
pandas中DataFrame检测重复值的实现
本文详解如何使用pandas查看dataframe的重复数据,判断是否重复,以及如何去重
DataFrame.duplicated(subset=None, keep='first')
subset:如果你认为几个字段重复,则数据重复,就把那几个字段以列表形式放到subset后面。默认是所有字段重复为重复数据。
keep:
- 默认为'first' ,也就是如果有重复数据,则第一条出现的定义为False,后面的重复数据为True。
- 如果为'last',也就是如果有重复数据,则最后一条出现的定义为False,后面的重复数据为True。
- 如果为False,则所有重复的为True
下面举例
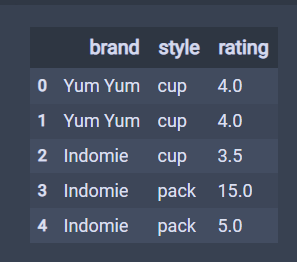
df = pd.DataFrame({
'brand': ['Yum Yum', 'Yum Yum', 'Indomie', 'Indomie', 'Indomie'],
'style': ['cup', 'cup', 'cup', 'pack', 'pack'],
'rating': [4, 4, 3.5, 15, 5]
})
df
# 默认为keep="first",第一条重复的为False,后面重复的为True # 一般不会设置keep,保持keep为默认值。 df.duplicated() 结果 0 False 1 True 2 False 3 False 4 False dtype: bool # keep="last",,最后一条重复的为False,后面重复的为True df.duplicated(keep="last") 结果 0 True 1 False 2 False 3 False 4 False dtype: bool # keep=False,,所有重复的为True df.duplicated(keep=False) 结果 0 True 1 True 2 False 3 False 4 False dtype: bool # sub是子,subset是子集 # 标记只要brand重复为重复值。 df.duplicated(subset='brand') 结果 0 False 1 True 2 False 3 True 4 True dtype: bool # 只要brand重复brand和style重复的为重复值。 df.duplicated(subset=['brand','style']) 结果 0 False 1 True 2 False 3 False 4 True dtype: bool # 显示重复记录,通过布尔索引 df[df.duplicated()]
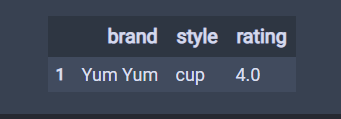
# 查询重复值的个数。 df.duplicated().sum() 结果 1
到此这篇关于pandas中DataFrame检测重复值的实现的文章就介绍到这了,更多相关pandas DataFrame检测重复值内容请搜索hwidc以前的文章或继续浏览下面的相关文章希望大家以后多多支持hwidc!
【本文转自:http://www.1234xp.com/jja.html 转载请说明出处】