
Python通过m3u8文件下载合并ts视频的操作
前段时间,接到一个需求,要求下载某一个网站的视频,然后自己从网上查阅了相关的资料,在这里做一个总结。
1. m3u8文件
m3u8是苹果公司推出一种视频播放标准,是一种文件检索格式,将视频切割成一小段一小段的ts格式的视频文件,然后存在服务器中(现在为了减少I/o访问次数,一般存在服务器的内存中),通过m3u8解析出来路径,然后去请求,是现在比较流行的一种加载方式。目前,很多新闻视频网站都是采用这种模式去加载视频。
M3U8文件是指UTF-8编码格式的M3U文件。M3U文件是记录了一个索引纯文本文件,打开它时播放软件并不是播放它,而是根据它的索引找到对应的音视频文件的网络地址进行在线播放。原视频数据分割为很多个TS流,每个TS流的地址记录在m3u8文件列表中。
下面就是m3u8文件的格式。
#EXTM3U #EXT-X-VERSION:3 #EXT-X-MEDIA-SEQUENCE:0 #EXT-X-ALLOW-CACHE:YES #EXT-X-TARGETDURATION:15 #EXTINF:6.916667, out000.ts #EXTINF:10.416667, out001.ts #EXTINF:10.416667, out002.ts #EXTINF:1.375000, out003.ts #EXTINF:1.541667, out004.ts #EXTINF:7.666667, out005.ts #EXTINF:10.416667,
2. ts文件处理
只有m3u8文件,需要下载ts文件
ts文件能正常播放,但太多而小,需要合并 有ts文件
但因为被加密无法播放,需要解码
在这里我只记录下前两个步骤,因为,我目前研究的比较少,还没有遇到ts被加密的情况。
3. 分析举例
那么下面,我就正式举一个网站,第一财经网(直接点击)跟大家正式的讲解下。
这是该网站的视频。如下图:
点击第一个视频,这就是我们这次要爬取的视频。
然后鼠标右键点击,选择"检查" 或者按F12键,进入开发者模式,查看网页代码。
然后,点击Network ,再点击other,寻找请求地址中带有m3u8和ts标记的请求地址。
不懂,请看下图。有一点,很重要。网站通过切割后ts加载视频,并不是没有规律的,而是通过m3u8文件附带的。也就说,网站一定是先加载m3u8文件,然后根据m3u8文件,去请求ts文件。所以,如果你找不到m3u8文件的话,你可以先找第一个ts文件,然后往上面翻,一定能找到m3u8文件。
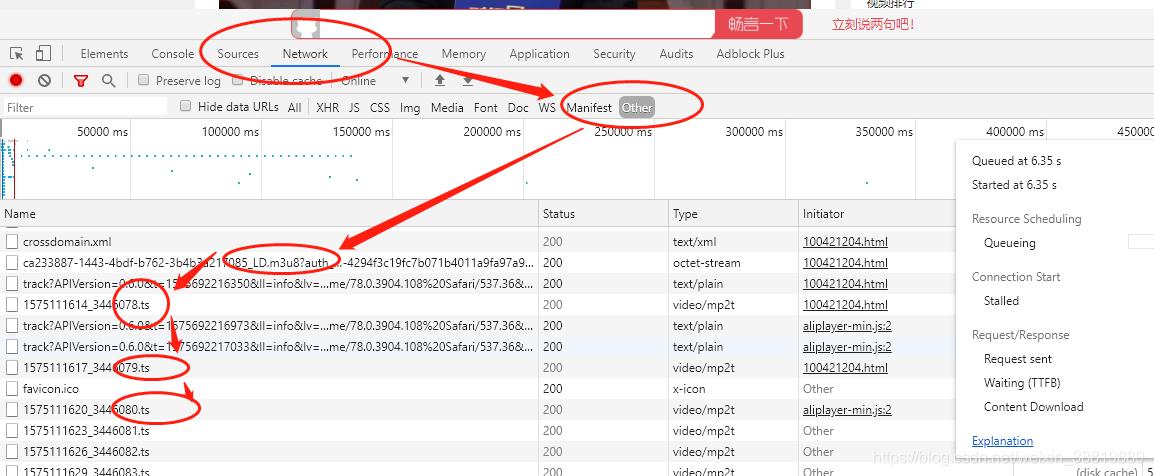
再点击这个m3u8文件,右侧对应的就是它的请求地址。
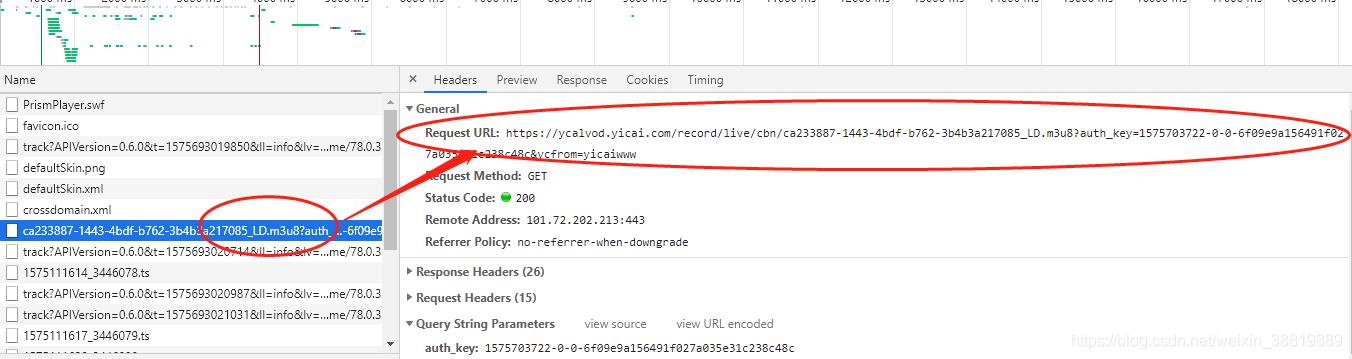
请求地址如下:
https://ycalvod.yicai.com/record/live/cbn/ca233887-1443-4bdf-b762-3b4b3a217085_LD.m3u8?auth_key=1575703722-0-0-6f09e9a156491f027a035e31c238c48c&ycfrom=yicaiwww
你可以把上面那个地址,输入浏览器地址框内,下载下来。也可以通过查看源码,找到该功能的对应的html代码。
这是下载下来的m3u8文件。

