
详解JS浏览器事件模型
目录
- 什么是事件
- 一个简单的例子
- 如何绑定事件
- 框架中的事件
- 事件对象
- 事件传播
- 事件代理
- 总结
什么是事件
我想你很可能听说过事件驱动, 但是事件驱动到底是什么?为什么说浏览器是事件驱动的呢?
事件驱动通俗地来说就是什么都抽象为事件。
- 一次点击是一个事件
- 键盘按下是一个事件
- 一个网络请求成功是一个事件
- 页面加载是一个事件
- 页面报错是一个事件
浏览器依靠事件来驱动APP运行下去,如果没有了事件驱动,那么APP会直接从头到尾运行完,然后结束,事件驱动是浏览器的基石。
一个简单的例子
其实现实中的红绿灯就是一种事件,它告诉我们现在是红灯状态,绿灯状态,还是黄灯状态。 我们需要根据这个事件自己去完成一些操作,比如红灯和黄灯我们需要等待,绿灯我们可以过马路。
下面我们来看一个最简单的浏览器端的事件:
html代码:
<button>Change color</button>
js代码:
var btn = document.querySelector('button');
btn.onclick = function() {
console.log('button clicked')
}
代码很简单,我们在button上注册了一个事件,这个事件的handler是一个我们定义的匿名函数。当用户点击了这个被注册了事件的button的时候,这个我们定义好的匿名函数就会被执行。
如何绑定事件
我们有三种方法可以绑定事件,分别是行内绑定,直接赋值,用addEventListener。
内联这个方法非常不推荐
html代码:
<button onclick="handleClick()">Press me</button>
然后在script标签内写:
function handleClick() {
console.log('button clicked')
}
直接赋值
和我上面举的例子一样:
var btn = document.querySelector('button');
btn.onclick = function() {
console.log('button clicked')
}
这种方法有两个缺点
不能添加多个同类型的handler
btn.onclick = functionA; btn.onclick = functionB;
这样只有functionB有效,这可以通过addEventListener来解决。
不能控制在哪个阶段来执行,这个会在后面将事件捕获/冒泡的时候讲到。这个同样可以通过addEventListener来解决。
因此addEventListener横空出世,这个也是目前推荐的写法。
addEventListener
旧版本的addEventListener第三个参数是bool,新版版的第三个参数是对象,这样方便之后的扩展,承载更多的功能, 我们来重点介绍一下它。
addEventListener可以给Element,Document,Window,甚至XMLHttpRequest等绑定事件,当指定的事件发生的时候,绑定的回调函数就会被以某种机制进行执行,这种机制我们稍后就会讲到。
语法:
target.addEventListener(type, listener[, options]); target.addEventListener(type, listener[, useCapture]); target.addEventListener(type, listener[, useCapture, wantsUntrusted ]); // Gecko/Mozilla only
type是你想要绑定的事件类型,常见的有click, scroll, touch, mouseover等,旧版本的第三个参数是bool,表示是否是捕获阶段,默认是false,即默认为冒泡阶段。新版本是一个对象,其中有capture(和上面功能一样),passive和once。 once用来执行是否只执行一次,passive如果被指定为true表示永远不会执行preventDefault(),这在实现丝滑柔顺的滚动的效果中很重要。更多请参考Improving scrolling performance with passive listeners
框架中的事件
实际上,我们现在大多数情况都是用框架来写代码,因此上面的情况其实在现实中是非常少见的,我们更多看到的是框架封装好的事件,比如react的合成事件,感兴趣的可以看下这几篇文章。
- React SyntheticEvent
- Vue和React的优点分别是什么?两者的最核心差异对比是什么?
