
Pandas||过滤缺失数据||pd.dropna()函数的用法说明
看代码吧~
DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False) Remove missing values.
pd.dropna()函数(官方文档)用于过滤数据中的缺失数据.
缺失数据在pandas中用NaN标记.
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randn(5, 3), index = list('abcde'), columns = ['one', 'two', 'three']) # 随机产生5行3列的数据
df.ix[1, :-1] = np.nan # 将指定数据定义为缺失
df.ix[1:-1, 2] = np.nan
print(df)
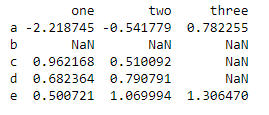
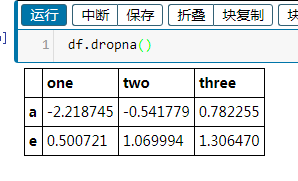
df.dropna() #删除所有带缺失数据的行
补充:Python-pandas的dropna()方法-丢弃含空值的行、列
0.摘要
dropna()方法,能够找到DataFrame类型数据的空值(缺失值),将空值所在的行/列删除后,将新的DataFrame作为返回值返回。
1.函数详解
函数形式:dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
参数:
axis:轴。0或'index',表示按行删除;1或'columns',表示按列删除。
how:筛选方式。‘any',表示该行/列只要有一个以上的空值,就删除该行/列;‘all',表示该行/列全部都为空值,就删除该行/列。
thresh:非空元素最低数量。int型,默认为None。如果该行/列中,非空元素数量小于这个值,就删除该行/列。
subset:子集。列表,元素为行或者列的索引。如果axis=0或者‘index',subset中元素为列的索引;如果axis=1或者‘column',subset中元素为行的索引。由subset限制的子区域,是判断是否删除该行/列的条件判断区域。
inplace:是否原地替换。布尔值,默认为False。如果为True,则在原DataFrame上进行操作,返回值为None。
2.示例
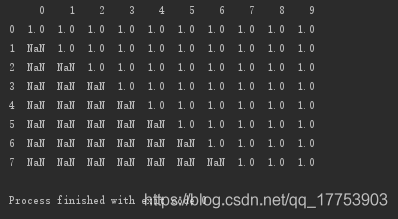
创建DataFrame数据:
import numpy as np
import pandas as pd
a = np.ones((11,10))
for i in range(len(a)):
a[i,:i] = np.nan
d = pd.DataFrame(data=a)
print(d)
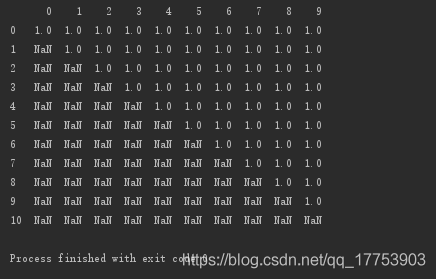
按行删除:存在空值,即删除该行
# 按行删除:存在空值,即删除该行 print(d.dropna(axis=0, how='any'))
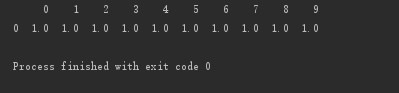
按行删除:所有数据都为空值,即删除该行
# 按行删除:所有数据都为空值,即删除该行 print(d.dropna(axis=0, how='all'))
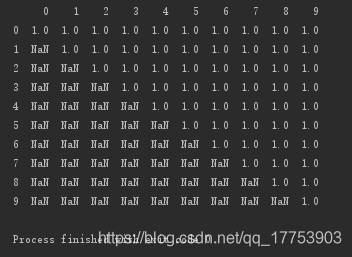
按列删除:该列非空元素小于5个的,即删除该列
# 按列删除:该列非空元素小于5个的,即删除该列 print(d.dropna(axis='columns', thresh=5))
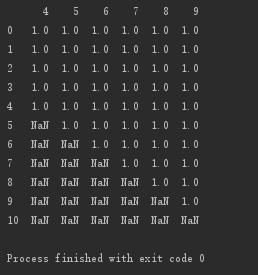
设置子集:删除第0、5、6、7列都为空的行
# 设置子集:删除第0、5、6、7列都为空的行 print(d.dropna(axis='index', how='all', subset=[0,5,6,7]))
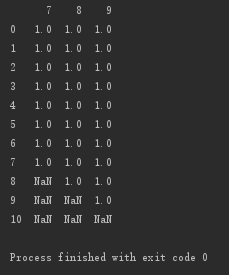
设置子集:删除第5、6、7行存在空值的列
# 设置子集:删除第5、6、7行存在空值的列 print(d.dropna(axis=1, how='any', subset=[5,6,7]))
原地修改
# 原地修改
print(d.dropna(axis=0, how='any', inplace=True))
print("==============================")
print(d)
以上为个人经验,希望能给大家一个参考,也希望大家多多支持hwidc。