
C语言编程数据结构线性表之顺序表和链表原理分
目录
- 线性表的定义和特点
- 线性结构的特点
- 线性表
- 顺序存储
- 顺序表的元素类型定义
- 顺序表的增删查改
- 初始化顺序表
- 扩容顺序表
- 尾插法增加元素
- 头插法
- 任意位置删除
- 任意位置添加
- 线性表的链式存储
- 数据域与指针域
- 初始化链表
- 尾插法增加链表结点
- 头插法添加链表结点
- 打印链表
- 任意位置的删除
- 双向链表
- 测试双向链表(主函数)
- 初始化双向链表
- 头插法插入元素
- 尾插法插入元素
- 尾删法删除结点
- 头删法删除结点
- doubly-Linked list.c文件
- doubly-Linkedlist.h
线性表的定义和特点
线性结构的基本特点:除第一个元素无直接前驱,最后一个元素无直接后继,其他元素都有一个前驱和一个后继。
说人话就是:第一个元素不能向前访问,最后一个元素不能向后访问,中间的元素都可以前后访问其他元素。
例如:26个字母表{A,B,C,D,E,F…}就是一个线性表.
虽然该线性表中数据元素各不相同,但每个元素都具有相同的特性,都属于同一数据对象
线性表:由有限个数据特性相同的数据元素构成的有限序列
如果没有数据元素,该线性表也叫空表。
线性结构的特点
1,存在唯一 一个“第一个”与“最后一个”数据元素
2,出第一个和最后一个数据元素,其余元素都有一个前驱和一个后驱
解释一下:前驱和后继就是逻辑关系中的上一个元素和下一个元素
我原先以为是指针之类的。
线性表
线性表的长度可以根据需要增长或减小。还拥有任意位置的插入和删除
线性表分为顺序表和链表
顺序存储
线性表的顺序存储就是顺序表,是指**一组地址连续的存储单元依次存储的数据元素。**实际就是每个元素都是依次储存在地址连续的空间(简称:数组)。对于顺序存储而言,逻辑上是连续的,其物理次序上也是连续的
来看一张图增强一下理解(这是我写顺序存储的习惯,可能会存在差异)

对于线性表的顺序存储的而言,每个数据元素都可以通过下标来快速访问,读取。正规来说就是随机存取
顺序表的元素类型定义
这是我对顺序存储的结构体类型的定义
#define N 8
typedef struct elem
{
int element;//每个数据元素中的数据项
}sel;
typedef struct seq
{
sel* arr;//动态开辟的线性表空间的首地址,通过这个指针访问到线性表空间
int size;//当前已经使用了的空间的个数
int capacity;//当前的最大的数据元素容量
}sl;
这里我为了简单一些描述,我直接使用了每个数据元素都相当于只有int 类型的数据项。
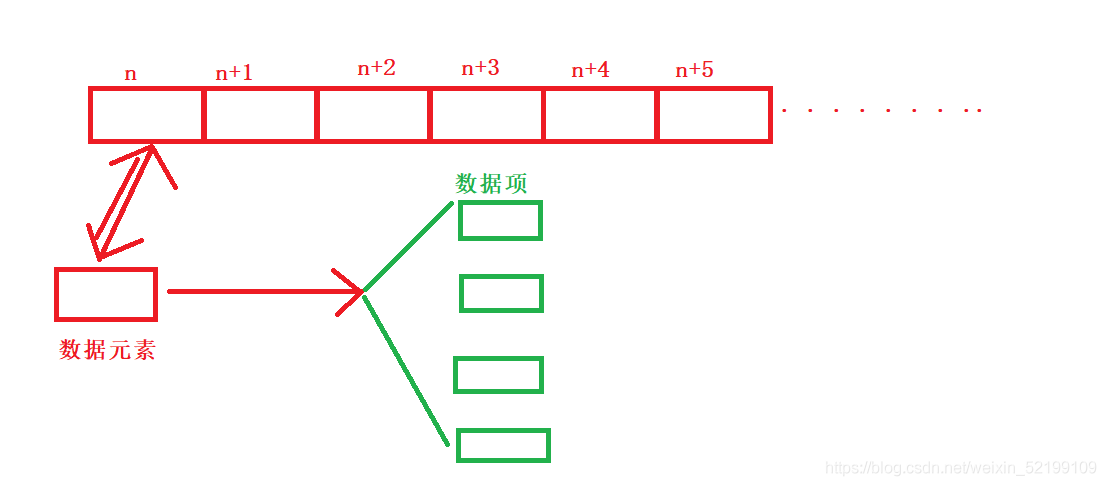
