
C++11各种锁的具体使用
目录
- Mutex(互斥锁)
- 什么是互斥量(锁)?
- 条件变量condition_variable:
- condition_variable的wait
- std::shared_mutex
- 原子操作
Mutex(互斥锁)
什么是互斥量(锁)?
这样比喻:单位上有一台打印机(共享数据a),你要用打印机(线程1要操作数据a),同事老王也要用打印机(线程2也要操作数据a),但是打印机同一时间只能给一个人用,此时,规定不管是谁,在用打印机之前都要向领导申请许可证(lock),用完后再向领导归还许可证(unlock),许可证总共只有一个,没有许可证的人就等着在用打印机的同事用完后才能申请许可证(阻塞,线程1lock互斥量后其他线程就无法lock,只能等线程1unlock后,其他线程才能lock)。那么,打印机就是共享数据,访问打印机的这段代码就是临界区,这个必须互斥使用的许可证就是互斥量(锁)。
互斥量是为了解决数据共享过程中可能存在的访问冲突的问题。这里的互斥量保证了使用打印机这一过程不被打断。
死锁
多线程编程时要考虑多个线程同时访问共享资源所造成的问题,因此可以通过加锁解锁来保证同一时刻只有一个线程能访问共享资源;使用锁的时候要注意,不能出现死锁的状况;
死锁就是多个线程争夺共享资源导致每个线程都不能取得自己所需的全部资源,从而程序无法向下执行。
产生死锁的四个必要条件(面试考点):
互斥(资源同一时刻只能被一个进程使用)请求并保持(进程在请资源时,不释放自己已经占有的资源)不剥夺(进程已经获得的资源,在进程使用完前,不能强制剥夺)循环等待(进程间形成环状的资源循环等待关系) 互斥量mutex
互斥量mutex就是互斥锁,加锁的资源支持互斥访问
直接操作 mutex,即直接调用 mutex 的 lock / unlock 函数
#include <iostream>
#include <mutex>
#include <thread>
#include <vector>
std::mutex g_mutex;
int g_count = 0;
void Counter() {
g_mutex.lock();
int i = ++g_count;
std::cout << "count: " << i << std::endl;
// 前面代码如有异常,unlock 就调不到了。
g_mutex.unlock();
}
int main() {
const std::size_t SIZE = 4;
// 创建一组线程。
std::vector<std::thread> v;
v.reserve(SIZE);
for (std::size_t i = 0; i < SIZE; ++i) {
v.emplace_back(&Counter);
}
// 等待所有线程结束。
for (std::thread& t : v) {
t.join();
}
return 0;
}
lock_guard
使用 lock_guard 自动加锁、解锁。原理是 RAII,和智能指针类似。
#include <iostream>
#include <mutex>
#include <thread>
#include <vector>
std::mutex g_mutex;
int g_count = 0;
void Counter() {
// lock_guard 在构造函数里加锁,在析构函数里解锁。
std::lock_guard<std::mutex> lock(g_mutex);
int i = ++g_count;
std::cout << "count: " << i << std::endl;
}
int main() {
const std::size_t SIZE = 4;
std::vector<std::thread> v;
v.reserve(SIZE);
for (std::size_t i = 0; i < SIZE; ++i) {
v.emplace_back(&Counter);
}
for (std::thread& t : v) {
t.join();
}
return 0;
}
unique_lock
使用 unique_lock 自动加锁、解锁。
unique_lock 与 lock_guard 原理相同,但是提供了更多功能(比如可以结合条件变量使用)。
注意:mutex::scoped_lock 其实就是 unique_lock 的 typedef。
#include <iostream>
#include <mutex>
#include <thread>
#include <vector>
std::mutex g_mutex;
int g_count = 0;
void Counter() {
std::unique_lock<std::mutex> lock(g_mutex);
int i = ++g_count;