虽然我们很少时候会接触到原生的事件,但是了解一下事件对象,事件机制,事件代理等还是很有必要的,因为框架的事件系统至少在这方面还是一致的,这些内容我们接下来就会讲到。
事件对象
所有的事件处理函数在被浏览器执行的时候都会带上一个事件对象,举个例子:
function handleClick(e) {
console.log(e);
}
btn.addEventListener('click', handleClick);
这个e就是事件对象,即event object。 这个对象有一些很有用的属性和方法,下面举几个常用的属性和方法。
属性
- target
- x, y等位置信息
- timeStamp
- eventPhase
方法
- preventDefault 用于阻止浏览器的默认行为,比如a标签会默认进行跳转,form会默认校验并发送请求到action指定的地址等
- stopPropagation 用于阻止事件的继续冒泡行为,后面讲事件传播的时候会提到。
事件传播
前面讲到了事件默认是绑定到冒泡阶段的,如果你显式令useCapture为true,则会绑定到捕获阶段。
事件捕获很有意思,以至于我会经常出事件的题目加上一点事件传播的机制,让候选人进行回答,这很能体现一个人的水平。了解事件的传播机制,对于一些特定问题有着非常大的作用。
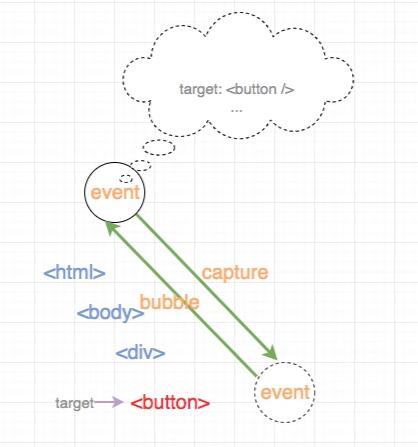
一个Element上绑定的事件触发了,那么其实会经过三个阶段。
第一个阶段 - 捕获阶段
从最外层即HTML标签开始,检查当前元素有没有绑定对应捕获阶段事件,如果有则执行,没有则继续往里面传播,这个过程递归执行直到触达触发这个事件的元素为止。
伪代码:
function capture(e, currentElement) {
if (currentElement.listners[e.type] !== void 0) {
currentElement.listners[e.type].forEach(fn => fn(e))
}
// pass down
if (currentElement !== e.target) {
// getActiveChild用于获取当前事件传播链路上的子节点
capture(e, getActiveChild(currentElement, e))
} else {
bubble(e, currentElement)
【本文由:http://www.1234xp.com/cdn.html 提供,感谢支持】 }
}
// 这个Event对象由引擎创建
capture(new Event(), document.querySelector('html'))
第二个阶段 - 目标阶段
上面已经提到了,这里省略了。
第三个阶段 - 冒泡阶段
从触发这个事件的元素开始,检查当前元素有没有绑定对应冒泡阶段事件,如果有则执行,没有则继续往里面传播,这个过程递归执行直到触达HTML为止。
伪代码:
function bubble(e, currentElement) {
if (currentElement.listners[e.type] !== void 0) {
currentElement.listners[e.type].forEach(fn => fn(e))
}
// returning
if (currentElement !== document.querySelector('html')) {
bubble(e, currentElement.parent)
}
}
上述的过程用图来表示为:
如果你不希望事件继续冒泡,可以用之前我提到的stopPropagation。
伪代码:
function bubble(e, currentElement) {
let stopped = false;
function cb() {
stopped = true;
}
if (currentElement.listners[e.type] !== void 0) {
currentElement.listners[e.type].forEach(fn => {
fn({
...e,
stopPropagation: cb
});
if (stopped) return;
})
}
// returning
if (currentElement !== document.querySelector('html')) {
bubble(e, currentElement.parent)
}
}
事件代理
利用上面提到的事件冒泡机制,我们可以选择做一些有趣的东西。 举个例子:
我们有一个如下的列表,我们想在点击对应列表项的时候,输出是点击了哪个元素。
HTML代码:
<ul>
<li>1</li>
<li>2</li>
<li>3</li>
<li>4</li>
</ul>
JS代码:
document.querySelector('ul').addEventListener('click', e => console.log(e.target.innerHTML))
在线地址,上面说了addEventListener会默认绑定到冒泡阶段,因此事件会从目标阶段开始,向外层冒泡,到我们绑定了事件的ul上,ul中通过事件对象的target属性就能获取到是哪一个元素触发的。
“事件会从目标阶段开始”,并不是说事件没有捕获阶段,而是我们没有绑定捕获阶段,我描述给省略了。
我们只给外层的ul绑定了事件处理函数,但是可以看到li点击的时候,实际上会打印出对应li的内容(1,2,3或者4)。 我们无须给每一个li绑定事件处理函数,不仅从代码量还是性能上都有一定程度的提升。
这个有趣的东西,我们给了它一个好听的名字“事件代理”。在实际业务中我们会经常使用到这个技巧,这同时也是面试的高频考点。
总结
事件其实不是浏览器特有的,和JS语言也没有什么关系,这也是我为什么没有将其划分到JS部分的原因。很多地方都有事件系统,但是各种事件模型又不太一致。
我们今天讲的是浏览器的事件模型,浏览器基于事件驱动,将很多东西都抽象为事件,比如用户交互,网络请求,页面加载,报错等,可以说事件是浏览器正常运行的基石。
我们在使用的框架都对事件进行了不同程度的封装和处理,除了了解原生的事件和原理,有时候了解一下框架本身对事件的处理也是很有必要的。
当发生一个事件的时候,浏览器会初始化一个事件对象,然后将这个事件对象按照一定的逻辑进行传播,这个逻辑就是事件传播机制。 我们提到了事件传播其实分为三个阶段,按照时间先后顺序分为捕获阶段,目标阶段和冒泡阶段。开发者可以选择监听不同的阶段,从而达到自己想要的效果。
事件对象有很多属性和方法,允许你在事件处理函数中进行读取和操作,比如读取点击的坐标信息,阻止冒泡等。
最后我们通过一个例子,说明了如何利用冒泡机制来实现事件代理。
以上就是详解JS浏览器事件模型的详细内容,更多关于JS浏览器事件模型的资料请关注海外IDC网其它相关文章!
【本文来源:韩国服务器 https://www.68idc.cn欢迎留下您的宝贵建议】