其实就是跟通讯录一样,每个数据元素都是一个人的全部信息的集合(应该可以这么说吧),而数据项就是每个元素中包含的一部分。
顺序表的增删查改
对于顺序表来说,绝大部分可以当成数组进行操作,当然,也就是要考虑顺序的容量问题,是否需要扩容的几个动态变化问题。
初始化顺序表
void initsequence(sl* a)//初始化动态顺序表
{
a->size = 0;//数组元素以0开始计算,size是最后一个元素的下标,不是元素总数量
a->capacity = N;//N在上面已经define了
a->arr = (sel*)malloc(sizeof(int) * N);
}
扩容顺序表
void checkcapacity(sl* a)//检查是否需要扩容
{
if (a->size +1== a->capacity)
{
a->capacity *= 2;
a->arr =(sel*) realloc( a->arr,sizeof(int) * (a->capacity));
if (a->arr == NULL)
{
printf("realloc defect");
exit(-1);
}
}
}
扩容是当准备对顺序表的元素进行操作时元素个数已经达到最大容量时,由于我们的size是下标,就要加一。因为我们准备扩容,所以是不会允许size>=capacity。
同时,扩容不能一次性扩太多,否则或导致空间浪费。
又不能扩太少,少了就要多次扩容,会增加消耗。
所以,自己看情况吧。嘻嘻~
尾插法增加元素
void sequpushfront(sl* a,sel* ele)//尾插法
{
checkcapacity(&a);//检查是否需要扩容
*(a->arr + a->size) =ele->element;//因为我只设置了一个int类型的如果数据元素中有多个数据项向下看
++(a->size);
}
void sequpushfront(sl* a,sel* ele)//尾插法
{
checkcapacity(&a);//检查是否需要扩容
(a->arr + a->size)->n =ele->element;//假设是有多个数据项就这样依次匹配(a->arr + a->size)已经访问到每个元素的地址再->n访问到相应元素的空间进行存储。
++(a->size);
}
尾插法没那么复杂,检查一下扩容,直接在后面放入元素就行。
下面我就不再举例了,举一反三很容易的。
头插法
void sequpushback(sl* a, int n)//头插法
{
checkcapacity(&a);//检查是否需要扩容
int head = 0;
int end = a->size;
while (end>=head)
{
*(a->arr + end + 1) = *(a->arr + end);
--end;
}
++(a->size);