std::cout << "count: " << i << std::endl;
}
int main() {
const std::size_t SIZE = 4;
std::vector<std::thread> v;
v.reserve(SIZE);
for (std::size_t i = 0; i < SIZE; ++i) {
v.emplace_back(&Counter);
}
for (std::thread& t : v) {
t.join();
}
return 0;
}
std::recursive_mutex
就像互斥锁(mutex)一样,递归互斥锁(recursive_mutex)是可锁定的对象,但它允许同一线程获得对互斥锁对象的多级所有权(多次lock)。
这允许从已经锁定它的线程锁定(或尝试锁定)互斥对象,从而获得对互斥对象的新所有权级别:互斥对象实际上将保持对该线程的锁定,直到调用其成员 unlock 的次数与此所有权级别的次数相同。
#include <iostream>
#include <thread>
#include <mutex>
std::recursive_mutex mtx;
void print_block (int n, char c) {
mtx.lock();
mtx.lock();
mtx.lock();
for (int i=0; i<n; ++i) { std::cout << c; }
std::cout << '\n';
mtx.unlock();
mtx.unlock();
mtx.unlock();
}
int main ()
{
std::thread th1 (print_block,50,'*');
std::thread th2 (print_block,50,'$');
th1.join();
th2.join();
return 0;
}
std::timed_mutex
定时互斥锁是一个可时间锁定的对象,旨在通知何时关键代码需要独占访问,就像常规互斥锁一样,但还支持定时尝试锁定请求。
std::recursive_timed_mutex
递归定时互斥锁将 recursive_timed 和 timed_mutex 的功能结合到一个类中:它既支持通过单个线程获
取多个锁定级别又支持定时的 try_lock 请求。
成员函数与 timed_mutex 相同。
once_flag、call_once使用
在多线程中,有一种场景是某个任务只需要执行一次,可以用C++11中的std::call_once函数配合std::once_flag来实现。多个线程同时调用某个函数,std::call_once可以保证多个线程对该函数只调用一次
实现线程安全的单例模式
//h文件
#pragma once
#include <thread>
#include <iostream>
#include <mutex>
#include <memory>
class Task
{
private:
Task();
public:
static Task* task;
static Task* getInstance();
void fun();
};
//cpp文件
Task* Task::task;
Task::Task()
{
std::cout << "构造函数" << std::endl;
}
Task* Task::getInstance()
{
static std::once_flag flag;
std::call_once(flag, []
{
task = new Task();
});
return task;
}
void Task::fun()
{
std::cout << "hello world!"<< std::endl;
}
条件变量condition_variable:
需要#include<condition_variable>,该头文件中包含了条件变量相关的类,其中包括std::condition_variable类
如何使用?std::condition_variable类搭配std::mutex类来使用,std::condition_variable对象(std::condition_variable cond;)的作用不是用来管理互斥量的,它的作用是用来同步线程,它的用法相当于编程中常见的flag标志(A、B两个人约定flag=true为行动号角,默认flag为false,A不断的检查flag的值,只要B将flag修改为true,A就开始行动)。
类比到std::condition_variable,A、B两个人约定notify_one为行动号角,A就等着(调用wait(),阻塞),只要B一调用notify_one,A就开始行动(不再阻塞)。
std::condition_variable的具体使用代码实例可以参见文章中“生产者与消费者问题”章节。
wait(locker) :
