
python 用递归实现通用爬虫解析器
目录
- 需求分析
- 进一步分析
- 再进一步分析
- 代码实现
我们在写爬虫的过程中,除了研究反爬之外,几乎全部的时间都在写解析逻辑。那么,生命苦短,为什么我们不写一个通用解析器呢?对啊!为什么不呢?开整!
需求分析
爬虫要解析的网页类型无外乎 html、json 以及一些二进制文件(video、excel 文件等)。既然要做成通用解析器,我们有两种实现方式,一种是将网页内容转换成统一的形式,然后用对应的解析规则去解析,比如全部将网页内容转换成 html 形式,然后用 xpath 去提取。
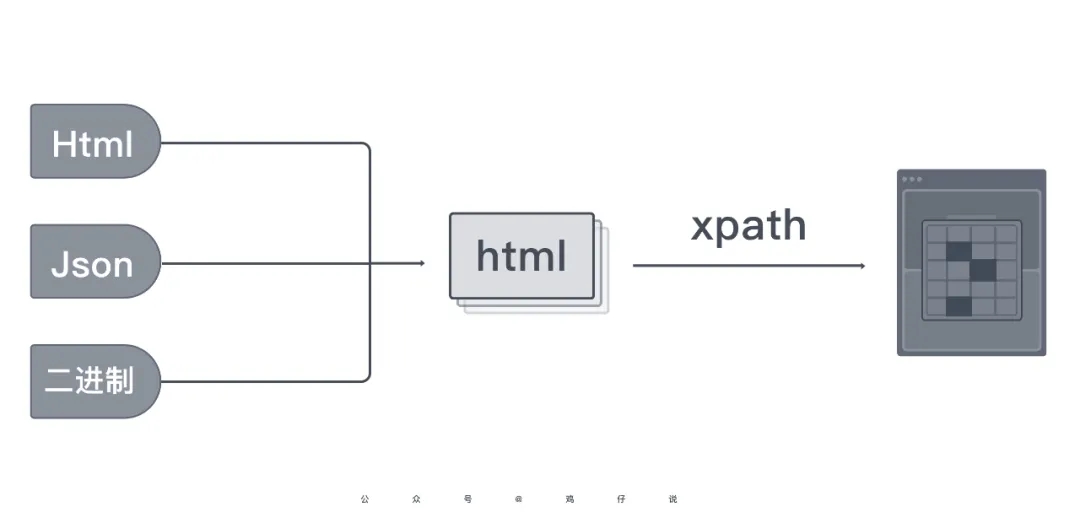
另外一种是配置文件预先告知的方式,你配置成什么类型,解析器就通过对应的解析规则去解析。
统一网页形式,需要做大量的网页内容形式转换,而配置文件预先告知则需要在配置时指定更多解析字段。相比较而言,通过第二种方式,未来改变较多的是配置规则,不需要动核心代码,引入 bug 的可能性较低。因此这里我们采用第二种方式实现解析器
进一步分析
解析器对于网页内容的提取,本质上和我们在本地电脑上查找和整理文件,没有什么差别。比如像下面这样
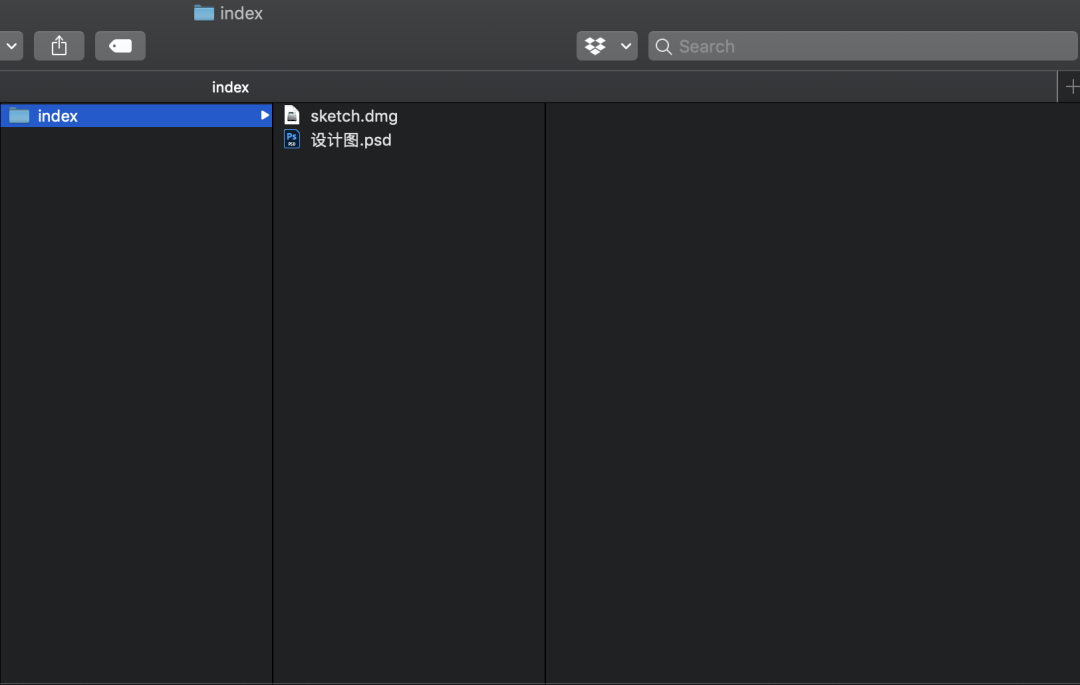
解析内容就是从中提取我们想要的信息,然后整理成我们希望的格式。比如上面的内容,我们提取出来的形式应该是这样
{
"design": "设计图.psd",
"software": "sketch.dmg"
}
而在实际的爬虫开发过程中,网页形式远比以上的复杂。其实遇到最多的问题是在一组列表中嵌套一个列表,我们需要把这种形式提取出来。比如像下面这种形式
{
"a": "a",
"b": [
{"c": "c1", "d": "d1"},
{"c": "c2", "d": "d2"}]
}
他提取出信息后应该是这样
[
{
"a": "a",
"c": "c1",
"d": "d1"
},
{
"a": "a",
"c": "c2",
"d": "d2"
}
]
如果小伙伴对于算法熟悉的话,应该能察觉出这种遍历用递归来写是非常方便的。但要注意的是 python 会限定递归的层数,小伙伴可以通过下面这个方法查看递归限定的层数
import sys print(sys.getrecursionlimit()) >>>1000
我这边限定的层数是 1k。对于解析网页来说完全够用了,如果哪个人把网页解析逻辑嵌套了 1000 层,我建议你直接跟老板提放弃这个网页吧!
