
Python实现文本文件拆分写入到多个文本文件的方
引言
将一个txt文本文件中的内容行拆分固定的行数,自动分批写入到多个文本文件。
比如:一个源txt文件有5100行数据,每1000行插入到一个txt文件,最后获得6个txt文件(5个文本文件有1000行数据,第6个文本文件有100行数据)。
步骤
1、先建立一个目录用于存放分割后的txt文件(这里的目录名为:dataText)
2、修改拆分的数目(这里是每5000行数据存入一个txt文件)
3、运行python文件,查看生成的txt文件
代码
open_diff = open('data.txt', 'r') # 源文本文件
diff_line = open_diff.readlines()
line_list = []
for line in diff_line:
line_list.append(line)
count = len(line_list) # 文件行数
print('源文件数据行数:',count)
# 切分diff
diff_match_split = [line_list[i:i+5000] for i in range(0,len(line_list),5000)]# 每个文件的数据行数
# 将切分的写入多个txt中
for i,j in zip(range(0,int(count/5000+1)),range(0,int(count/5000+1))): # 写入txt,计算需要写入的文件数
with open('./dataText/ImageData%d.txt'% j,'w+') as temp:
for line in diff_match_split[i]:
temp.write(line)
print('拆分后文件的个数:',i+1)
结果
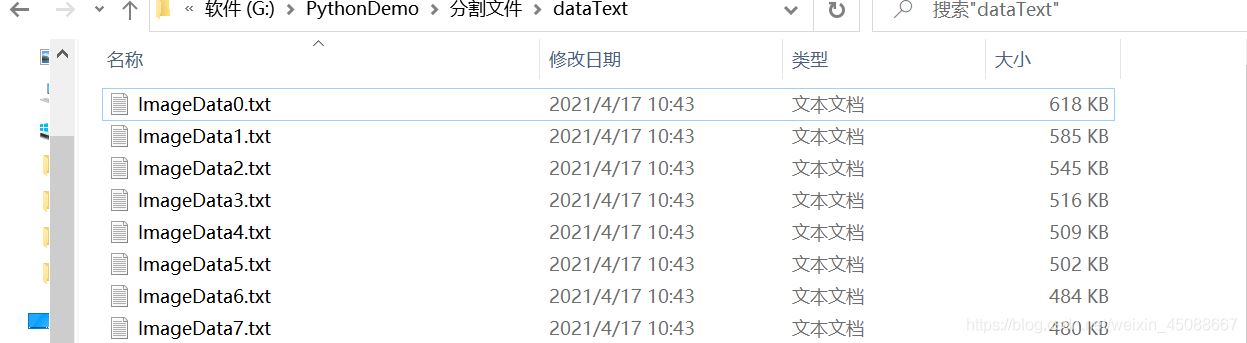
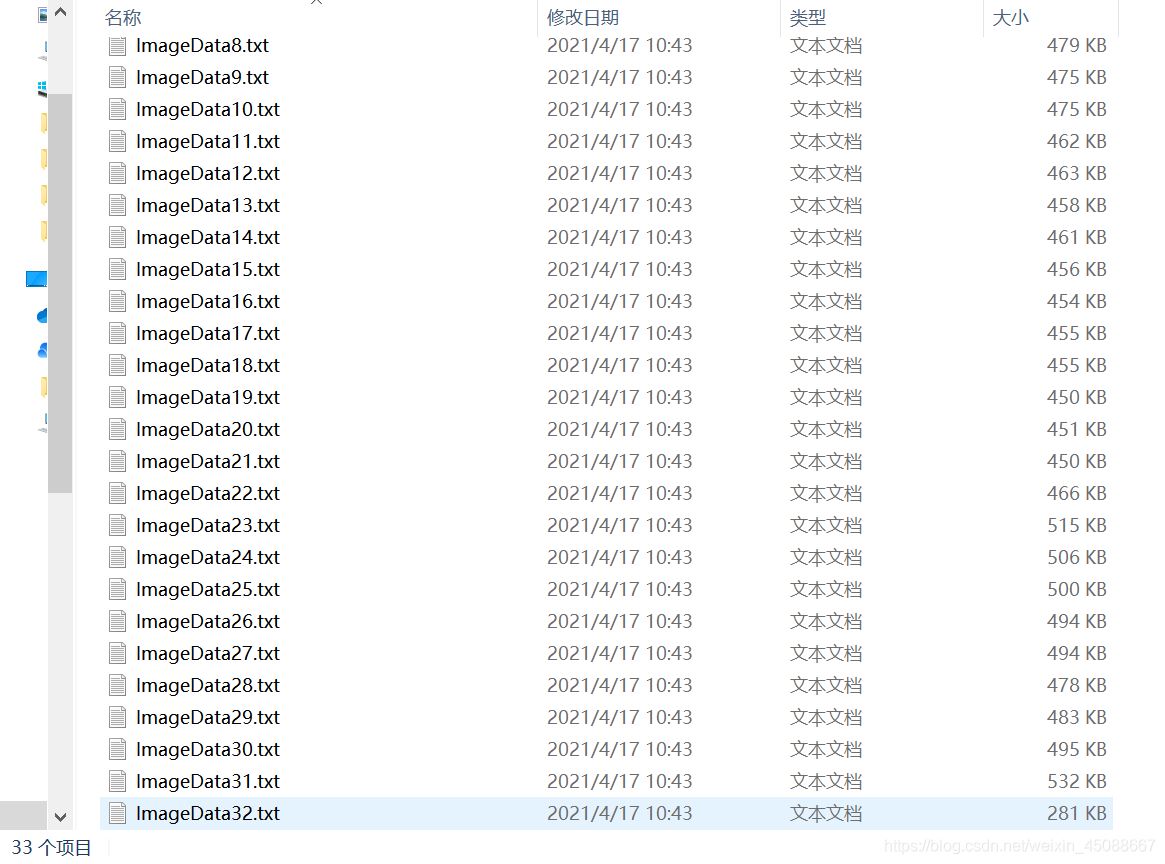
应用:
将txt文件中的数据拆分成多个文本文件,可以解决由于文本文件数据过大而无法导入某些软件的问。
这里是将一个url文本文件(约15M)导入idm下载url中的内容,但由于文本文件过大,数据量过多,就拆分成多个文本文件分批次导入idm。
注意:
1、程序中的5000为写入每个文件的数据行数,最后一个文件的行数不足5000,也用一个文本文件存储。
2、根据需要,修改存储数据的行数(两个地方的5000都需要修改)。
到此这篇关于Python实现文本文件拆分写入到多个文本文件的方法的文章就介绍到这了,更多相关Python 文本文件拆分内容请搜索hwidc以前的文章或继续浏览下面的相关文章希望大家以后多多支持hwidc!