wait函数需要传入一个std::mutex(一般会传入std::unique_lock对象),即上述的locker。wait函数会自动调用 locker.unlock() 释放锁(因为需要释放锁,所以要传入mutex)并阻塞当前线程,本线程释放锁使得其他的线程得以继续竞争锁。一旦当前线程获得notify(通常是另外某个线程调用 notify_* 唤醒了当前线程),wait() 函数此时再自动调用 locker.lock()上锁。
cond.notify_one(): 随机唤醒一个等待的线程
cond.notify_all(): 唤醒所有等待的线程
condition_variable的wait
std::condition_variable::wait 有两个重载:
void wait( std::unique_lock<std::mutex>& lock ); (1) (since C++11) template< class Predicate > void wait( std::unique_lock<std::mutex>& lock, Predicate pred ); (2) (since C++11)
void wait( std::unique_lockstd::mutex& lock )
先unlock之前获得的mutex,然后阻塞当前的执行线程。把当前线程添加到等待线程列表中,该线程会持续 block 直到被 notify_all() 或 notify_one() 唤醒。被唤醒后,该thread会重新获取mutex,获取到mutex后执行后面的动作。
线程block时候也可能被意外或者错误唤醒。
template< class Predicate > void wait( std::unique_lockstd::mutex& lock, Predicate pred );
该重载设置了第二个参数 Predicate, 只有当pred为false时,wait才会阻塞当前线程。盖崇仔等同于下面:
该情况下,线程被唤醒后,先重新判断pred的值。如果pred为false,则会释放mutex并重新阻塞在wait。因此,该mutex必须有pred的权限。该重载消除了意外唤醒的影响。
#include <iostream>
#include <thread>
#include <string>
#include <mutex>
#include <condition_variable>
#include <deque>
#include <chrono>
std::deque<int> q;
std::mutex mu;
std::condition_variable condi;
void function_1()
{
int count = 10;
while (count > 0)
{
std::unique_lock<std::mutex> locker(mu);
q.push_back(count);
locker.unlock();
condi.notify_one(); //通知一个等待线程激活 condi.notify_all()激活所有线程
count--;
std::this_thread::sleep_for(std::chrono::seconds(1));
}
}
void function_2()
{
int data = 100;
while (data > 1)
{
std::unique_lock<std::mutex> locker(mu);
condi.wait(locker, //解锁locker,并进入休眠 收到notify时又重新加锁
[]() { return !q.empty(); }); //如果q不为空 线程才会被激活
data = q.front();
q.pop_front();
locker.unlock();
std::cout << data << std::endl;
}
}
int main()
{
std::thread t1(function_1);
std::thread t2(function_2);
t1.join();
t2.join();
return 0;
}
std::shared_mutex
std::shared_mutex 是读写锁,提供两种访问权限的控制:共享性(shared)和排他性(exclusive)。通过lock/try_lock获取排他性访问权限,通过lock_shared/try_lock_shared获取共享性访问权限。这样的设置对于区分不同线程的读写操作特别有用。shared_mutex是c++17中引入的,使用时需要注意编译器版本。
#include <iostream>
#include <mutex> // For std::unique_lock
#include <shared_mutex>
#include <thread>
class ThreadSafeCounter {
public:
