
Python自然语言处理之切分算法详解
目录
- 一、前言
- 二、完全切分
- 三、正向最长匹配
- 四、逆向最长匹配
- 五、双向最长匹配
一、前言
我们需要分析某句话,就必须检测该条语句中的词语。
一般来说,一句话肯定包含多个词语,它们互相重叠,具体输出哪一个由自然语言的切分算法决定。常用的切分算法有完全切分、正向最长匹配、逆向最长匹配以及双向最长匹配。
本篇博文将一一介绍这些常用的切分算法。
二、完全切分
完全切分是指,找出一段文本中的所有单词。
不考虑效率的话,完全切分算法其实非常简单。只要遍历文本中的连续序列,查询该序列是否在词典中即可。上一篇我们获取了词典的所有词语dic,这里我们直接用代码遍历某段文本,完全切分出所有的词语。代码如下:
from pyhanlp import *
def load_dictionary():
IOUtil = JClass('com.hankcs.hanlp.corpus.io.IOUtil')
path = HanLP.Config.CoreDictionaryPath.replace('.txt', '.mini.txt')
dic = IOUtil.loadDictionary([path])
return set(dic.keySet())
def fully_segment(text, dic):
list = []
for i in range(len(text)):
for j in range(i + 1, len(text) + 1):
temp = text[i:j]
if temp in dic:
list.append(temp)
return list
if __name__ == "__main__":
dic = load_dictionary()
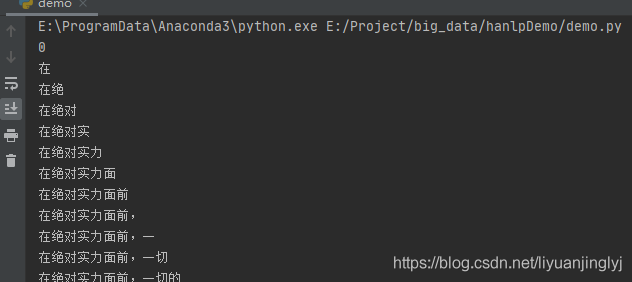
print(fully_segment("在绝对实力面前,一切的说辞都是枉然", dic))

可以看到,完全切分算法输出了文本中所有的单字与词汇。
这里的算法原理是:开始遍历单个字,以该字为首,将后面每个字依次组合到单个字中,分析出这些组合字句是否在词典中。第二次,从第二个字开始,组合后面的字,以此类推。不懂的看下图就明白了。
三、正向最长匹配
虽然说完全切分能获取到所有出现在字典中的单词,单字,但是我们获取语句中单字一般来说没有任何意义,我们更希望获取的是中文分词,那种具有意义的词语序列。
比如,上面我们希望“绝对实力”成为一整个词,而不是“绝对”+“实力”之类的碎片。为了达到这个目的,我们需要完善一下我们的算法。考虑到越长的单词表达的意义更加的丰富,于是我们定义单词越长优先级越高。
具体来说,就是在某个下标为起点递增查词的过程中,优先输出更长的单词,这种规则被称为最长匹配算法。该下标的扫描顺序如果从前往后,则称为正向最长匹配,反之则为逆向最长匹配。
下面,我们来实现正向最长匹配,代码如下:
def forward_segment(text, dic):
list = []
i = 0
while i < len(text):
long_word = text[i]
for j in range(i + 1, len(text) + 1):
word = text[i:j]
if word in dic:
if len(word) > len(long_word):
long_word = word
list.append(long_word)
i += len(long_word)
return list
算法的原理:首先通过while循环判断i是否超出了字符串的大小,如果没有,获取当前第一个字符串为第一个最长匹配结果,接着遍历第一个字符串的所有可能组合结尾,如果在字典中,判断当前词语是否大于前面的最长匹配结果,如果是替换掉最长。遍历完成之后,将最长的结果添加到列表中,然后再获取第二字符,遍历所有结尾组合,获取最长匹配。以此类推。
四、逆向最长匹配
既然了解了正向如何匹配,那么逆向算法应该也很好写。代码如下:
def backward_segment(text, dic):
list = []
i = len(text) - 1
while i >= 0:
long_word = text[i]
for j in range(0, i):
word = text[j:i + 1]
if word in dic:
if len(word) > len(long_word):
long_word = word
break
list.append(long_word)
i -= len(long_word)
return list
算法的原理:就是上面的正向反过来,但是这里并不是倒推文字,文字还是按语句的顺序,但是长度是从最长到最短,也就是遇到第一个就可以返回了添加了。比正向最长匹配算法节约时间。
五、双向最长匹配
虽然逆向比正向节约时间,但本身有一个很大的漏洞。假如我现在的句子中有一段“项目的”字符串,那么正向会出现“项目”,“的”两个词汇,而逆向会出现:“项”,“目的”两个词汇。
为此,我们的算法工程师提出了新的匹配规则,双向最长匹配。这是一种融合两种匹配方法的复杂规则,流程如下:
同时执行正向和逆向最长匹配,若两者的词数不同,则返回词数更少的一个否则,返回两者中单字更少的那一个。当单字也相同时,优先返回逆向最长匹配结果
具体代码如下:
#统计单字个数
def count_single_char(list):
return sum(1 for word in list if len(word) == 1)
#双向匹配算法
def bidirectional_segment():
f = forward_segment("在绝对实力面前,一切的说辞都是枉然", dic)
b = backward_segment("在绝对实力面前,一切的说辞都是枉然", dic)
if len(f) < len(b):
return f
elif len(f) > len(b):
return b
else:
if count_single_char(f)<count_single_char(b):
return f
else:
return b
到此这篇关于Python自然语言处理之切分算法详解的文章就介绍到这了,更多相关python切分算法内容请搜索hwidc以前的文章或继续浏览下面的相关文章希望大家以后多多支持hwidc!
【本文来源:鄂州网站优化 转载请说明出处】