
Python 循环读取数据内存不足的解决方案
看代码吧~
import gc
for x in list(locals().keys())[:]:
del locals()[x]
# del all_s_x, AE, AE_split, x_ticks, split
gc.collect()
补充:Python读取大文件的"坑“与内存占用检测
python读写文件的api都很简单,一不留神就容易踩”坑“。笔者记录一次踩坑历程,并且给了一些总结,希望到大家在使用python的过程之中,能够避免一些可能产生隐患的代码。
1.read()与readlines():
随手搜索python读写文件的教程,很经常看到read()与readlines()这对函数。所以我们会常常看到如下代码:
with open(file_path, 'rb') as f:
sha1Obj.update(f.read())
or
with open(file_path, 'rb') as f:
for line in f.readlines():
print(line)
这对方法在读取小文件时确实不会产生什么异常,但是一旦读取大文件,很容易会产生MemoryError,也就是内存溢出的问题。
Why Memory Error?
我们首先来看看这两个方法:
当默认参数size=-1时,read方法会读取直到EOF,当文件大小大于可用内存时,自然会发生内存溢出的错误。

同样的,readlines会构造一个list。list而不是iter,所以所有的内容都会保存在内存之上,同样也会发生内存溢出的错误。

2.正确的用法:
在实际运行的系统之中如果写出上述代码是十分危险的,这种”坑“十分隐蔽。所以接下来我们来了解一下正确用,正确的用法也很简单,依照API之中对函数的描述来进行对应的编码就OK了:
如果是二进制文件推荐用如下这种写法,可以自己指定缓冲区有多少byte。显然缓冲区越大,读取速度越快。
with open(file_path, 'rb') as f:
while True:
buf = f.read(1024)
if buf:
sha1Obj.update(buf)
else:
break
而如果是文本文件,则可以用readline方法或直接迭代文件(python这里封装了一个语法糖,二者的内生逻辑一致,不过显然迭代文件的写法更pythonic )每次读取一行,效率是比较低的。笔者简单测试了一下,在3G文件之下,大概性能和前者差了20%.
with open(file_path, 'rb') as f:
while True:
line = f.readline()
if buf:
print(line)
else:
break
with open(file_path, 'rb') as f:
for line in f:
print(line)
3.内存检测工具的介绍:
对于python代码的内存占用问题,对于代码进行内存监控十分必要。这里笔者这里推荐两个小工具来检测python代码的内存占用。
memory_profiler
首先先用pip安装memory_profiler
pip install memory_profiler
memory_profiler是利用python的装饰器工作的,所以我们需要在进行测试的函数上添加装饰器。
from hashlib import sha1
import sys
@profile
def my_func():
sha1Obj = sha1()
with open(sys.argv[1], 'rb') as f:
while True:
buf = f.read(10 * 1024 * 1024)
if buf:
sha1Obj.update(buf)
else:
break
print(sha1Obj.hexdigest())
if __name__ == '__main__':
my_func()
之后在运行代码时加上** -m memory_profiler**
就可以了解函数每一步代码的内存占用了
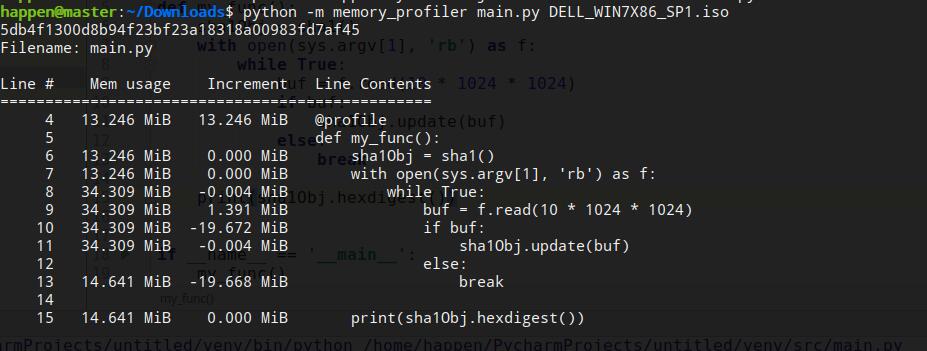
guppy
依样画葫芦,仍然是通过pip先安装guppy
pip install guppy
之后可以在代码之中利用guppy直接打印出对应各种python类型(list、tuple、dict等)分别创建了多少对象,占用了多少内存。
from guppy import hpy
import sys
def my_func():
mem = hpy()
with open(sys.argv[1], 'rb') as f:
while True:
buf = f.read(10 * 1024 * 1024)
if buf:
print(mem.heap())
else:
break
如下图所示,可以看到打印出对应的内存占用数据:
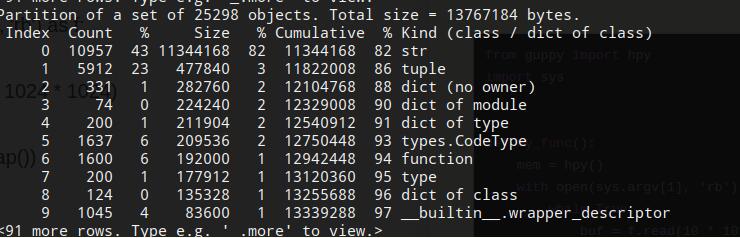
通过上述两种工具guppy与memory_profiler可以很好地来监控python代码运行时的内存占用问题。
4.小结:
python是一门崇尚简洁的语言,但是正是因为它的简洁反而更多了许多需要仔细推敲和思考的细节。希望大家在日常工作与学习之中也能多对一些细节进行总结,少踩一些不必要的“坑”。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持hwidc。