
Spark简介以及与Hadoop对比分析
目录
- 1. Spark 与 Hadoop 比较
- 1.1 Haoop 的缺点
- 1.2 相较于Hadoop MR的优点
- 2. Spark 生态系统
- 2.1 大数据处理的三种类型
- 1. 复杂的批量数据处理
- 2. 基于历史数据的交互式查询
- 3. 基于实时数据流的数据处理
- 2.2 BDAS架构
- 2.3 Spark 生态系统
- 3. 基本概念与架构设计
- 3.1 基本概念
- 3.2 运行架构
- 3.3 各种概念之间的相互关系
- 4. Spark运行基本流程
- 4.1 运行流程
- 4.2 运行架构特点
- 5. Spark的部署和应用方式
- 5.1 Spark的三种部署方式
- 5.1.1 Standalone
- 5.1.2 Spark on Mesos
- 5.1.3 Spark on YARN
- 5.2 从Hadoop+Storm架构转向Spark架构
- Hadoop+Storm架构
- 用Spark架构满足批处理和流处理需求
- Spark架构的优点:
- 5.3 Hadoop和Spark的统一部署
- 不同计算框架统一运行在YARN中
1. Spark 与 Hadoop 比较
1.1 Haoop 的缺点
- 1. 表达能力有限;
- 2. 磁盘IO开销大;
- 3. 延迟高;
- 4. 任务之间的衔接涉及IO开销;
- 5. 在前一个任务执行完之前,其他任务就无法开始,难以胜任复杂、多阶段的计算任务。
1.2 相较于Hadoop MR的优点
- 1. Spark的计算模式也属于MR,但不局限于Map和Reduce操作,它还提供了多种数据集操作类型,编程模式也比Hadoop MR更灵活;
- 2. Spark提供了内存计算,可将中间结果放到内存中,对于迭代运算效率更高;
- 3. Spark 基于DAG的任务调度执行机制,要优于Hadoop MR的迭代执行机制。
2. Spark 生态系统
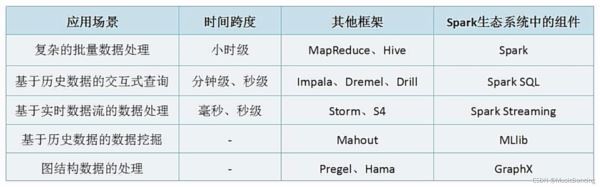
2.1 大数据处理的三种类型
1. 复杂的批量数据处理
时间跨度在数十分钟到数小时
Haoop MapReduce
2. 基于历史数据的交互式查询
时间跨度在数十秒到数分钟
Cloudera、Impala 这两者实时性均优于hive。
3. 基于实时数据流的数据处理
