
C#版Tesseract库的使用技巧
上一篇介绍了Tesseract库的使用(OCR库Tesseract初探),文末提到了Tesseract是用c/c++开发的,也有C#的开源版本,本篇介绍一下如何使用C#版的Tesseract。
C#版本源码下载地址:https://github.com/charlesw/tesseract
其实在vs中可以直接用NuGet工具进行下载:
打开nuget,搜索tesseract,点安装即可。
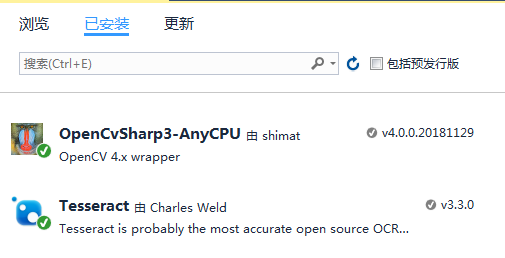
源码是vs2015编译的,需要安装vs2015以上版本。
打开项目后如:
我们再添加一个winform项目,画界面如:
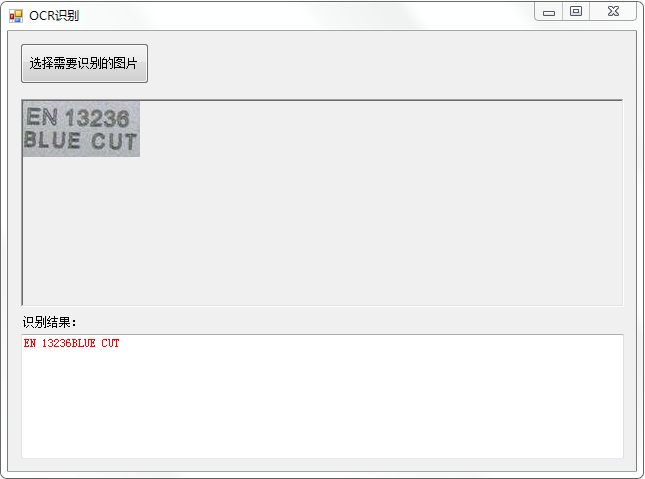
实现点击“选择需要识别的图片”,打开一张图片,调用算法并显示结果。比较简单。源码如下:
using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Drawing;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using System.Windows.Forms;
using Tesseract;
namespace TesseractDemo
{
public partial class Form1 : Form
{
public Form1()
{
InitializeComponent();
}
//选图片并调用ocr识别方法
private void btnRec_Click(object sender, EventArgs e)
{
//openFileDialog1.Filter = "";
if (openFileDialog1.ShowDialog() == DialogResult.OK)
{
var imgPath = openFileDialog1.FileName;
pictureBox1.Image=Image.FromFile(imgPath);
string strResult = ImageToText(imgPath);
if (string.IsNullOrEmpty(strResult))
{
txtResult.Text = "无法识别";
}
else
{
txtResult.Text = strResult;
}
}
}
//调用tesseract实现OCR识别
public string ImageToText(string imgPath)
{
using (var engine = new TesseractEngine("tessdata", "eng", EngineMode.Default))
{
using (var img = Pix.LoadFromFile(imgPath))
{
using (var page = engine.Process(img))
{
return page.GetText();
}
}
}
}
}
}
有一点要注意的是,【本文由:http://www.yidunidc.com/mgzq.html复制请保留原URL】tesseract的识别语言包要自己下载后包含到项目里面,并设置为始终复制,或者直接把这个文件包放到运行程序目录(bin\debug)下:
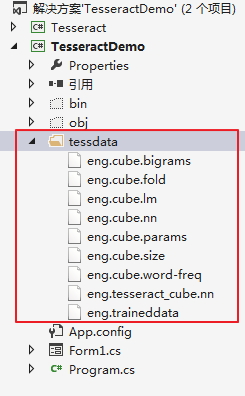
eng是英文字符的意思,要识别其他语言字符,需要自己下载:
Tesseract hasunicode (UTF-8) support, and canrecognize more than 100 languages"out of the box".
这个库支持100种语言的识别
字库下载地址为:https://github.com/tesseract-ocr/tessdata
用OpencvSharp先降噪再调OCR识别:
//用opencv进行降噪处理再ocr识别
private void button3_Click(object sender, EventArgs e)
{
//从网上读取一张图片
string imgUrl = "https://service.cheshi.com/user/validate/validatev3.php";
MemoryStream ms = ReadImgFromWeb(imgUrl);
Image img = Image.FromStream(ms);
pictureBox1.Image = img;
//降噪
Mat simg = Mat.FromStream(ms, ImreadModes.Grayscale);
Cv2.ImShow("Input Image", simg);
//阈值操作 阈值参数可以用一些可视化工具来调试得到
Mat ThresholdImg = simg.Threshold(29, 255, ThresholdTypes.Binary);
Cv2.ImShow("Threshold", ThresholdImg);
Cv2.ImWrite("d:\\img.png", ThresholdImg);
textBox1.Text= ImageToText("d:\\img.png");
}
/// <summary>
/// 从网上读取一张图片
/// </summary>
/// <param name="Url"></param>
public MemoryStream ReadImgFromWeb(string Url)
{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(Url);
request.Credentials = CredentialCache.DefaultCredentials; // 添加授权证书
request.UserAgent = "Microsoft Internet Explorer";
WebResponse response = request.GetResponse();
Stream s = response.GetResponseStream();
byte[] data = new byte[1024];
int length = 0;
MemoryStream ms = new MemoryStream();
while ((length = s.Read(data, 0, data.Length)) > 0)
{
ms.Write(data, 0, length);
}
ms.Seek(0, SeekOrigin.Begin);
//pictureBox1.Image = Image.FromStream(ms);
return ms;
}
请自行用NuGet程序下载opencvsharp3.0库,参考https://www.cnblogs.com/tuyile006/p/10819570.html
另外专门有篇文章介绍中文识别:Tesseract-OCR识别中文与训练字库实例
以上就是C#版Tesseract库的使用技巧的详细内容,更多关于C# Tesseract库的资料请关注海外IDC网其它相关文章!