
windows下pycharm搭建spark环境并成功运行 附源码
windows下spark的安装和运行 建议看到这篇文章(描述非常详细)
Spark在Win10下的环境搭建
一、创建项目和.py文件
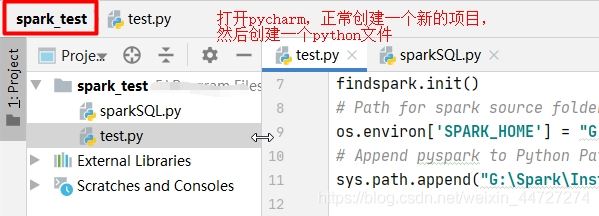
二、在pycharm中添加spark环境
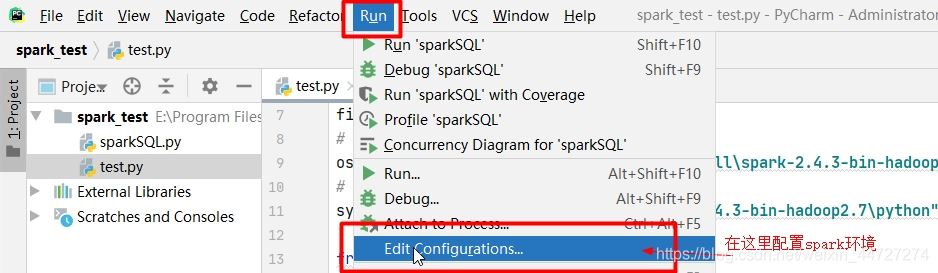
若是左侧的python中没有,可点击‘'+‘'号进行添加
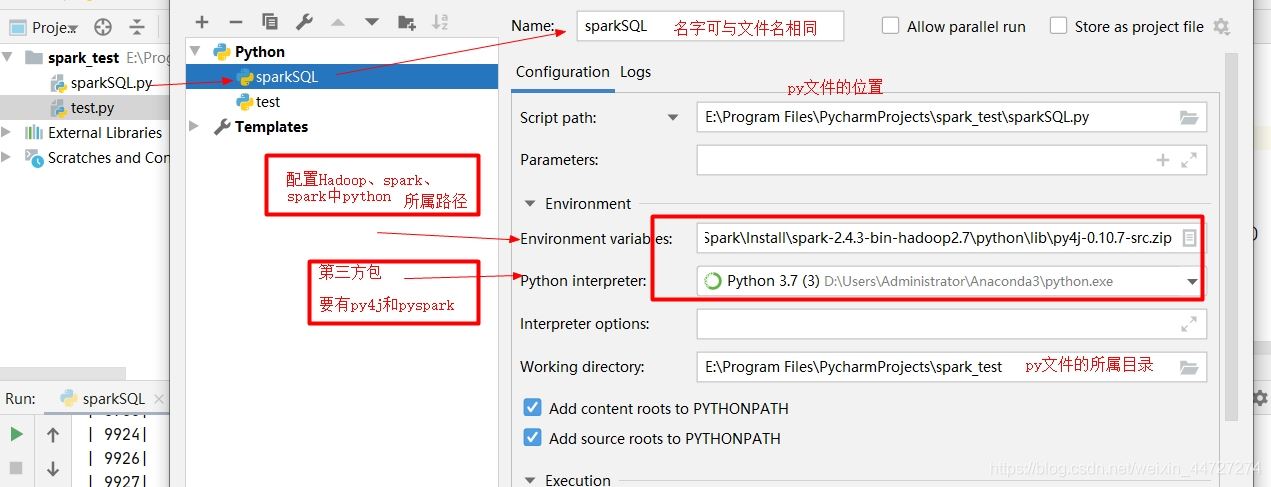
配置spark环境:总共3个(SPARK_HOME、HADOOP_HOME、PYTHONPATH)
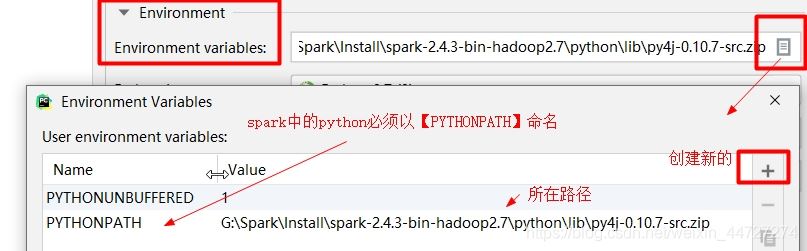


(注:SPARK_HOME和HADOOP_HOME已在系统的环境变量添加,故这里不再添加)
在编写代码时,建议添加如下代码,保证程序能够运行成功:
import os
import sys
import findspark # 一定要在最前面导入
'''初始化spark环境'''
findspark.init()
# Path for spark source folder
os.environ['SPARK_HOME'] = "G:\Spark\Install\spark-2.4.3-bin-hadoop2.7"
# Append pyspark to Python Path
sys.path.append("G:\Spark\Install\spark-2.4.3-bin-hadoop2.7\python")
'''示例'''
from pyspark import SparkContext,SparkConf
from pyspark.sql import SparkSession
from pyspark.sql import Row
# SparkContext是spark功能的主要入口
sc = SparkContext("local", "app")