*(a->arr + head) = n;
}
头插法就需要将放入位置后的元素全部向后移动一个位置。
但是,怎么移又是要考虑一下的问题。
是从前向后开始移动,还是从最后一个元素开始移动。
如果是从前向后移动
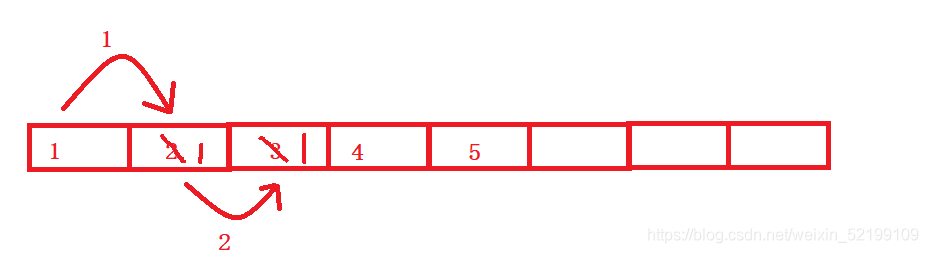
会造成这个样子,后面元素就一直是1,则,这种方法就是错误的。
再来看看从后向前移动
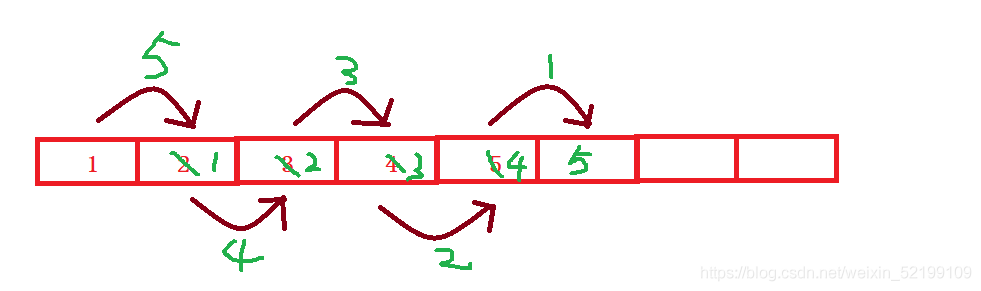
这种方法是可以行的通的。
先扩容
再元素向后移,再头插。
void sequpushback(sl* a, sel* ele)//头插法
{
checkcapacity(&a);//检查是否需要扩容
int head = 0;
int end = a->size;
while (end>=head)
{
*(a->arr + end + 1) = *(a->arr + end);
--end;
}
++(a->size);
*(a->arr + head) = ele->element;
}
任意位置删除
删除就不头删尾删了,直接任意位置删除。
找到那个元素的下标,再开始向前覆盖
对于删除而言,元素移动又是一个麻烦事。
这次我们对于删除而言,元素得从前向后开始移动。
void sequpopmid(sl* a, int n)//中间删除,n是要删除的位置
{
assert(n>=0&&n<=a->size);
for (int i = n ; i < a->size-1; i++)
{
*(a->arr + i) = *(a->arr + i + 1);
}
--(a->size);
}
删除后要将边界也就是size自减,防止越界。
任意位置添加
传要添加的位置,再开始向后移动。
void sequpushmid(sl* a, int n,sel* ele)//中间添加
{
assert(n>=0&&n=<a->size+1);//要在有效位置添加
checkcapacity(&a);//检查是否需要扩容
int head = n;
int end = a->size;
while (end>=head)
{
*(a->arr + end + 1) = *(a->arr + end);
--end;
}
++(a->size);
*(a->arr + head) = ele->element;
}
其实就是头插法的一种变形。
小总结
对于数组删除元素,要从前向后开始移动。
而对于数组增加元素,要从后向前开始移动。
同时删除添加的位置都要符合条件,不能越界。
线性表的链式存储
该存储结构的存储特点是:用一组任意的存储单元存储线性表的数据元素。(这组存储单元可以是连续的也可以是不连续的,简称:随机分布的存储单元)
数据域与指针域
