
Python实战之单词打卡统计
前言
观前提醒:因为是代码控制统计,所以操作每一个步骤都很重要,否则就会报错。
操作步骤
1.将在线编辑文档导入本地。
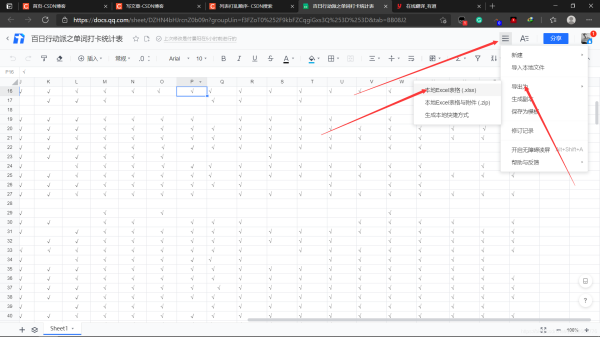
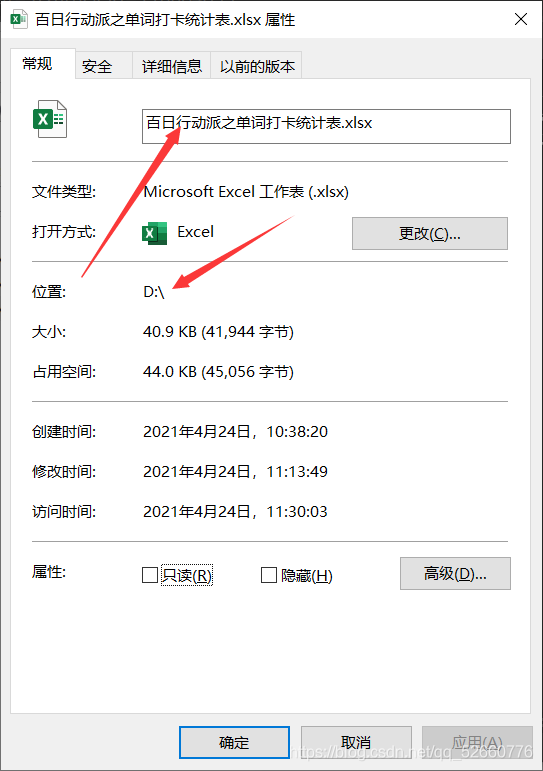
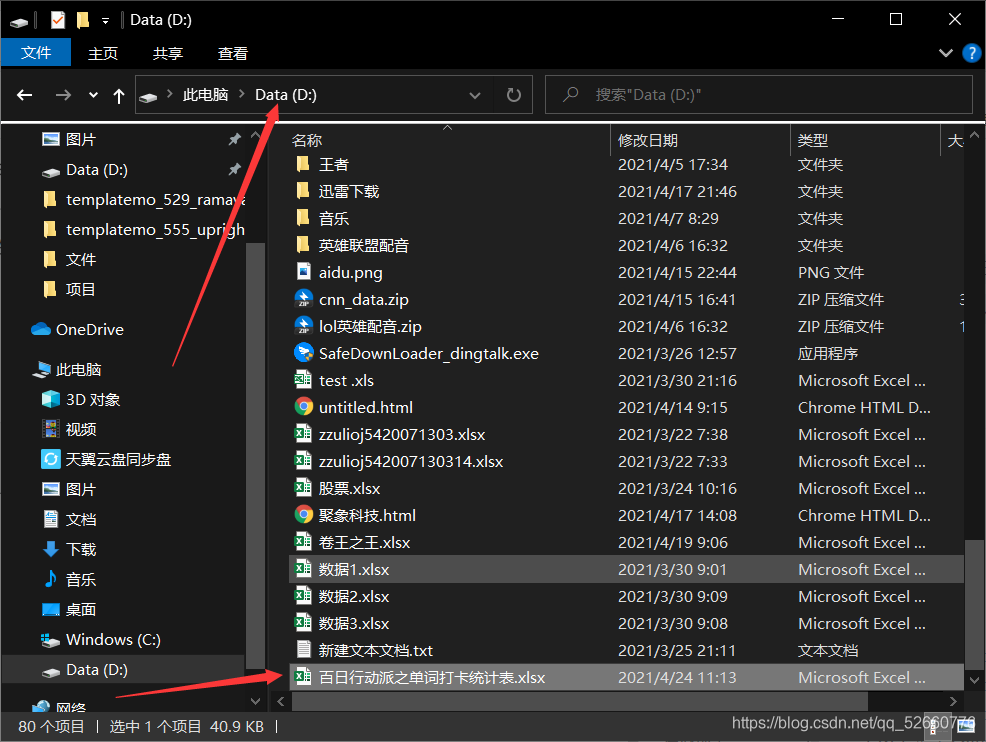
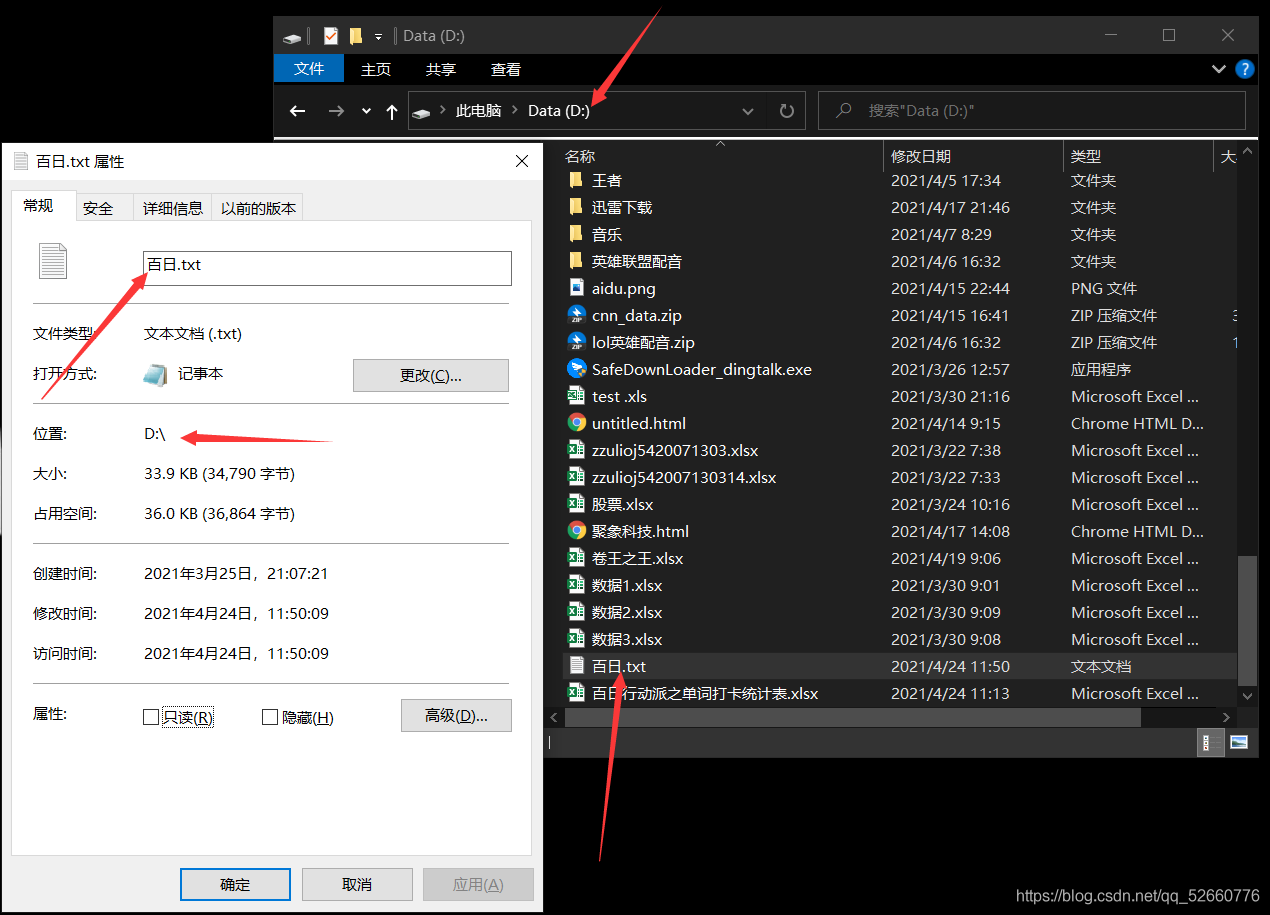
为了方便代码处理,将导出的excel表统一放在D盘直路径下,如果没懂,你可以查看文件属性,文件属性应该是这样:
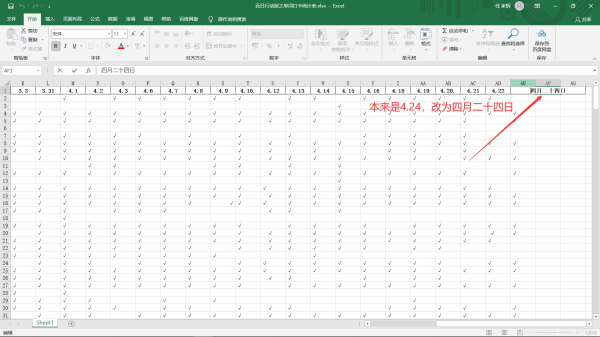
2.打开excel表,将你要统计的那天的日期改为中文(这一步很重要,因为数字索引无法进行定位,所以要改,不改就用不了)
3.因为QQ的安全防范机制做的太好了,爬虫和抓包工具都无法获取QQ信息,所以我只能采用最原始的方法进行数据获取。