RawSalesDataRDD = sc.textFile("G:\\Spark\\作业\\taxi.csv")
print(RawSalesDataRDD.take(5))
salesRDD = RawSalesDataRDD.map(lambda line: line.split(","))
print(salesRDD.take(5))
taxi_Rows = salesRDD.map(lambda p:
Row(
id=p[0],
lat=p[1],
lon=p[2],
time=p[3]
))
sqlContext = SparkSession.builder.getOrCreate()
taxi_df = sqlContext.createDataFrame(taxi_Rows)
print(taxi_Rows.take(5))
print('查看dataframe的字段名称和前5行数据:')
taxi_df.printSchema()
taxi_df.show(5)
'''使用SQL语句 操作表数据'''
# #创建临时表taxi_table
taxi_df.registerTempTable("taxi_table")
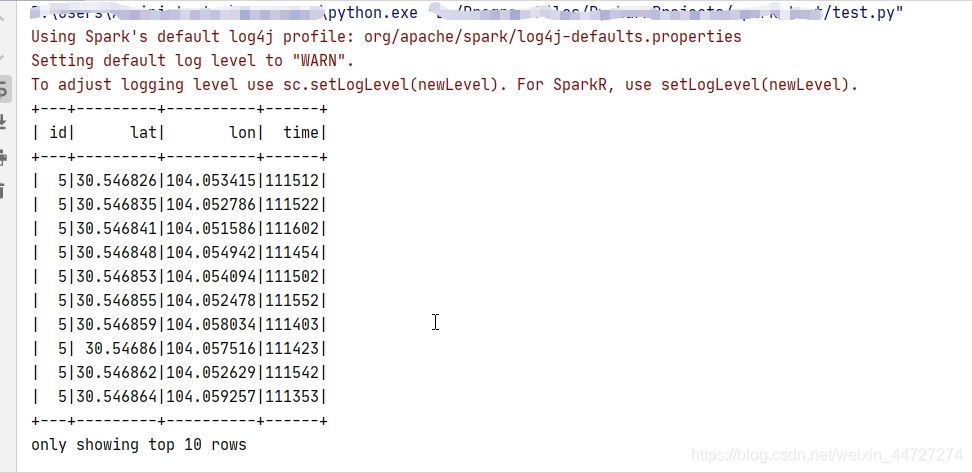
# 查询编号为 5 的出租车的 GPS 数据的前 10 行
taxi_df.filter("id='5'").show(10)
taxi_df.where("id='5'").show(10)
sqlContext.sql("select * from taxi_table where id='5'").show(10)
代码运行结果:

到此这篇关于windows下pycharm搭建spark环境并成功运行 附源码的文章就介绍到这了,更多相关pycharm搭建spark环境内容请搜索hwidc以前的文章或继续浏览下面的相关文章希望大家以后多多支持hwidc!