而每个分配到存储单元都要分为两个部分:数据域与指针域。
这两个域或者信息组成数据元素的存储映像。是逻辑层次的元素在物理层次的投影。也叫结点。
- 数据域:储存每个数据元素,包括各个数据项
- 指针域:储存一个指针,也就是下一个结点的地址
注意,链式储存也就是链表,其每个结点的地址都是随机的,并不是像顺序表一样,每个空间依次排列。
链表有超多种结构,如:单链表,单向/双向循环链表,双向链表,二叉链表,十字链表,邻链表,邻接多重表等。
本文主要分析单链表,循环链表,双向链表。其余的暂时不分析(其实是我不会,目前比较菜),以后会补充分析。
数据结构最好先画图,这样可以增强理解与分析。
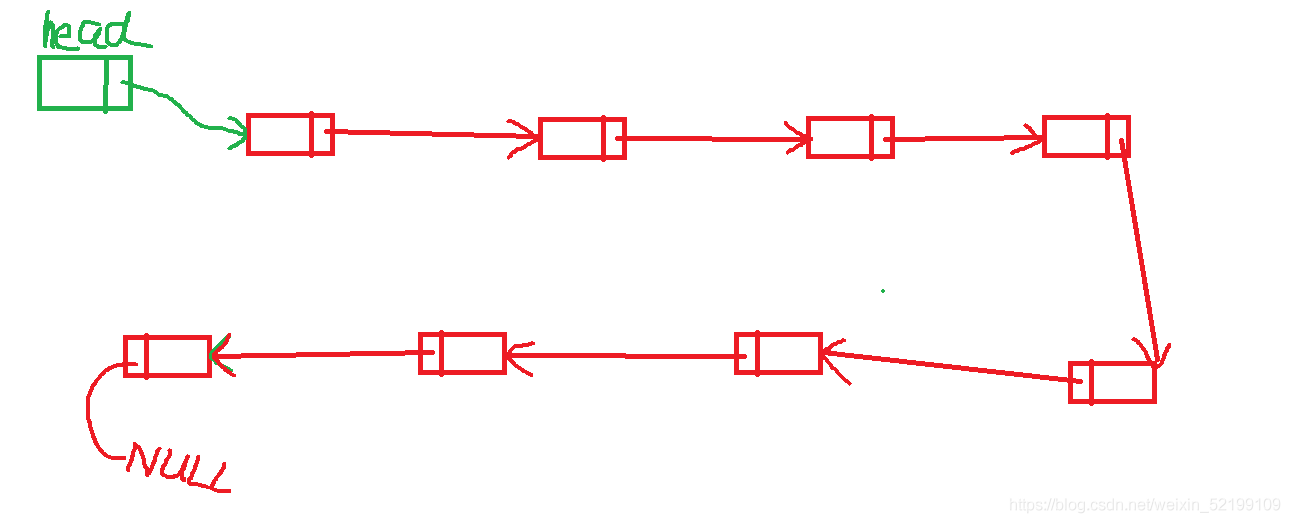
大致了解一下链表的结构。
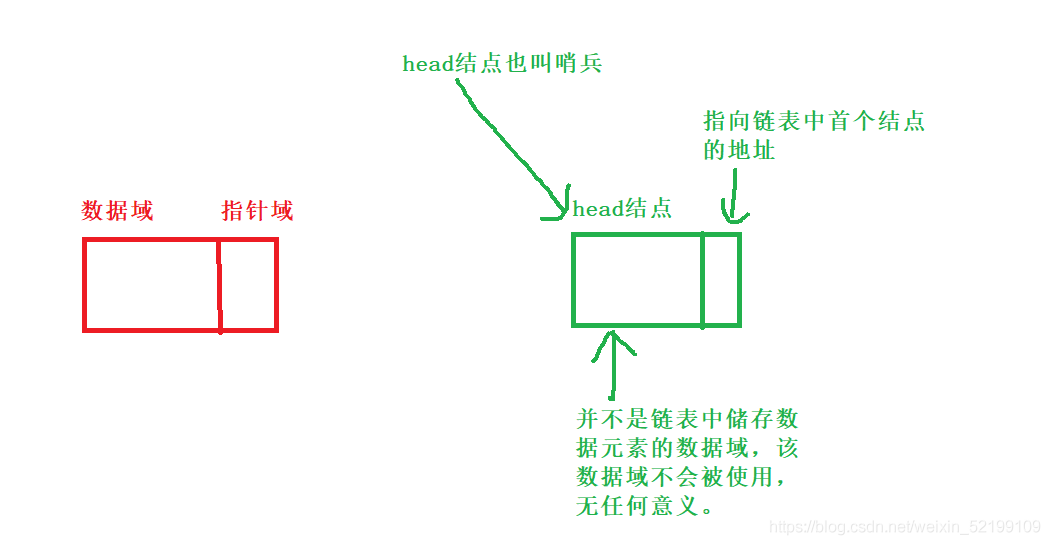
由于链表中的每个结点的物理关系是不确定的,是随机的,就需要靠指针域来表示,构成逻辑关系。指针指向是十分重要的。
这个哨兵位的头节点的可要可不要的。
#include "linkedlist.h"
void test()
{
list* head;
list* last;
initLinkedlist(&head,&last);
pushlast(&last, 1);//尾插法
pushlast(&last, 2);
pushlast(&last, 3);
pushlast(&last, 4);
pushfront(&head, 5);//头插法
pushfront(&head, 8);//头插法
pushfront(&head, 7);//头插法
pushfront(&head, 6);//头插法
popchoice(&head, 0);//任意位置删除
//poshposition(&head, 3);//任意位置插入
printlist(&head);//打印
}
int main(void)
{
test();
return 0;
}
先分析哨兵位的链表,好理解
初始化链表
void initLinkedlist(list** head,list** last)//初始化链表
{
*head = (list*)malloc(sizeof(list));
(*head)->next = NULL;
*last=*head;
}
head就是哨兵位,而这个last,是要来定位最后一个结点,当last指向head时,就代表是一个空表。
由于我是在测试函数中创建了哨兵结点和尾结点指针,所以要对指针进行操作得传一个二级指针,传址调用才能才能对链表进行影响。
当尾结点指向哨兵结点时,表示是一个空表。
尾插法增加链表结点
void pushlast(list** last, int num)//尾插法
{
list* new = (list*)malloc(sizeof(list));
