
在JavaScript中如何使用宏详解
在语言当中,宏常见用途有实现 DSL 。通过宏,开发者可以自定义一些语言的格式,比如实现 JSX 语法。在 WASM 已经实现的今天,用其他语言来写网页其实并不是没有可能。像 Rust 语言就带有强大的宏功能,这使得基于 Rust 的 Yew 框架,不需要实现类似 Babel 的东西,而是靠语言本身就能实现类似 JSX 的语法。 一个 Yew 组件的例子,支持类 JSX 的语法。
impl Component for MyComponent {
// ...
fn view(&self) -> Html {
let onclick = self.link.callback(|_| Msg::Click);
html! {
<button onclick=onclick>{ self.props.button_text }</button>
}
}
}
JavaScript 宏的局限性
不同于 Rust ,JavaScript 本身是不支持宏的,所以整个工具链也是没有考虑宏的。因此,你是可以写个识别自定义语法的宏,但是由于配套的工具链并不支持,比如最常见的 VSCode 和 Typescript ,你会得到一个语法错误。同样对于 babel 本身所用的 parser 也是不支持扩展语法的,除非你另 Fork 出来一个 Babel 。因此 babel-plugin-macros 不支持自定义语法。 不过,借助模板字符串函数,我们可以曲线救国,至少获得部分自定义语法树的能力。 一个 GraphQL 的例子,支持在 JavaScript 中直接编写 GraphQL。
import { gql } from 'graphql.macro';
const query = gql`
query User {
user(id: 5) {
lastName
...UserEntry1
}
}
`;
// 在编译期会转换成 ↓ ↓ ↓ ↓ ↓ ↓
const query = {
"kind": "Document",
"definitions": [{
...
为什么要用宏而非 Babel 插件
Babel 插件的能力确实远大于宏,而且有些情况下确实是不得不用插件。宏比起 Babel 插件好的一点在于,宏的理念在于开箱即用。使用 React 的开发者,相信都听过的大名鼎鼎的 Create-React-App ,帮你封装好了各种底层细节,开发者专注于编写代码即可。但是 CRA 的问题在于其封装的太严了,但凡你有一点需要自定义 Babel 插件的需求,基本上就需要执行yarn react-script eject,将所有底层细节暴露出来。 而对于宏来说,你只需要在项目的 Babel 配置内添加一个 babel-plugin-macros 插件,那么对于任何自定义的 Babel 宏都可以完美支持,而不是像插件一样,需要下载各种各样的插件。 CRA 已经内置了 babel-plugin-macros ,你可以在 CRA 项目中使用任意的 Babel 宏。
如何写一个宏?
介绍
一个宏非常像一个 Babel 插件,因此事先了解如何编写 Babel 插件是非常有帮助的,对于如何编写 Babel 插件, Babel 官方有一本手册,专门介绍了如何从零编写一个 Babel 插件。 在知道如何编写 Babel 插件之后,我们首先通过一个使用宏的例子,来介绍下, Babel 是如何识别文件中的宏的。是某种的特殊的语法,还是用烂的 $ 符号?
import preval from 'preval.macro' const one = preval`module.exports = 1 + 2 - 1 - 1`
这是非常常见的一个宏,其作用是在编译期间执行字符串中的 JavaScript 代码,然后将执行的结果替换到相应的地方,如上的代码在编译期会被展开为:
import preval from 'preval.macro' const one = 1
从使用来方式来看,唯一与识别宏沾点关系的就是*.macro字符,这也确实就是 Babel 如何识别宏的方式,实际上不仅对于*.macro的形式, Babel 认为库名匹配正则/[./]macro(\.c?js)?$/表达式的库就是 Babel 宏,这些匹配表达式的一些例子:
'my.macro' 'my.macro.js' 'my.macro.cjs' 'my/macro' 'my/macro.js' 'my/macro.cjs'
编写
接下来,我们将简单编写一个importURL宏,其作用是通过 url 来引入一些库,并在编译期间将这些库的代码预先拉取下来,处理一下然后引入到文件中。我知道有些 Webpack 插件已经支持 从 url 来引入库,不过这同样是一个很好的例子来学习如何编写宏,为了有趣!以及如何在 NodeJS 中发起同步请求! :)
