避免过拟合-dropout丢弃法的实现
对于一个单隐藏层的多层感知机,其中输入个数为4,隐藏单元个数为5,且隐藏单元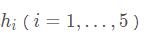 的计算表达式为:
的计算表达式为:


开始实现drop丢弃法避免过拟合
定义dropout函数:
%matplotlib inline
import torch
import torch.nn as nn
import numpy as np
def dropout(X, drop_prob):
X = X.float()
assert 0 <= drop_prob <= 1
keep_prob = 1 - drop_prob
# 这种情况下把全部元素都丢弃
if keep_prob == 0:
return torch.zeros_like(X)
mask = (torch.rand(X.shape) < keep_prob).float()
return mask * X / keep_prob
定义模型参数:
num_inputs, num_outputs, num_hiddens1, num_hiddens2 = 784, 10, 256, 256 W1 = torch.tensor(np.random.normal(0, 0.01, size=(num_inputs, num_hiddens1)), dtype=torch.float, requires_grad=True) b1 = torch.zeros(num_hiddens1, requires_grad=True) W2 = torch.tensor(np.random.normal(0, 0.01, size=(num_hiddens1, num_hiddens2)), dtype=torch.float, requires_grad=True) b2 = torch.zeros(num_hiddens2, requires_grad=True) W3 = torch.tensor(np.random.normal(0, 0.01, size=(num_hiddens2, num_outputs)), dtype=torch.float, requires_grad=True) b3 = torch.zeros(num_outputs, requires_grad=True) params = [W1, b1, W2, b2, W3, b3]
定义模型将全连接层和激活函数ReLU串起来,并对每个激活函数的输出使用丢弃法。
分别设置各个层的丢弃概率。通常的建议是把靠近输入层的丢弃概率设得小一点。
在这个实验中,我们把第一个隐藏层的丢弃概率设为0.2,把第二个隐藏层的丢弃概率设为0.5。
我们可以通过参数is_training来判断运行模式为训练还是测试,并只在训练模式下使用丢弃法。
drop_prob1, drop_prob2 = 0.2, 0.5
def net(X, is_training=True):
X = X.view(-1, num_inputs)
H1 = (torch.matmul(X, W1) + b1).relu()
if is_training: # 只在训练模型时使用丢弃法
H1 = dropout(H1, drop_prob1) # 在第一层全连接后添加丢弃层
H2 = (torch.matmul(H1, W2) + b2).relu()
if is_training:
H2 = dropout(H2, drop_prob2) # 在第二层全连接后添加丢弃层
return torch.matmul(H2, W3) + b3
def evaluate_accuracy(data_iter, net):
acc_sum, n = 0.0, 0
for X, y in data_iter:
if isinstance(net, torch.nn.Module):
net.eval() # 评估模式, 这会关闭dropout
acc_sum += (net(X).argmax(dim=1) == y).float().sum().item()
net.train() # 改回训练模式
else: # 自定义的模型
if('is_training' in net.__code__.co_varnames): # 如果有is_training这个参数
# 将is_training设置成False
acc_sum += (net(X, is_training=False).argmax(dim=1) == y).float().sum().item()
else:
acc_sum += (net(X).argmax(dim=1) == y).float().sum().item()
n += y.shape[0]
return acc_sum / n
训练和测试模型:
num_epochs, lr, batch_size = 5, 100.0, 256
loss = torch.nn.CrossEntropyLoss()
def load_data_fashion_mnist(batch_size, resize=None, root='~/Datasets/FashionMNIST'):
"""Download the fashion mnist dataset and then load into memory."""
trans = []
if resize:
trans.append(torchvision.transforms.Resize(size=resize))
trans.append(torchvision.transforms.ToTensor())
transform = torchvision.transforms.Compose(trans)
mnist_train = torchvision.datasets.FashionMNIST(root=root, train=True, download=True, transform=transform)
mnist_test = torchvision.datasets.FashionMNIST(root=root, train=False, download=True, transform=transform)
if sys.platform.startswith('win'):
num_workers = 0 # 0表示不用额外的进程来加速读取数据
else:
num_workers = 4
train_iter = torch.utils.data.DataLoader(mnist_train, batch_size=batch_size, shuffle=True, num_workers=num_workers)
test_iter = torch.utils.data.DataLoader(mnist_test, batch_size=batch_size, shuffle=False, num_workers=num_workers)
return train_iter, test_iter
def train_ch3(net, train_iter, test_iter, loss, num_epochs, batch_size,
params=None, lr=None, optimizer=None):
for epoch in range(num_epochs):
train_l_sum, train_acc_sum, n = 0.0, 0.0, 0
for X, y in train_iter:
y_hat = net(X)
l = loss(y_hat, y).sum()
# 梯度清零
if optimizer is not None:
optimizer.zero_grad()
elif params is not None and params[0].grad is not None:
for param in params:
param.grad.data.zero_()
l.backward()
if optimizer is None:
sgd(params, lr, batch_size)
else:
optimizer.step() # “softmax回归的简洁实现”一节将用到
train_l_sum += l.item()
train_acc_sum += (y_hat.argmax(dim=1) == y).sum().item()
n += y.shape[0]
test_acc = evaluate_accuracy(test_iter, net)
print('epoch %d, loss %.4f, train acc %.3f, test acc %.3f'
% (epoch + 1, train_l_sum / n, train_acc_sum / n, test_acc))
train_iter, test_iter = load_data_fashion_mnist(batch_size)
train_ch3(net, train_iter, test_iter, loss, num_epochs, batch_size, params, lr)
以上为个人经验,希望能给大家一个参考,也希望大家多多支持hwidc。
【文章出处:黄石网站推广欢迎留下您的宝贵建议】