new->n = num;
new->next = (*last)->next;
(*last)->next = new;
(*last) = new;
}
要在尾结点,也就是last结点。
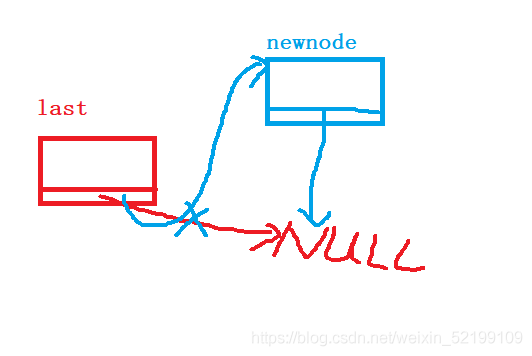
尾插结点图解,就是这样的。
同时,当last->next的指向newnode后,last也要再移向newnode,因为newnode变成了尾结点,下次插入会在这次newnode的后面进行插入。
头插法添加链表结点
void pushfront(list** head, int num)//头插法
{
list* new = (list*)malloc(sizeof(list));
new->n = num;
new->next = (*head)->next;
(*head)->next = new;
}
要在哨兵位后进行插入,每次插入都要满足在哨兵位节点后进行。
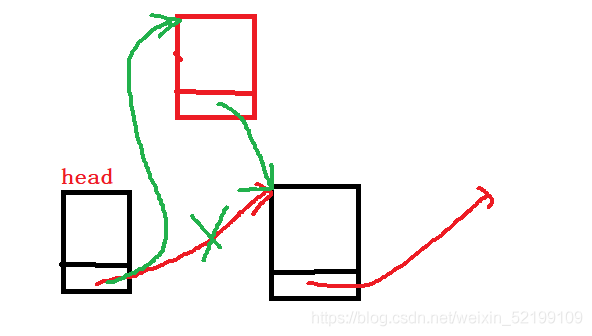
而哨兵位结点是始终不变的,我们可以通过这样的操作不断头插。
打印链表
void printlist(list** head)//打印
{
list* p = (*head)->next;
while (p)
{
printf("%d ", p->n);
p = p->next;
}
}
从哨兵位结点进行遍历,依次打印。
任意位置的删除
void popchoice(list** head, int pos)//任意位置删除
{
assert(pos<8&pos>=0);
int i = 0;
list* pre = *head;
list* cur = (*head)->next;
while (i < pos)
{
pre = cur;
cur = cur->next;
i++;
}
pre->next = cur->next;
free(cur);
}
由于是有哨兵位的链表,在任意位置删除还好,但无哨兵位的链表,就有一些麻烦。
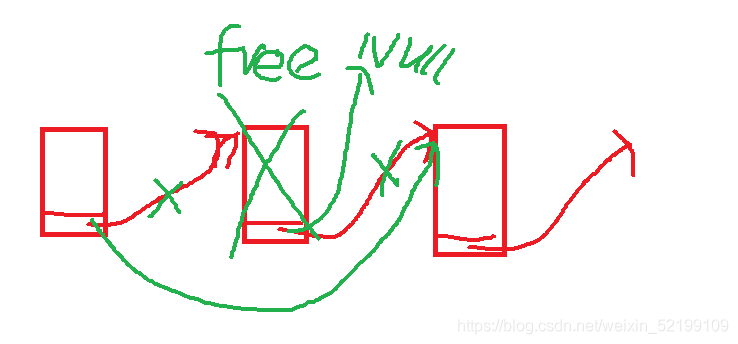
虽然差不多的变化。因位要保存结点的前一个结点地址,当没有哨兵位的时候就需要if判断一下。其实也没多麻烦。
任意位置插入和删除是一样的。
双向链表
这是另一种链式结构。
每个结点都具有两个指针,一个指向上一个逻辑关系结点,一个指向下一个逻辑关系结点。
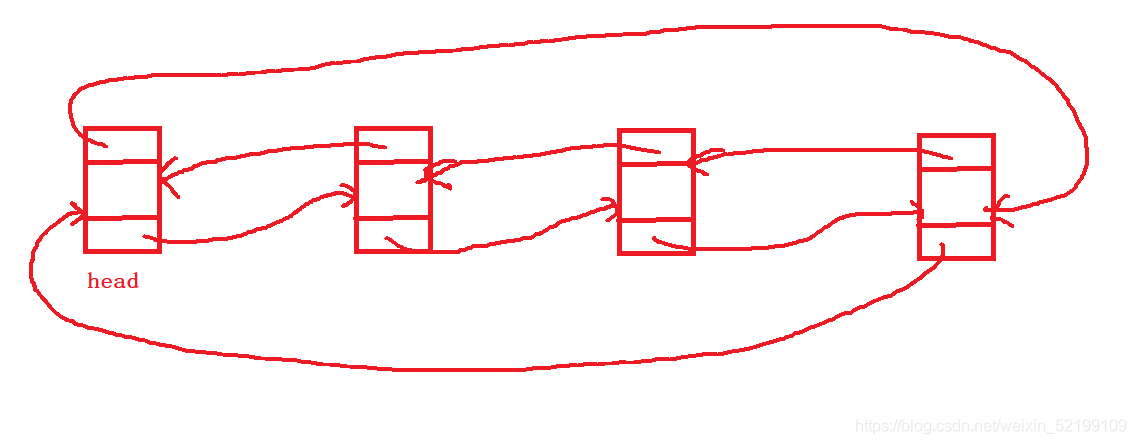
这一般使用一个哨兵位的结点,可以创建使用双向链表的步骤更简单。
对于双向链表与单链表而言,双向链表在链表的插入,删除以及多个操作上更具有优势。
如:尾插。
对于单链表,要指针遍历找到尾结点,再插入。时间复杂度为O(N).