准备
首先创建一个名为 importURL 的文件夹,执行npm init -y【文章来源:http://www.1234xp.com/mggfzq.html网络转载请说明出处】,来快速创建一个项目。在项目使用宏的人需要安装babel-plugin-macros,同样的,编写宏的同样需要安装这个插件,在写之前,我们也需要提前安装一些其他的库来辅助我们编写宏,在开发之前,需要事先:
- 在package.json将name改为import-url.macro,符合 Babel 识别宏的格式
- 我们需要用 Babel 提供的辅助方法来创建宏。执行yarn add babel-plugin-macros
- yarn add fs-extra,一个更容易使用的代替 Nodefs模块的库
- yarn add find-root,编写宏的过程我们需要根据所处理文件的路径找到其所在的工作目录,从而写入缓存,这是一个已经封装好的库
示例
我们的目标就是将如下代码转换成
import importURL from 'importurl.macros';
const React = importURL('https://unpkg.com/react@17.0.1/umd/react.development.js');
// 编译成
import importURL from 'importurl.macros';
const React = require('../cache/pkg1.js');
我们会解析代码 importURL 函数的第一个参数,当做远程库的地址,然后在编译期间同步的通过 Get 请求拉取代码内容。然后写入项目顶层文件夹下.chache下,并替换相应的 importURL 语句成require(...)语句,路径...则是使用importURL的文件相对.cache文件中的相对路径,使得 webpack 在最终打包的时候能够找到对应的代码。
开始
我们先看看最终的代码长什么样子
import { execSync } from 'child_process';
import findRoot from 'find-root';
import path from 'path';
import fse from 'fs-extra';
import { createMacro } from 'babel-plugin-macros';
const syncGet = (url) => {
const data = execSync(`curl -L ${url}`).toString();
if (data === '') {
throw new Error('empty data');
}
return data;
}
let count = 0;
export const genUniqueName = () => `pkg${++count}.js`;
module.exports = createMacro((ctx) => {
const {
references, // 文件中所有对宏的引用
babel: {
types: t,
}
} = ctx;
// babel 会把当前处理的文件路径设置到 ctx.state.filename
const workspacePath = findRoot(ctx.state.filename);
// 计算出缓存文件夹
const cacheDirPath = path.join(workspacePath, '.cache');
//
const calls = references.default.map(path => path.findParent(path => path.node.type === 'CallExpression' ));
calls.forEach(nodePath => {
// 确定 astNode 的类型
if (nodePath.node.type === 'CallExpression') {
// 确定函数的第一个参数是纯字符串
if (nodePath.node.arguments[0]?.type === 'StringLiteral') {
// 获取一个参数,当做远程库的地址
const url = nodePath.node.arguments[0].value;
// 根据 url 拉取代码
const codes = syncGet(url);
// 生成一个唯一包名,防止冲突