你想的没错,就是复制粘贴。用电脑打开百日单词打卡群的相册
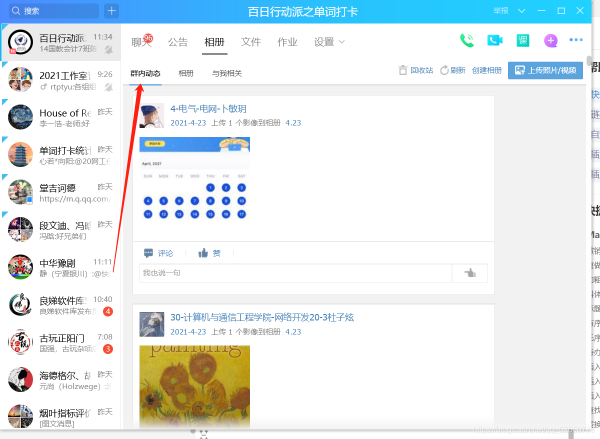
滑动滚轮,加载出统计日的所有上传信息,然后CTRL+A全选,CTRL+C复制。
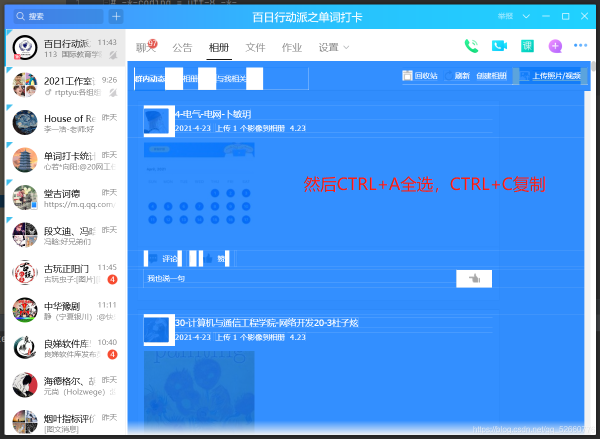
4.在D盘下,新建一个名字为:百日.txt 的文件将刚才复制的内容放进去。
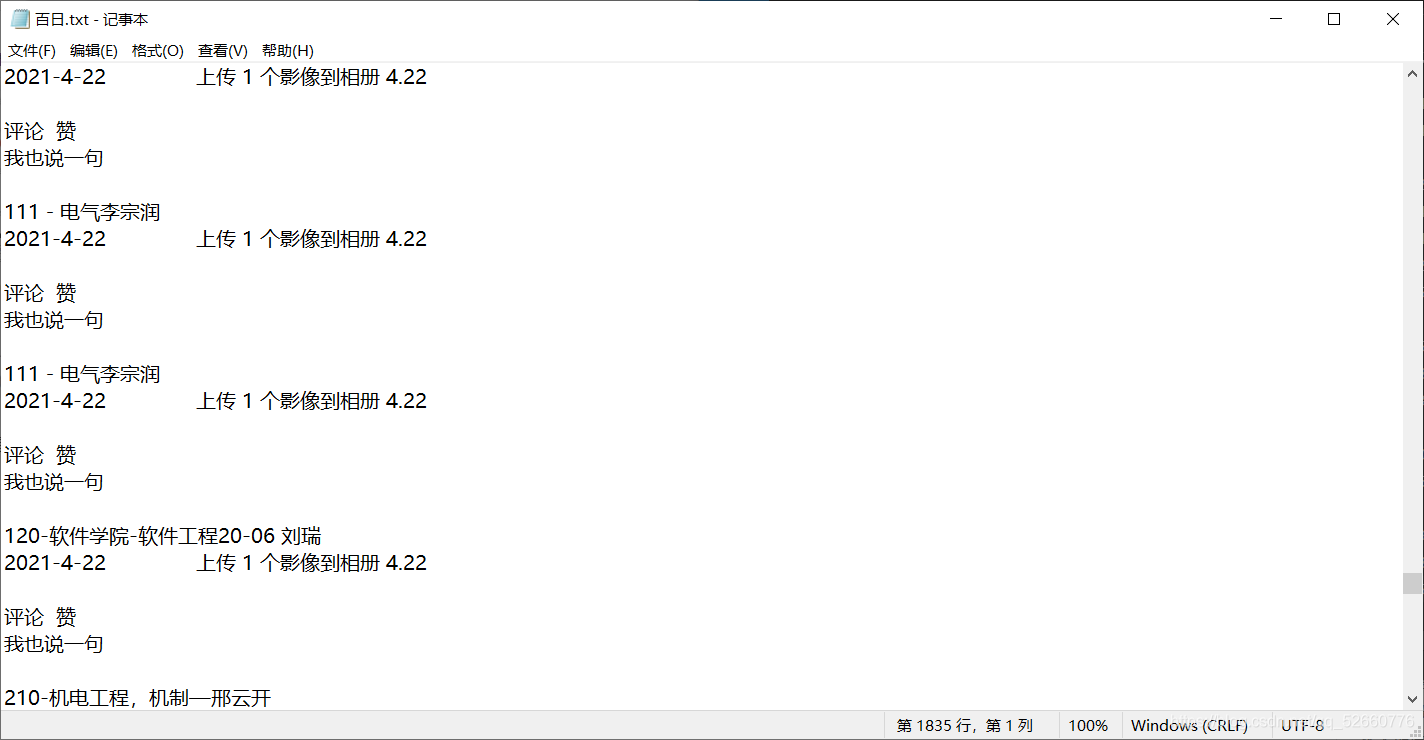
5.运行代码。所有上传过背单词图片的人,就都在excel表里打上”√“了,但是为了防止有人想蒙混过关,我们再去相册里大致浏览一下,找到不合格的然后在excel表里去除”√“,但总的来说这样的情况还是极少数。
6.为了让excel表里的格式保持一致,打开编辑好的excel表,然后将汉语日期再改回4.24格式。
7.将统计好的excel表上传。
8.源代码:
# -*-coding = utf-8 -*-
# @Time:2021/4/24/10:40
# @Author:seven
# @File:自填.py
# @Software:PyCharm
import pandas as pd
import re
day=input("请输入你要统计的日期(例:4.23):")
DAY=input("请输入的更改后的列名(例:四月二十三日):")
findlink=re.compile("赞我也说一句.*?([\u4e00-\u9fa5]{3})2021-.*? 上传 1 个影像到相册 "+day)
with open("D:/百日.txt","r",encoding="utf-8") as fd:
a=fd.readlines()
w=''
for i in a:
i=i.strip()
w+=i
names=re.findall(findlink,w)
path="D:/百日行动派之单词打卡统计表.xlsx"
df=pd.read_excel(path,engine="openpyxl")
name=df.loc[0:,"姓名"]
day=df.loc[0:,DAY]
days=[]
for i in day:
days.append(i)
namelist=[]
for i in name:
namelist.append(i)
list=[]
for i in names:
try:
n=namelist.index(i)
list.append(n)
except:
print(i)
for i in list:
days[i]="√"
df.loc[0:,"四月二十四日"]=days
df.to_excel(path)
w=input("以上同学因备注格式不符未能自动统计,请自行统计")
9.如果你有使用python,可以打开编译器导入相关库后运行代码,如果你没有python,可以使用封装后的程序。
到此这篇关于Python实战之单词打卡统计的文章就介绍到这了,更多相关python单词打卡统计内容请搜索hwidc以前的文章或继续浏览下面的相关文章希望大家以后多多支持hwidc!
【文章原创作者:http://www.1234xp.com/ip.html 转载请保留连接】