而双向链表,他的头结点的prev指针指向了最后一个结点,根本不需要依次遍历。
像一些插入操作
如:前插
单链表都要准备两个指针。
而双向链表直接访问prev指针就可以找到上一个结点。
虽然,指针较多可能比单链表麻烦,但整体操作上,却要简单。
而且,在以后的很多结构上,单链表都不会拿出来单独使用,而是作为某个数据结构的一部分。双向链表才是会作为一个主体来使用。
测试双向链表(主函数)
#include "doubly_Linkedlist.h"
void doublelinkedlist1()
{
doulink head;
initlinkedlist(&head);//初始化双向链表
LinkedlistFrontPush(&head, 1);//头插法
LinkedlistFrontPush(&head, 2);//头插法
LinkedlistFrontPush(&head, 3);//头插法
LinkedlistFrontPush(&head, 4);//头插法
LinkedlistFrontPush(&head, 5);//头插法
LinkedlistBackpush(&head, 6);//尾插法
LinkedlistBackpush(&head, 7);//尾插法
LinkedlistBackpush(&head, 8);//尾插法
LinkedlistBackpush(&head, 9);//尾插法
LinkedlistBackpush(&head, 10);//尾插法
LinkedlistFrontPop(&head);//头删
LinkedlistFrontPop(&head);//头删
LinkedlistFrontPop(&head);//头删
LinkedlistBackPop(&head);//尾删
LinkedlistBackPop(&head);//尾删
LinkedlistBackPop(&head);//尾删
LinkedlistBackPop(&head);//尾删
LinkedlistBackPop(&head);//尾删
LinkedlistPrint(&head);//打印链表
}
int main(void)
{
doublelinkedlist1();
}
因为我是创建了一个结构体变量,要对其进行操作,需要传址调用,如果传值调用会,导致实际上哨兵并未改变,只是改变了函数中的形参。
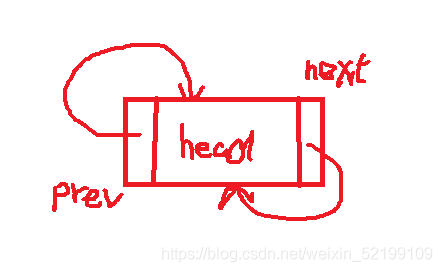
初始化双向链表
void initlinkedlist(doulink* head)//初始化双向链表
{
(*head).next = head;
(*head).prev = head;
}
因为双向链表要形成一个闭环,初始化时也要形成闭环
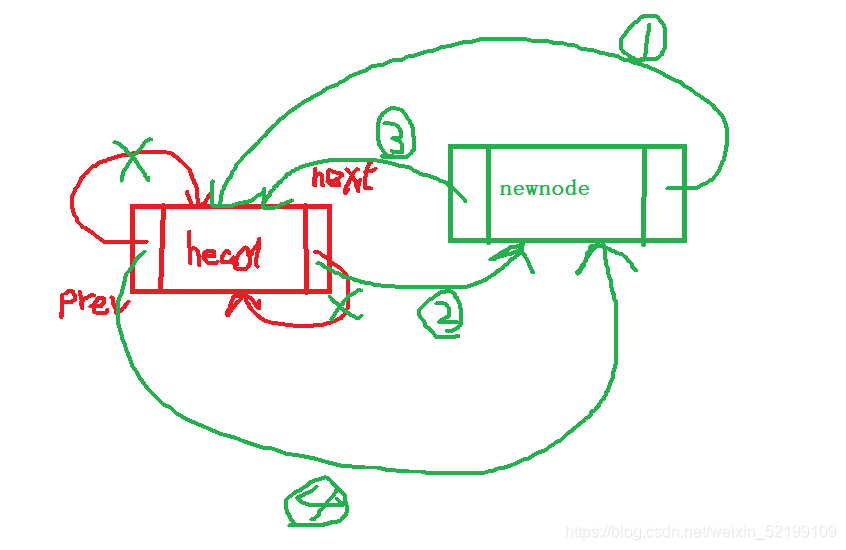
头插法插入元素
void LinkedlistFrontPush(doulink* head, lint n)//头插法
{
doulink* newnode = (doulink*)malloc(sizeof(doulink));
newnode->num = n;
doulink*phead=(*head).next;//原头节点
newnode->next = phead;//新的后驱指针接入下一个
(*head).next = newnode;//将哨兵链接新结点
newnode->prev = head;//新结点的前驱指针指向哨兵
phead->prev = newnode;//原头结点的前驱指针指向新的头节点
