
Python 删除文件每一行的行号思路解读
目录
- 1. what
- 2. 思路
- 3. 代码
1. what
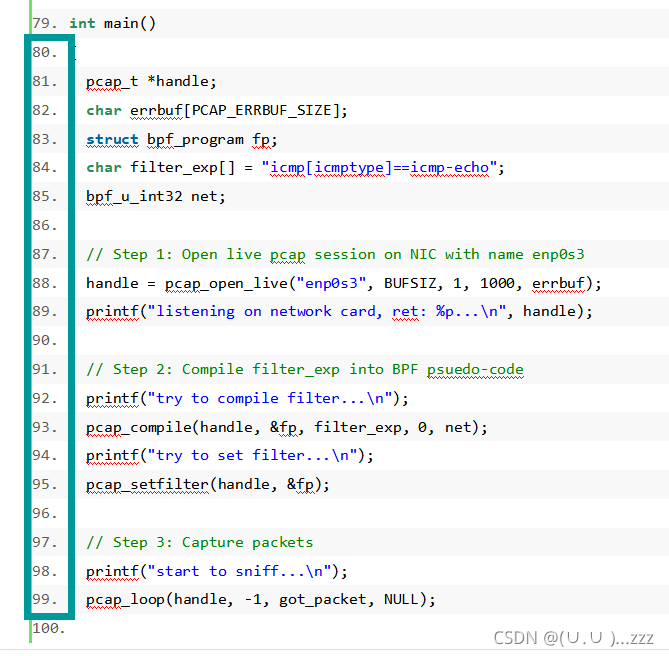
这个行号真的很烦噶 试着写一个py去掉
2. 思路
def second_of_str分割,取分隔符右边的元素返回一个列表def move传入文件路径,读取每行,列表存储,调用 second_of_str分割后的存入新列表- 主函数调用move
3. 代码
def second_of_str(str,splitsymbol):
s = str.split(splitsymbol,1) # 分隔符右边的元素
# if len(s) == 1:
# return []
return s[1]
def move(file_path, new_file_path):
with open(file_path,encoding='utf-8') as f:
content = f.read().splitlines()
# for line in content:
# print(line)
new_content = []
for line in content:
new_line = second_of_str(line,'.')
# 去掉后的每行加入新列表
new_content.append(new_line)
for line in new_content:
print(line)
f1 = open(new_file_path,encoding='utf-8',mode = 'w')
for line in new_content:
f1.writelines(line)
f1.writelines(["\n"])
f1.close()
return new_content
if __name__ == '__main__':
f = move('1.txt','2.txt')
完成啦,成果~
到此这篇关于Python 删除文件每一行的行号思路解读的文章就介绍到这了,更多相关Python 删除文件行号内容请搜索hwidc以前的文章或继续浏览下面的相关文章希望大家以后多多支持hwidc!