
pyspark创建DataFrame的几种方法
目录
- pyspark创建DataFrame
- RDD和DataFrame
- 使用二元组创建DataFrame
- 使用键值对创建DataFrame
- 使用rdd创建DataFrame
- 基于rdd和ROW创建DataFrame
- 基于rdd和StructType创建DataFrame
- 基于pandas DataFrame创建pyspark DataFrame
- 创建有序的DataFrame
- 配置DataFrame和临时表
- 创建DataFrame时指定列类型
- 注册DataFrame为临时表
- 获取和修改配置
- 注册自定义函数
- 查看临时表列表
- 从其他数据源创建DataFrame
- MySQL
pyspark创建DataFrame
为了便于操作,使用pyspark时我们通常将数据转为DataFrame的形式来完成清洗和分析动作。
RDD和DataFrame
在上一篇pyspark基本操作有提到RDD也是spark中的操作的分布式数据对象。
这里简单看一下RDD和DataFrame的类型。
print(type(rdd)) # <class 'pyspark.rdd.RDD'> print(type(df)) # <class 'pyspark.sql.dataframe.DataFrame'>
翻阅了一下源码的定义,可以看到他们之间并没有继承关系。
class RDD(object):
"""
A Resilient Distributed Dataset (RDD), the basic abstraction in Spark.
Represents an immutable, partitioned collection of elements that can be
operated on in parallel.
"""
class DataFrame(object):
"""A distributed collection of data grouped into named columns.
A :class:`DataFrame` is equivalent to a relational table in Spark SQL,
and can be created using various functions in :class:`SparkSession`::
...
"""
RDD是一种弹性分布式数据集,Spark中的基本抽象。表示一种不可变的、分区储存的集合,可以进行并行操作。
DataFrame是一种以列对数据进行分组表达的分布式集合, DataFrame等同于Spark SQL中的关系表。相同点是,他们都是为了支持分布式计算而设计。
但是RDD只是元素的集合,但是DataFrame以列进行分组,类似于MySQL的表或pandas中的DataFrame。
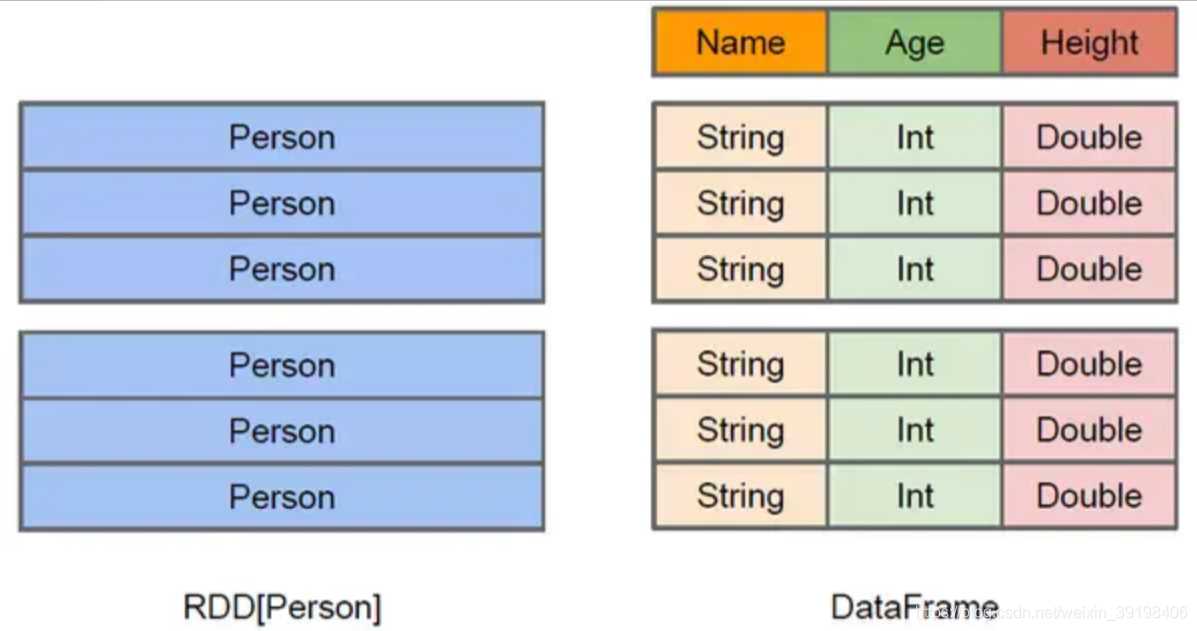
实际工作中,我们用的更多的还是DataFrame。
使用二元组创建DataFrame
尝试第一种情形发现,仅仅传入二元组,结果是没有列名称的。
于是我们尝试第二种,同时传入二元组和列名称。
a = [('Alice', 1)]
output = spark.createDataFrame(a).collect()
print(output)
# [Row(_1='Alice', _2=1)]
output = spark.createDataFrame(a, ['name', 'age']).collect()
print(output)
# [Row(name='Alice', age=1)]
这里collect()是按行展示数据表,也可以使用show()对数据表进行展示。
spark.createDataFrame(a).show() # +-----+---+ # | _1| _2| # +-----+---+ # |Alice| 1| # +-----+---+ spark.createDataFrame(a, ['name', 'age']).show() # +-----+---+ # | name|age| # +-----+---+ # |Alice| 1| # +-----+---+
使用键值对创建DataFrame
d = [{'name': 'Alice', 'age': 1}]
output = spark.createDataFrame(d).collect()
print(output)
# [Row(age=1, name='Alice')]
使用rdd创建DataFrame
a = [('Alice', 1)]
rdd = sc.parallelize(a)
output = spark.createDataFrame(rdd).collect()
print(output)
output = spark.createDataFrame(rdd, ["name", "age"]).collect()
print(output)
# [Row(_1='Alice', _2=1)]
# [Row(name='Alice', age=1)]
基于rdd和ROW创建DataFrame
from pyspark.sql import Row
a = [('Alice', 1)]
rdd = sc.parallelize(a)
Person = Row("name", "age")
person = rdd.map(lambda r: Person(*r))
output = spark.createDataFrame(person).collect()
print(output)
# [Row(name='Alice', age=1)]
基于rdd和StructType创建DataFrame
from pyspark.sql.types import *
a = [('Alice', 1)]
rdd = sc.parallelize(a)
schema = StructType(
[
StructField("name", StringType(), True),
StructField("age", IntegerType(), True)
]
)
output = spark.createDataFrame(rdd, schema).collect()
print(output)
# [Row(name='Alice', age=1)]
基于pandas DataFrame创建pyspark DataFrame
df.toPandas()可以把pyspark DataFrame转换为pandas DataFrame。
df = spark.createDataFrame(rdd, ['name', 'age']) print(df) # DataFrame[name: string, age: bigint] print(type(df.toPandas())) # <class 'pandas.core.frame.DataFrame'> # 传入pandas DataFrame output = spark.createDataFrame(df.toPandas()).collect() print(output) # [Row(name='Alice', age=1)]