}
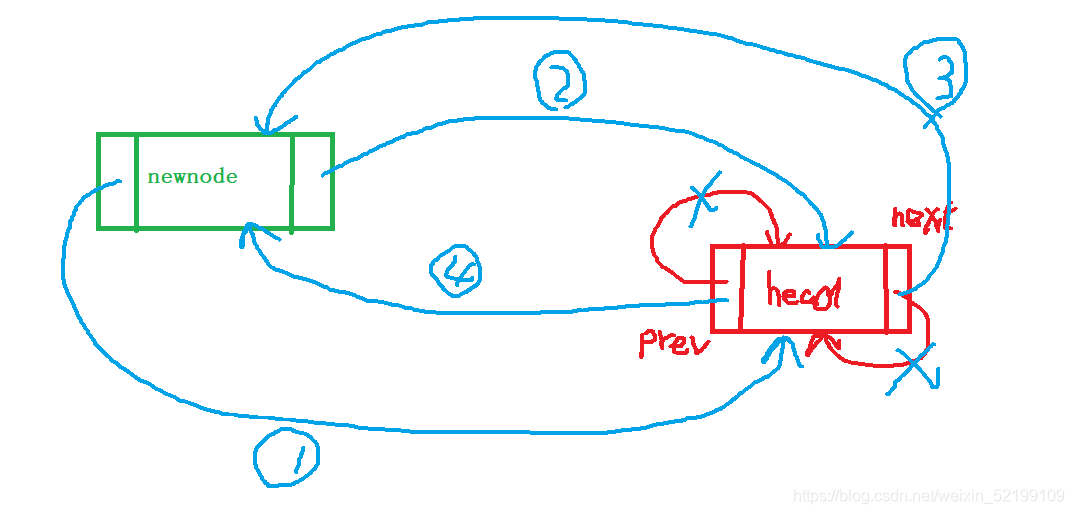
尾插法插入元素
void LinkedlistBackpush(doulink* head, lint n)//尾插法
{
doulink* newnode = (doulink*)malloc(sizeof(doulink));
newnode->num = n;
doulink* plast = (*head).prev;//找到尾结点
newnode->prev = plast;//新的尾接入原尾结点
newnode->next = plast->next;//新接入哨兵
plast->next = newnode;//原尾结点next指向新的尾
(*head).prev = newnode;//头节点的prev指向新的尾结点,形成闭环
}
有链表中多个结点的情况
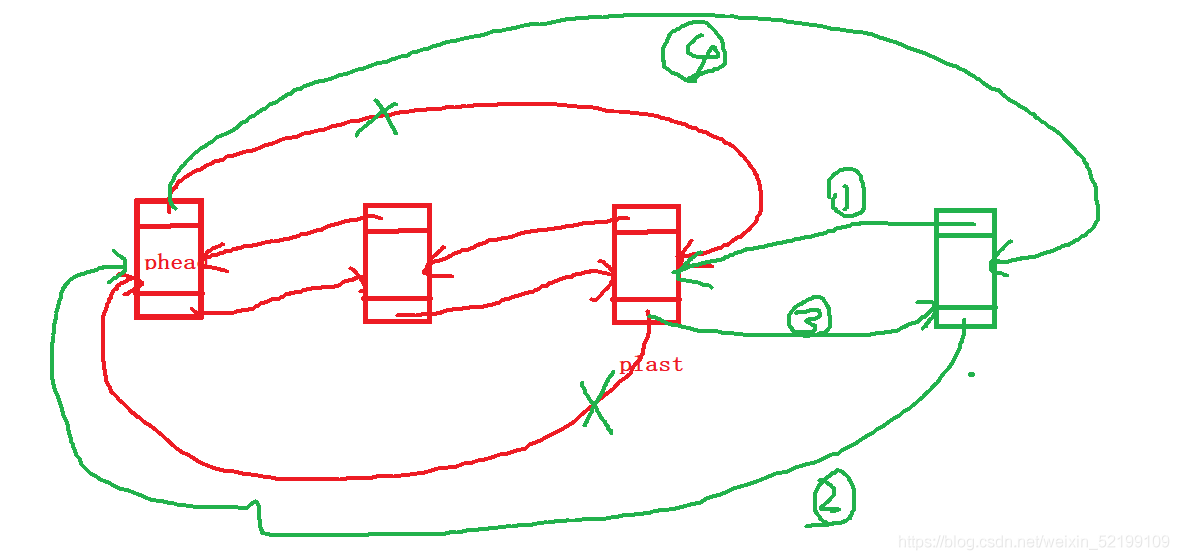
尾删法删除结点
void LinkedlistBackPop(doulink* head)//尾删
{
doulink* last = (*head).prev;//找到要删除的尾结点
doulink* llast = last->prev;//找到删除后的新的尾结点
if (last == head)
{
printf("Empty List\n");
return;
}
(*head).prev = llast;//改变哨兵结点prev指向
llast->next = last->next;//让新的尾结点的next接入哨兵
free(last);//删除内存
}
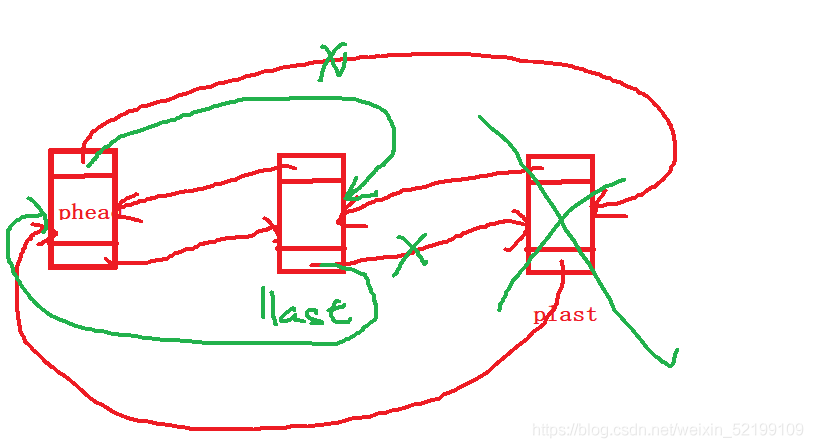
头删法删除结点
void LinkedlistFrontPop(doulink* head)//头删
{
doulink* phead = (*head).next;
doulink* second = phead->next;
if (phead == head)
{
printf("Empty List\n");
return;
}
second->prev = phead->prev;
(*head).next = second;
free(first);
}
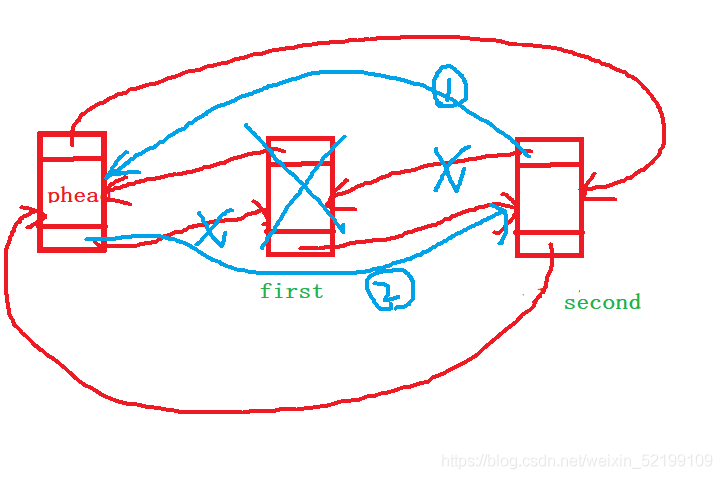
对于头插尾插,尾删头删,一定要注意顺序,不然可能会导致指针指向错误的地方。
而对于双向链表的删除插入,不需要多个指针,这样要方便很多。
以下是代码的全部主体
doubly-Linked list.c文件
#include "doubly_Linkedlist.h"
void initlinkedlist(doulink* head)//初始化双向链表
{
(*head).next = head;
(*head).prev = head;
}
void LinkedlistFrontPush(doulink* head, lint n)//头插法
{
doulink* newnode = (doulink*)malloc(sizeof(doulink));
newnode->num = n;
doulink*phead=(*head).next;//原头节点
newnode->next = phead;//新的后驱指针接入下一个
(*head).next = newnode;//将哨兵链接新结点
newnode->prev = head;//新结点的前驱指针指向哨兵
