
pytorch 如何打印网络回传梯度
需求:
打印梯度,检查网络学习情况
net = your_network().cuda()
def train():
...
outputs = net(inputs)
loss = criterion(outputs, targets)
loss.backward()
for name, parms in net.named_parameters():
print('-->name:', name, '-->grad_requirs:',parms.requires_grad, \
' -->grad_value:',parms.grad)
...
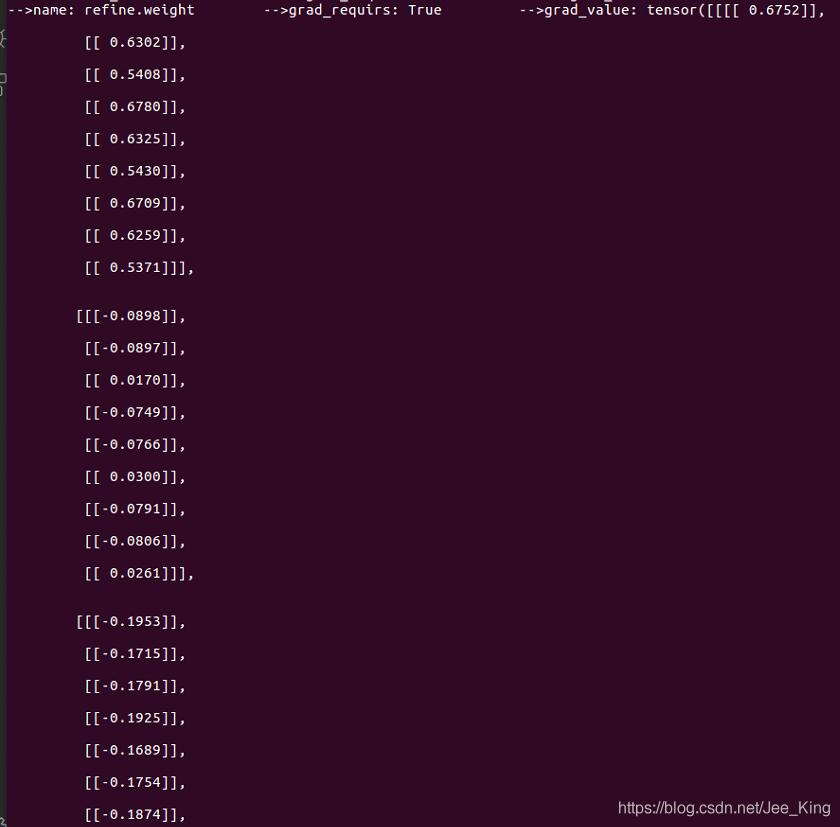
打印结果如下:
name表示网络参数的名字; parms.requires_grad 表示该参数是否可学习,是不是frozen的; parm.grad 打印该参数的梯度值。
补充:pytorch的梯度计算
看代码吧~
import torch
from torch.autograd import Variable
x = torch.Tensor([[1.,2.,3.],[4.,5.,6.]]) #grad_fn是None
x = Variable(x, requires_grad=True)
y = x + 2
z = y*y*3
out = z.mean()
#x->y->z->out
print(x)
print(y)
print(z)
print(out)
#结果:
tensor([[1., 2., 3.],
[4., 5., 6.]], requires_grad=True)
tensor([[3., 4., 5.],
[6., 7., 8.]], grad_fn=<AddBackward>)
tensor([[ 27., 48., 75.],
[108., 147., 192.]], grad_fn=<MulBackward>)
tensor(99.5000, grad_fn=<MeanBackward1>)
若是关于graph leaves求导的结果变量是一个标量,那么gradient默认为None,或者指定为“torch.Tensor([1.0])”
若是关于graph leaves求导的结果变量是一个向量,那么gradient是不能缺省的,要是和该向量同纬度的tensor
out.backward()
print(x.grad)
#结果:
tensor([[3., 4., 5.],
[6., 7., 8.]])
#如果是z关于x求导就必须指定gradient参数:
gradients = torch.Tensor([[2.,1.,1.],[1.,1.,1.]])
z.backward(gradient=gradients)
#若z不是一个标量,那么就先构造一个标量的值:L = torch.sum(z*gradient),再关于L对各个leaf Variable计算梯度
#对x关于L求梯度
x.grad
#结果:
tensor([[36., 24., 30.],
[36., 42., 48.]])
错误情况
z.backward()
print(x.grad)
#报错:RuntimeError: grad can be implicitly created only for scalar outputs只能为标量创建隐式变量
x1 = Variable(torch.Tensor([[1.,2.,3.],[4.,5.,6.]]))
x2 = Variable(torch.arange(4).view(2,2).type(torch.float), requires_grad=True)
c = x2.mm(x1)
c.backward(torch.ones_like(c))
# c.backward()
#RuntimeError: grad can be implicitly created only for scalar outputs
print(x2.grad)
从上面的例子中,out是常量,可以默认创建隐变量,如果反向传播的不是常量,要知道该矩阵的具体值,在网络中就是loss矩阵,方向传播的过程中就是拿该归一化的损失乘梯度来更新各神经元的参数。
看到一个博客这样说:loss = criterion(outputs, labels)对应loss += (label[k] - h) * (label[k] - h) / 2
就是求loss(其实我觉得这一步不用也可以,反向传播时用不到loss值,只是为了让我们知道当前的loss是多少)
我认为一定是要求loss的具体值,才能对比阈值进行分类,通过非线性激活函数,判断是否激活。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持hwidc。