创建有序的DataFrame
output = spark.range(1, 7, 2).collect() print(output) # [Row(id=1), Row(id=3), Row(id=5)] output = spark.range(3).collect() print(output) # [Row(id=0), Row(id=1), Row(id=2)]
通过临时表得到DataFrame
spark.registerDataFrameAsTable(df, "table1")
df2 = spark.table("table1")
b = df.collect() == df2.collect()
print(b)
# True
配置DataFrame和临时表
创建DataFrame时指定列类型
在createDataFrame中可以指定列类型,只保留满足数据类型的列,如果没有满足的列,会抛出错误。
a = [('Alice', 1)]
rdd = sc.parallelize(a)
# 指定类型于预期数据对应时,正常创建
output = spark.createDataFrame(rdd, "a: string, b: int").collect()
print(output) # [Row(a='Alice', b=1)]
rdd = rdd.map(lambda row: row[1])
print(rdd) # PythonRDD[7] at RDD at PythonRDD.scala:53
# 只有int类型对应上,过滤掉其他列。
output = spark.createDataFrame(rdd, "int").collect()
print(output) # [Row(value=1)]
# 没有列能对应上,会抛出错误。
output = spark.createDataFrame(rdd, "boolean").collect()
# TypeError: field value: BooleanType can not accept object 1 in type <class 'int'>
注册DataFrame为临时表
spark.registerDataFrameAsTable(df, "table1")
spark.dropTempTable("table1")
获取和修改配置
print(spark.getConf("spark.sql.shuffle.partitions")) # 200
print(spark.getConf("spark.sql.shuffle.partitions", u"10")) # 10
print(spark.setConf("spark.sql.shuffle.partitions", u"50")) # None
print(spark.getConf("spark.sql.shuffle.partitions", u"10")) # 50
注册自定义函数
spark.registerFunction("stringLengthString", lambda x: len(x))
output = spark.sql("SELECT stringLengthString('test')").collect()
print(output)
# [Row(stringLengthString(test)='4')]
spark.registerFunction("stringLengthString", lambda x: len(x), IntegerType())
output = spark.sql("SELECT stringLengthString('test')").collect()
print(output)
# [Row(stringLengthString(test)=4)]
spark.udf.register("stringLengthInt", lambda x: len(x), IntegerType())
output = spark.sql("SELECT stringLengthInt('test')").collect()
print(output)
# [Row(stringLengthInt(test)=4)]
查看临时表列表
可以查看所有临时表名称和对象。
spark.registerDataFrameAsTable(df, "table1")
print(spark.tableNames()) # ['table1']
print(spark.tables()) # DataFrame[database: string, tableName: string, isTemporary: boolean]
print("table1" in spark.tableNames()) # True
print("table1" in spark.tableNames("default")) # True
spark.registerDataFrameAsTable(df, "table1")
df2 = spark.tables()
df2.filter("tableName = 'table1'").first()
print(df2) # DataFrame[database: string, tableName: string, isTemporary: boolean]
从其他数据源创建DataFrame
MySQL
前提是需要下载jar包。
Mysql-connector-java.jar
from pyspark import SparkContext
from pyspark.sql import SQLContext
import pyspark.sql.functions as F
sc = SparkContext("local", appName="mysqltest")
sqlContext = SQLContext(sc)
df = sqlContext.read.format("jdbc").options(
url="jdbc:mysql://localhost:3306/mydata?user=root&password=mysql&"
"useUnicode=true&characterEncoding=utf-8&useJDBCCompliantTimezoneShift=true&"
"useLegacyDatetimeCode=false&serverTimezone=UTC ", dbtable="detail_data").load()
df.show(n=5)
sc.stop()
参考
RDD和DataFrame的区别
spark官方文档 翻译 之pyspark.sql.SQLContext
到此这篇关于pyspark创建DataFrame的几种方法的文章就介绍到这了,更多相关pyspark创建DataFrame 内容请搜索hwidc以前的文章或继续浏览下面的相关文章希望大家以后多多支持hwidc!
【本文转自:潜江网站推广 网络转载请说明出处】