phead->prev = newnode;//原头结点的前驱指针指向新的头节点
}
void LinkedlistBackpush(doulink* head, lint n)//尾插法
{
doulink* newnode = (doulink*)malloc(sizeof(doulink));
newnode->num = n;
doulink* plast = (*head).prev;//找到尾结点
newnode->prev = plast;//新的尾接入原尾结点
newnode->next = plast->next;//新接入哨兵
plast->next = newnode;//原尾结点next指向新的尾
(*head).prev = newnode;//头节点的prev指向新的尾结点,形成闭环
}
void LinkedlistFrontPop(doulink* head)//头删
{
doulink* phead = (*head).next;
doulink* second = phead->next;
if (phead == head)
{
printf("Empty List\n");
return;
}
second->prev = phead->prev;
(*head).next = second;
}
void LinkedlistBackPop(doulink* head)//尾删
{
doulink* last = (*head).prev;//找到要删除的尾结点
doulink* llast = last->prev;//找到删除后的新的尾结点
if (last == head)
{
printf("Empty List\n");
return;
}
(*head).prev = llast;//改变哨兵结点prev指向
llast->next = last->next;//让新的尾结点的next接入哨兵
free(last);
}
void LinkedlistPrint(doulink* head)//打印链表
{
doulink* cur = (*head).next;
while (cur != head)
{
printf("%d ", cur->num);
cur = cur->next;
}
}
doubly-Linkedlist.h
#pragma once
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
typedef int lint;
typedef struct doulinked
{
lint num;
lint* prev;
lint* next;
}doulink;
void initlinkedlist(doulink* head);//初始化双向链表
void LinkedlistFrontPush(doulink* head, lint n);//头插法
void LinkedlistBackpush(doulink* head, lint n);//尾插法
void LinkedlistFrontPop(doulink* head);//头删
void LinkedlistBackPop(doulink* head);//尾删
void LinkedlistPrint(doulink* head);//打印链表
以上就是C语言编程数据结构线性表之顺序表和链表原理分析的详细内容,更多关于C语言数据结构线性表顺序表和链表的资料请关注海外IDC网其它相关文章!
感谢阅读~