ThreadSafeCounter() = default;
// Multiple threads/readers can read the counter's value at the same time.
unsigned int get() const {
std::shared_lock lock(mutex_);
return value_;
}
// Only one thread/writer can increment/write the counter's value.
void increment() {
std::unique_lock lock(mutex_);
value_++;
}
// Only one thread/writer can reset/write the counter's value.
void reset() {
std::unique_lock lock(mutex_);
value_ = 0;
}
private:
mutable std::shared_mutex mutex_;
unsigned int value_ = 0;
};
int main() {
ThreadSafeCounter counter;
auto increment_and_print = [&counter]() {
for (int i = 0; i < 3; i++) {
counter.increment();
std::cout << std::this_thread::get_id() << ' ' << counter.get() << '\n';
// Note: Writing to std::cout actually needs to be synchronized as well
// by another std::mutex. This has been omitted to keep the example small.
}
};
std::thread thread1(increment_and_print);
std::thread thread2(increment_and_print);
thread1.join();
thread2.join();
}
原子操作
所谓原子操作,就是多线程程序中“最小的且不可并行化的”操作。对于在多个线程间共享的一个资源而言,这意味着同一时刻,多个线程中有且仅有一个线程在对这个资源进行操作,即互斥访问。提到“互斥”访问,熟悉多线程开发的同学可能立即想到Windows平台下使用的临界区/CRITICAL_SECTION、互斥体/Mutex。实现互斥通常需要平台相关的特殊指令,在C++11标准之前,这意味着需要在C/C++代码中嵌入平台相关的内联汇编代码。 平台相关意味着:1.你必须了解平台相关的编译器扩展;2.无法跨平台运行你的多线程程序。
多线程中需要同步的总是资源/数据,而不是代码。因此C++11对数据进行了更为良好的抽象,引入"原子数据类型"/atomic类型,以达到对开发者掩盖互斥锁、临界区的目的。要知道,这些临界区、互斥锁才是平台相关的东西。来看下面的示例代码。
#include<atomic>
#include<thread>
#include<iostream>
using namespace std;
std::atomic_llong total{ 0 };//原子数据类型
void func(int)
{
for (long long i = 0; i<100000000LL; ++i)
{
total += i;
}
}
int main()
{
thread t1(func, 0);
thread t2(func, 0);
t1.join();
t2.join();
cout<<total<<endl;//9999999900000000
return 0;
}
原子数据类型/atomic类型
atomic模板类
template <class T> struct atomic
//example
#include<atomic>
void test()
{
std::atomic_int nThreadData; // std::atomic_int <----> std::atomic<int>
nThreadData = 10;
nThreadData.store(10);
//TODO: use nThreadData here;
}
对于内置型数据类型,C11和C++11标准中都已经提供了实例化原子类型,如下表所示:
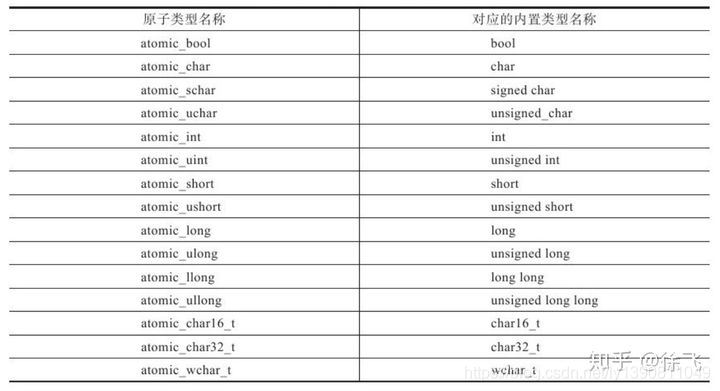
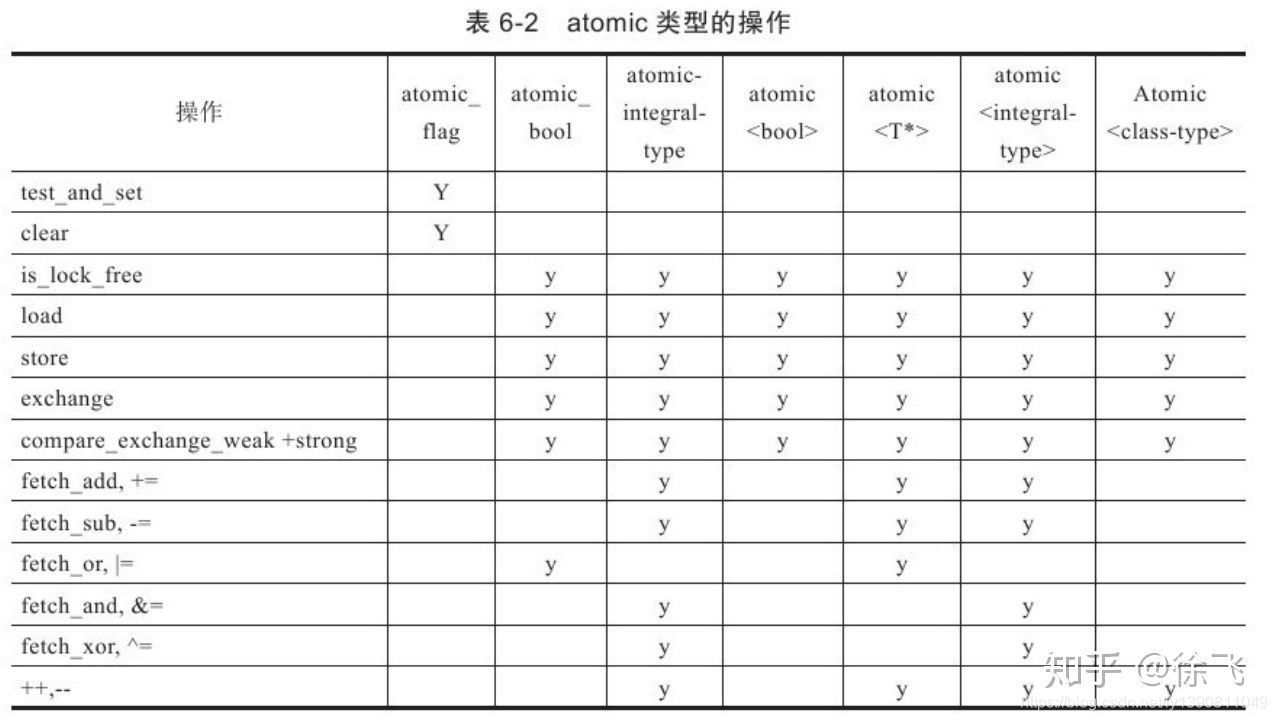
atomic类型原子操作接口如下
到此这篇关于C++11各种锁的具体使用的文章就介绍到这了,更多相关C++11各种锁内容请搜索海外IDC网以前的文章或继续浏览下面的相关文章希望大家以后多多支持海外IDC网!