
浅谈Python numpy创建空数组的问题
目录
- 一、问题描述:
- 二、具体的实现:
- 三、完整代码:
一、问题描述:
有一个shape为(308, 2)的二维数组,以及单独的一个数字,需要保存到csv文件中,这个单独的数字让其保存到第3列第一行的位置。
二、具体的实现:
首先要想把一个(308, 2)的二维数组和一个数字给拼接起来,直接拼接没办法实现,因为行数和列数都不同的两个ndarry是无法拼接的(此处按照目前我学的理解,是无法直接拼接的,如果可以的话,麻烦评论一下)。
然后我首先想到的解决方法就是先建一个(308,1)的二维数组,然后令这个二维数组的第一个元素设置成那个数字,然后进行拼接,保存。
为使数据可以显示完全,以仅以3行数据为例:
>>> a = np.ones((3,2)) >>> b = 0.2 >>> _b = np.empty((3,1)) >>> _b[0, 0] = b >>> c = np.c_[a, _b] >>> print(c) [[1.00000000e+000 1.00000000e+000 2.00000000e-001] [1.00000000e+000 1.00000000e+000 2.12199579e-313] [1.00000000e+000 1.00000000e+000 2.54639495e-313]] >>>
但是这样,我把结果保存到文件时,第3列的除第一行,其他的行是有数据的,我不想让它显示数据。
也就是empty这个函数只是创建一个未初始化的数组,实际上里面的数值都是垃圾值。
那么如何去实现视觉上没有数据呢,其实利用空的字符串就可以了。
所以就通过np.ones设置dtype为str,此时生成的是元素都为空字符串的数组,(具体的原因还不清楚),然后此时若直接设置第一行的元素为某个值,是不行的,会自动变为'0‘,只有在拼接之后,然后再给它赋值才可以,这个地方我不是很理解,但是结果是正确的。
三、完整代码:
y_true = np.ones((3, 1), dtype=np.int)
y_pred = np.ones((3, 1), dtype=np.int)
y = np.c_[y_true, y_pred]
accuracy = np.zeros(shape=(y_true.shape[0], 1), dtype=np.str)
# 此时若设置accuracy[0, 0] = '0.89',最终accuracy[0, 0]存的是'0',具体原因还不清楚
res = np.c_[y, accuracy] # 先拼接起来
res[0, 2] = '0.89' # 然后再设置就可以了
res = pd.DataFrame(res, columns=['y_true', 'y_pred', 'accuracy'])
res.to_csv('1.csv') # 保存到文件中
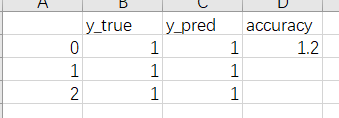
从文件中读取的时候,直接读出来,空白的地方被赋值为nan
a = pd.read_csv('1.csv', usecols=(1, 2, 3))
a = a.values
print(a, type(a), a.dtype)

关于np.nan需要注意的地方如下:
- np.nan不是空对象。
- 对列表中的nan进行操作时不能用"==np.nan"来判断。只能用np.isnan()来操作。
- np.nan的数据类型是float。
import numpy as np np.nan == np.nan Out[3]: False aa = np.array([1,2,3,np.nan,np.nan,4,5,np.nan]) aa Out[5]: array([ 1., 2., 3., nan, nan, 4., 5., nan]) aa[aa==np.nan] = 100 #错误方式 aa Out[7]: array([ 1., 2., 3., nan, nan, 4., 5., nan]) aa[np.isnan(aa)] = 100 #对nan操作的正确方式 aa Out[9]: array([ 1., 2., 3., 100., 100., 4., 5., 100.]) type(np.nan) Out[10]: float
关于参考:https://www.jb51.net/article/212249.htm
到此这篇关于浅谈Python numpy创建空数组的问题的文章就介绍到这了,更多相关numpy创建空数组内容请搜索hwidc以前的文章或继续浏览下面的相关文章希望大家以后多多支持hwidc!