
Python 统计列表中重复元素的个数并返回其索引值
需求:统计列表list1中元素3的个数,并返回每个元素的索引
list1 = [3, 3, 8, 9, 2, 10, 6, 2, 8, 3, 4, 5, 5, 4, 1, 5, 9, 7, 10, 2]
在实际工程中,可能会遇到以上需求,统计元素个数使用list.count()方法即可,不做多余说明
返回每个元素的索引需要做一些转换,简单整理了几个实现方法
1 list.index()方法
list.index()方法返回列表中首个元素的索引,当有重复元素时,可以通过更改index()方法__start参数来更改起始索引
找到一个元素后,将起始索引替换为该元素的下一个索引,继续进行查找,直到找到所有的元素索引
list1 = [3, 3, 8, 9, 2, 10, 6, 2, 8, 3, 4, 5, 5, 4, 1, 5, 9, 7, 10, 2]
count = list1.count(3)
index_list = []
index = -1
# 通过list.index()方法的__start参数,指定起始索引
for i in range(0, count):
index = list1.index(3, index + 1)
index_list.append(index)
print(index_list)
结果如下:
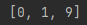
2 通过索引遍历原列表,对每一个元素进行判断
通过索引遍历原列表,对每一个元素进行判断,如果元素是目标元素,则返回对应索引值,示例如下:
list1 = [3, 3, 8, 9, 2, 10, 6, 2, 8, 3, 4, 5, 5, 4, 1, 5, 9, 7, 10, 2]
list1_len = len(list1)
index_list = []
for i in range(0, list1_len):
if list1[i] == 3:
index_list.append(i)
print(index_list)
结果同上
3 enumerate()函数和列表推导式
使用enumerate()函数返回可解析的index-value列表,然后使用列表推导式,同时使用if条件过滤得到目标值的索引,示例如下:
list1 = [3, 3, 8, 9, 2, 10, 6, 2, 8, 3, 4, 5, 5, 4, 1, 5, 9, 7, 10, 2] index_list = [a for a, b in enumerate(list1) if b == 3] print(index_list)
结果同上
各位大佬有好的实现方法可以在下方评论分享一下
到此这篇关于Python 统计列表中重复元素的个数并返回其索引值的文章就介绍到这了,更多相关Python 统计列表元素内容请搜索hwidc以前的文章或继续浏览下面的相关文章希望大家以后多多支持hwidc!