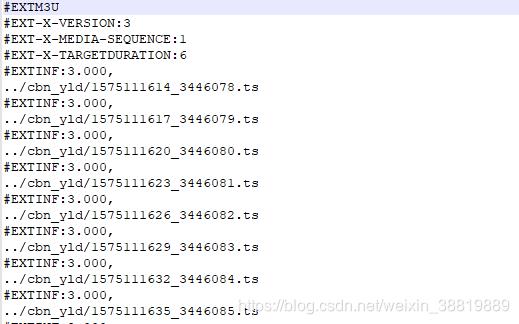
从图片可以看出来,每一个ts文件都是相对的地址,所以下面我们就需要找到绝对地址。
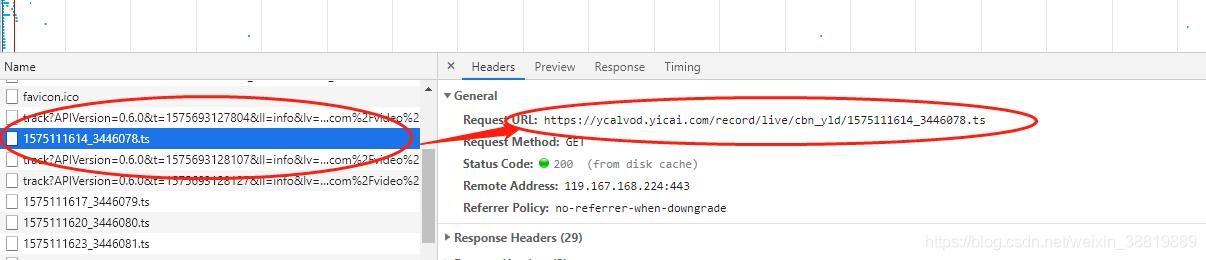
ts文件地址如下:
https://ycalvod.yicai.com/record/live/cbn_yld/1575111614_3446078.ts
上面,我们已经把这个网站的视频加载模式分析的很透彻,下面就开始撸代码了。
4. 获取ts文件
def getTsUrl():
ts_url_list = []
baseUrl = "https://ycalvod.yicai.com/record/live"
with open("ca233887-1443-4bdf-b762-3b4b3a217085_LD.m3u8", "r", encoding="utf-8") as f:
m3u8Contents = f.readlines()
for content in m3u8Contents:
if content.endswith("ts\n"):
ts_Url = baseUrl + content.replace("\n", "").replace("..", "")
ts_url_list.append(ts_Url)
print(ts_Url)
return ts_url_list
5. 下载ts文件
def download_ts_video(download_path, ts_url_list):
download_path = r"C:\Users\Administrator\Desktop\AiShu\下载视频\TS视频"
for i in range(len(ts_url_list)):
ts_url = ts_url_list[i]
try:
response = requests.get(ts_url, stream=True, verify=False)
except Exception as e:
print("异常请求:%s" % e.args)
return
ts_path = download_path + "\{}.ts".format(i)
with open(ts_path, "wb+") as file:
for chunk in response.iter_content(chunk_size=1024):
if chunk:
file.write(chunk)
print("TS文件下载完毕!!")
这就是我本地下载好的ts切割视频

6. 合并TS视频
def heBingTsVideo(download_path,hebing_path):
all_ts = os.listdir(download_path)
with open(hebing_path, 'wb+') as f:
for i in range(len(all_ts)):
ts_video_path = os.path.join(download_path, all_ts[i])
f.write(open(ts_video_path, 'rb').read())
print("合并完成!!")
最后的结果如下:

7. 完整的代码
有兴趣的小伙伴,可以研究下。
import requests,os
def getTsUrl():