时间跨度在数百毫秒到数秒
Storm
2.2 BDAS架构
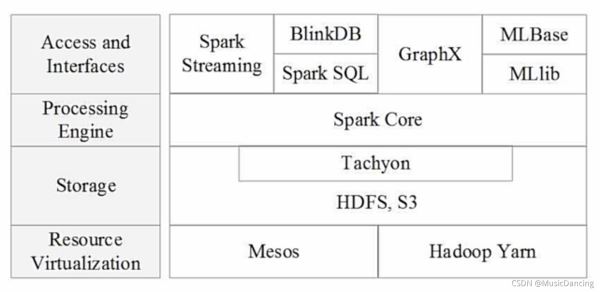
2.3 Spark 生态系统
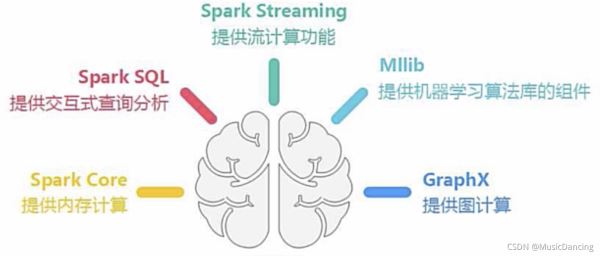
3. 基本概念与架构设计
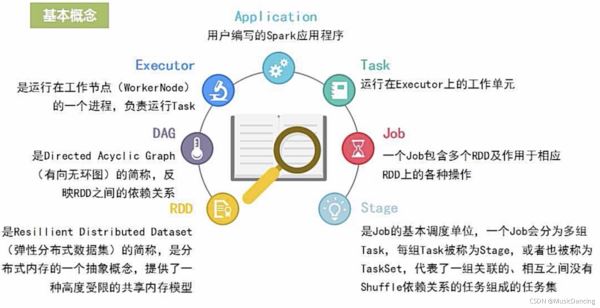
3.1 基本概念
3.2 运行架构
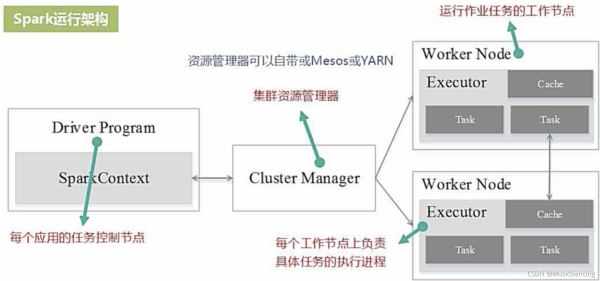
Spark采用Executor的优点:(相比于Hadoop的MR)
- 1. 利用多线程来执行具体的任务,减少任务的启动开销;
- 2. Executor中有一个BlockManager存储模块,会将内存和磁盘共同作为存储设备,有效减少IO开销。
3.3 各种概念之间的相互关系
- 一个Application由一个Driver和若干个Job构成
- 一个Job由多个Stage构成
- 一个Stage由多个没有shuffle关系的Task组成
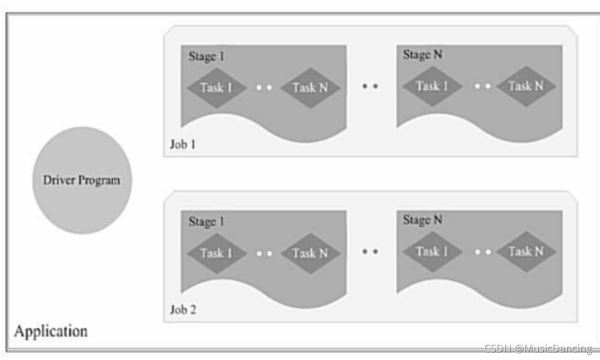
当执行一个Application时,Driver会向集群管理器申请资源,启动Executor,
并向Executor发送应用程序代码和文件,然后在Executor上执行Task,运行结束后,
执行结果会返回给Driver,或者写到HDFS或者其他数据库中。
4. Spark运行基本流程
4.1 运行流程
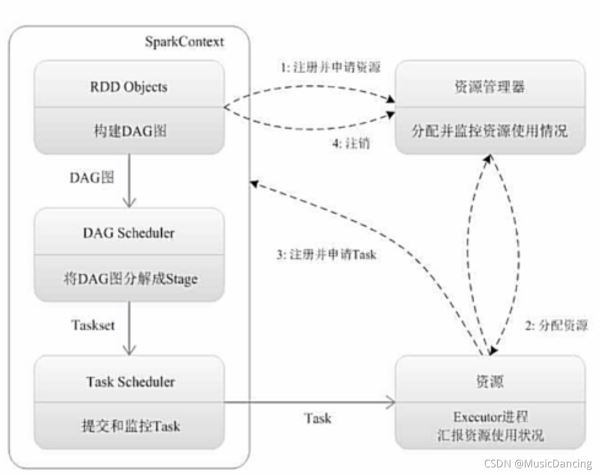
1. 为应用构建起基本的运行环境,即由Driver创建一个SparkContext进行资源的申请、任务的分配和监控。
2. 资源管理器为Executor分配资源,并启动Executor进程。
- 3.1 SparkContext根据RDD的依赖关系构建DAG图,DAG图提交给DAGScheduler解析成Stage,然后把一个个TaskSet提交给底层调度器TaskScheduler处理。
- 3.2 Executor向SparkContext申请Task,TaskScheduler将Task发送给Executor运行并提供应用程序代码。
4. Task在Executor上运行把执行结果反馈给TaskScheduler,然后反馈给DAGScheduler,运行完毕后写入数据并释放所有资源。