再进一步分析
我们已经知道对于通用解析来说,就是通过配置解析规则提取页面的对应信息。而针对有列表层级的网页可能还涉及递归遍历问题。那如何去配置这种解析规则呢?其实很简单,只需要在进入每一个层级之前先指定该层的数据形式,比如下面这个原数据
{
"a": "a",
"b": [
{"c": "c1", "d": "d1"},
{"c": "c2", "d" : "d2"}
]
}
想提取嵌套信息,我们的解析规则就应该是这样的
[
{
"$name": "a",
"$value_type": "raw",
"$parse_method": "json",
"$parse_rule": "a",
"$each": []
},
{
"$name": "__datas__",
"$value_type": "recursion",
"$parse_method": "json",
"$parse_rule": "b",
"$each": [
{
"$name": "c",
"$value_type": "raw",
"$parse_method": "json",
"$parse_rule": "c",
"$each": []
},
{
"$name": "d",
"$value_type": "raw",
"$parse_method": "json",
"$parse_rule": "d",
"$each": []
}
]
}
]
其中 $name 字段表示我们最终希望最外层数据所拥有的字段名,当然如果是需要递归到内层的字段,则将列表保存为 __datas__ ,然后根据这个 __datas__ 进行内层结构的解析。最终我们得到的数据结构应该是这样的
[
{"a": "a", "c": "c1", "d": "d1"},
{"a": "a", "c": "c2", "d": "d2"}
]
以上我们只演示了 json 的解析规则,如果要拿来解析 html 对象呢?很简单,将解析方式改为 xpath 对象,然后传入 xpath 解析语法即可。
代码实现
总共分成两部分,一部分根据原最终结果和规则进行打包,将所有涉及 recursion 逻辑的字段进行转换,代码如下
def _pack_json(result, rules):
item = {}
for p_rule in rules:
if p_rule.get("$value_type") == "raw":
if p_rule.get("$parse_method") == "json":
item[p_rule.get("$name")] = glom(result, p_rule.get("$parse_rule"))
elif p_rule.get("$value_type") == "recursion":
if p_rule.get("$parse_method") == "json":
tmp_result = glom(result, p_rule.get("$parse_rule"))
total_result = []
for per_r in tmp_result:
total_result.append(_pack_json(per_r, p_rule.get("$each")))
item[p_rule.get("$name")] = total_result
return item
另外一部分将上一步得到的进行解析,将打包得到的结果进行解包,即将所有内嵌的数据提到最外层,代码如下
def _unpack_datas(result: dict) -> list:
if "__datas__" not in result:
return [result]
item_results = []
all_item = result.pop("__datas__")
for per_item in all_item:
if "__datas__" in per_item:
tmp_datas = per_item.pop("__datas__")
for per_tmp_data in tmp_datas:
tmp_item = _unpack_datas(per_tmp_data)
for per_tmp_item in tmp_item:
item_results.append({**per_tmp_item, **per_item})
else:
item_results.append({**result, **per_item})
return item_results
后再包一层执行入口就可以了,完整代码如下
from loguru import logger
from glom import glom
def parse(result, rules):
def _pack_json(result, rules):
item = {}
for p_rule in rules:
if p_rule.get("$value_type") == "raw":
if p_rule.get("$parse_method") == "json":
item[p_rule.get("$name")] = glom(result, p_rule.get("$parse_rule"))
elif p_rule.get("$value_type") == "recursion":
if p_rule.get("$parse_method") == "json":
tmp_result = glom(result, p_rule.get("$parse_rule"))
total_result = []
for per_r in tmp_result:
total_result.append(_pack_json(per_r, p_rule.get("$each")))
item[p_rule.get("$name")] = total_result
return item
def _unpack_datas(result: dict) -> list:
if "__datas__" not in result:
return [result]
item_results = []
all_item = result.pop("__datas__")
for per_item in all_item:
if "__datas__" in per_item:
tmp_datas = per_item.pop("__datas__")
for per_tmp_data in tmp_datas:
tmp_item = _unpack_datas(per_tmp_data)
for per_tmp_item in tmp_item:
item_results.append({**per_tmp_item, **per_item})
else:
item_results.append({**result, **per_item})
return item_results
pack_result = _pack_json(result, rules)
logger.info(pack_result)
return _unpack_datas(pack_result)
以上,就是通用解析器的完整案例。案例中仅实现了对于 json 的支持,小伙伴可以基于自己的项目,改造成其他的解析形式。通用解析其实是鸡仔为了偷懒写的,因为鸡仔发现,在爬虫开发中,大部分工作都耗在解析这部分。而有了通用解析的前端页面,运营和数据分析师就可以根据自己的需要配置自己想爬取的站点了。人生苦短,你懂得。我去摸鱼了~
实现方式请移步至 github 查看:https://github.com/hacksman/learn_lab/blob/master/small_bug_lab/general_parser.py
以上就是python 用递归实现通用爬虫解析器的详细内容,更多关于python 递归实现爬虫解析器的资料请关注hwidc其它相关文章!
【文章原创作者:http://www.yidunidc.com/gfip.html 网络转载请说明出处】