ts_url_list = []
baseUrl = "https://ycalvod.yicai.com/record/live"
with open("ca233887-1443-4bdf-b762-3b4b3a217085_LD.m3u8", "r", encoding="utf-8") as f:
m3u8Contents = f.readlines()
for content in m3u8Contents:
if content.endswith("ts\n"):
ts_Url = baseUrl + content.replace("\n", "").replace("..", "")
ts_url_list.append(ts_Url)
print(ts_Url)
return ts_url_list
def download_ts_video(download_path, ts_url_list):
download_path = r"C:\Users\Administrator\Desktop\AiShu\下载视频\TS视频"
for i in range(len(ts_url_list)):
ts_url = ts_url_list[i]
try:
response = requests.get(ts_url, stream=True, verify=False)
except Exception as e:
print("异常请求:%s" % e.args)
return
ts_path = download_path + "\{}.ts".format(i)
with open(ts_path, "wb+") as file:
for chunk in response.iter_content(chunk_size=1024):
if chunk:
file.write(chunk)
print("TS文件下载完毕!!")
def heBingTsVideo(download_path,hebing_path):
all_ts = os.listdir(download_path)
with open(hebing_path, 'wb+') as f:
for i in range(len(all_ts)):
ts_video_path = os.path.join(download_path, all_ts[i])
f.write(open(ts_video_path, 'rb').read())
print("合并完成!!")
if __name__ == '__main__':
download_path = r"C:\Users\Administrator\Desktop\AiShu\下载视频\TS视频"
hebing_path = r"C:\Users\Administrator\Desktop\AiShu\下载视频\合并TS视频\第一财经.mp4"
ts_url_list = getTsUrl()
download_ts_video(download_path, ts_url_list)
heBingTsVideo(download_path,hebing_path)
以上为个人经验,希望能给大家一个参考,也希望大家多多支持hwidc。如有错误或未考虑完全的地方,望不吝赐教。
【本文由:襄阳网站推广 提供 转载请保留URL】