const pkgName = genUniqueName();
// 确定最终要写入的文件路径
const cahceFilename = path.join(cacheDirPath, pkgName);
// 通过 fse 库,将内容写入, outputFileSync 会自动创建不存在的文件夹
fse.outputFileSync(cahceFilename, codes);
// 计算出相对路径
const relativeFilename = path.relative(ctx.state.filename, cahceFilename);
// 最终计算替换 importURL 语句
nodePath.replaceWith(t.stringLiteral(`require('${relativeFilename}')`))
}
}
});
});
创建一个宏
我们通过createMacro函数来创建一个宏,createMacro接受我们编写的函数当做参数来生成一个宏,但实际上我们并不关心createMacro的返回时值是什么,因为我们的代码最终都将会被自己替换掉,不会在运行期间执行到。 我们编写的函数的第一个参数是 Babel 传递给我们的一些状态,我们可以大概看下其类型都有什么。
function createMacro(handler: MacroHandler, options?: Options): any;
interface MacroParams {
references: { default: Babel.NodePath[] } & References;
state: Babel.PluginPass;
babel: typeof Babel;
config?: { [key: string]: any };
}
export interface PluginPass {
file: BabelFile;
key: string;
opts: PluginOptions;
cwd: string;
filename: string;
[key: string]: unknown;
}
可视化 AST
我们可以通过astexplorer来观察我们将要处理代码的语法树,对于如下代码
import importURL from 'importurl.macros';
const React = importURL('https://unpkg.com/react@17.0.1/umd/react.development.js');
会生成如下语法树
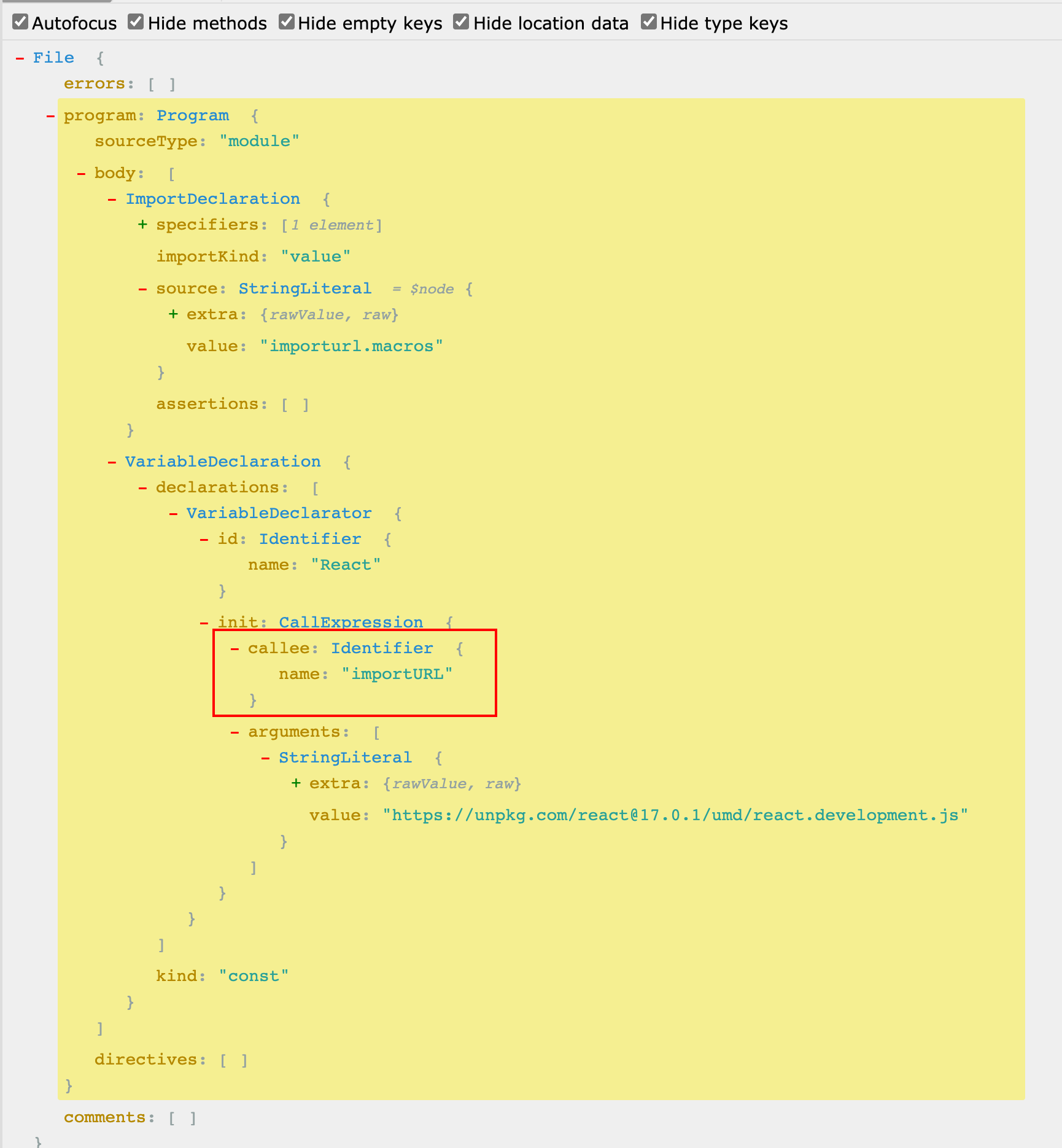
红色标红的语法树节点,就是 Babel 会通过ctx.references传递给我们的,因此我们需要通过.findParent()方法来向上找到父节点CallExpresstion,才能去获取arguments属性下的参数,拿到远程库的 URL 地址。
同步请求
这里的一个难点在于, Babel 不支持异步转换,所有的转换操作都是同步的,因此在发起请求时也必须是同步的请求。我本来以为这是一件很简单的事情, Node 会提供一个类似sync: true的选项。但是并没有的, Node 确实不支持任何同步请求,除非你选择用下面这种很怪异的方式
const syncGet = (url) => {
const data = execSync(`curl -L ${url}`).toString();
if (data === '') {
throw new Error('empty data');
}
return data;
}
收尾
在拿到代码后,我们将代码写入到开始计算出的文件路径中,这里我们使用fs-extra的目的在于,fs-extra在写入的时候如果遇到不存在文件夹,不会像fs一样直接抛出错误,而是自动创建相应的文件件。在写入完成后,我们通过 Babel 提供的辅助方法stringLiteral创字符串节点,随后替换掉我们的importURL(...),自此我们的整个转换流程就结束了。
最后
这个宏存在一些缺陷,有兴趣的同学可以继续完善:
没有识别同一 URL 的库,进行复用,不过我想这些已经满足如何编写一个宏的目的了。
genUniqueName在跨文件是会计算出重复包名,正确的算法应该是根据 url 计算哈希值来当做唯一包名
到此这篇关于在JavaScript中如何使用宏的文章就介绍到这了,更多相关JavaScript使用宏内容请搜索海外IDC网以前的文章或继续浏览下面的相关文章希望大家以后多多支持海外IDC网!
【转自:香港服务器 https://www.68idc.cn提供,感谢支持】