4.2 运行架构特点
1. 每个Application都有自己专属的Executor进程,并且该进程在Application运行期间一直驻留。Executor进程以多线程的方式运行Task。
2. Spark运行过程与资源管理器无关,只要能够获取Executor进程并保持通信即可。
3. Task采用了数据本地性和推测执行等优化机制。(计算向数据靠拢。)
5. Spark的部署和应用方式
5.1 Spark的三种部署方式
5.1.1 Standalone
类似于MR1.0,slot为资源分配单位,但性能并不好。
5.1.2 Spark on Mesos
Mesos和Spark有一定的亲缘关系。
5.1.3 Spark on YARN
mesos和yarn的联系
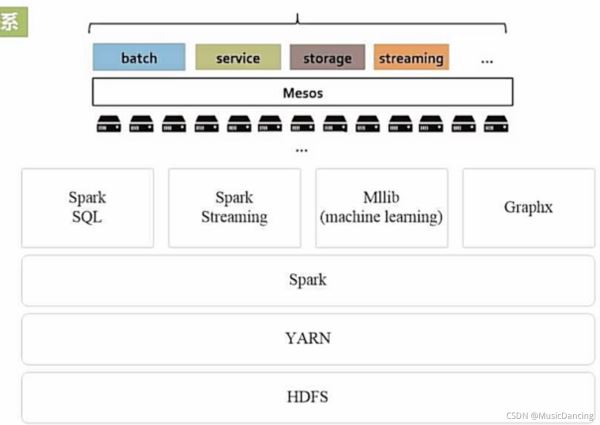
5.2 从Hadoop+Storm架构转向Spark架构
Hadoop+Storm架构
这种部署方式较为繁琐。
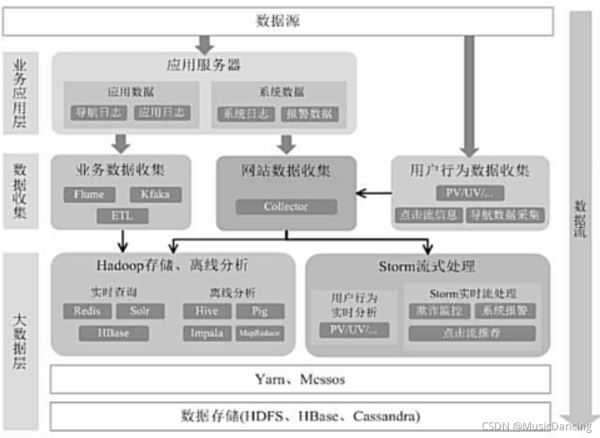
用Spark架构满足批处理和流处理需求
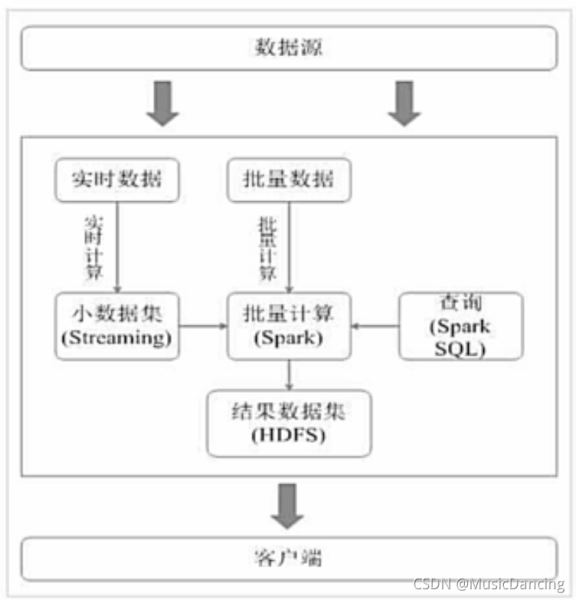
Spark用快速的小批量计算模拟流计算,并非真实的流计算。
无法实现毫秒级的流计算,对于需要毫秒级实时响应的企业应用而言,仍需采用流计算框架Storm等。
Spark架构的优点:
- 1. 实现一键式安装和配置,线程级别的任务监控和告警;
- 2. 降低硬件集群、软件维护、任务监控和应用开发的难度;
- 3. 便于做成统一的硬件、计算平台资源池。
5.3 Hadoop和Spark的统一部署
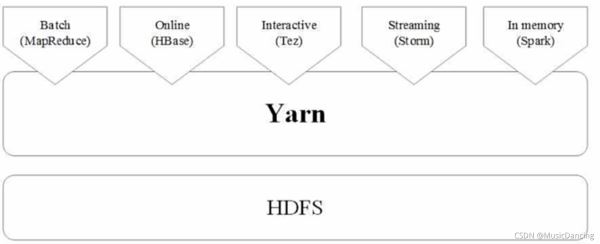
不同计算框架统一运行在YARN中
好处如下:
- 1. 计算资源按需伸缩;
- 2. 不用负载应用混搭,集群利用率高;
- 3. 共享底层存储,避免数据跨集群迁移
现状:
1. Spark目前还是无法取代Hadoop生态系统中的一些组件所实现的功能。
2. 现有的Hadoop组件开发的应用,完全迁移到Spark上需要一定的成本。
到此这篇关于Spark简介以及与Hadoop对比分析的文章就介绍到这了,更多相关Spark与Hadoop内容请搜索海外IDC网以前的文章或继续浏览下面的相关文章希望大家以后多多支持海外IDC网!