
关于Android的 DiskLruCache磁盘缓存机制原理
目录
- 一、为什么用DiskLruCache
- 1、LruCache和DiskLruCache
- 2、为何使用DiskLruCache
- 二、DiskLruCache使用
- 1、添加依赖
- 2、创建DiskLruCache对象
- 3、添加 / 获取 缓存(一对一)
- 4、添加 / 获取 缓存(一对多)
- 三、源码分析
- 1、open()
- 2、rebuildJournal()
- 3、readJournal()
- 4、get()
- 5、validateKey
- 6、trimTOSize()
- 7、journalRebuildRequired()
- 8、save的过程
一、为什么用DiskLruCache
1、LruCache和DiskLruCache
LruCache和DiskLruCache两者都是利用到LRU算法,通过LRU算法对缓存进行管理,以最近最少使用作为管理的依据,删除最近最少使用的数据,保留最近最常用的数据;
LruCache运用于内存缓存,而DiskLruCache是存储设备缓存;
2、为何使用DiskLruCache
离线数据存在的意义,当无网络或者是网络状况不好时,APP依然具备部分功能是一种很好的用户体验;
假设网易新闻这类新闻客户端,数据完全存储在缓存中而不使用DiskLruCache技术存储,那么当客户端被销毁,缓存被释放,意味着再次打开APP将是一片空白;
另外DiskLruCache技术也可为app“离线阅读”这一功能做技术支持;
DiskLruCache的存储路径是可以自定义的,不过也可以是默认的存储路径,而默认的存储路径一般是这样的:/sdcard/Android/data/包名/cache,包名是指APP的包名。我们可以在手机上打开,浏览这一路径;
二、DiskLruCache使用
1、添加依赖
// add dependence implementation 'com.jakewharton:disklrucache:2.0.2'
2、创建DiskLruCache对象
/* * directory – 缓存目录 * appVersion - 缓存版本 * valueCount – 每个key对应value的个数 * maxSize – 缓存大小的上限 */ DiskLruCache diskLruCache = DiskLruCache.open(directory, 1, 1, 1024 * 1024 * 10);
3、添加 / 获取 缓存(一对一)
/**
* 添加一条缓存,一个key对应一个value
*/
public void addDiskCache(String key, String value) throws IOException {
File cacheDir = context.getCacheDir();
DiskLruCache diskLruCache = DiskLruCache.open(cacheDir, 1, 1, 1024 * 1024 * 10);
DiskLruCache.Editor editor = diskLruCache.edit(key);
// index与valueCount对应,分别为0,1,2...valueCount-1
editor.newOutputStream(0).write(value.getBytes());
editor.commit();
diskLruCache.close();
}
/**
* 获取一条缓存,一个key对应一个value
*/
public void getDiskCache(String key) throws IOException {
File directory = context.getCacheDir();
DiskLruCache diskLruCache = DiskLruCache.open(directory, 1, 1, 1024 * 1024 * 10);
String value = diskLruCache.get(key).getString(0);
diskLruCache.close();
}
4、添加 / 获取 缓存(一对多)
/**
* 添加一条缓存,1个key对应2个value
*/
public void addDiskCache(String key, String value1, String value2) throws IOException {
File directory = context.getCacheDir();
DiskLruCache diskLruCache = DiskLruCache.open(directory, 1, 2, 1024 * 1024 * 10);
DiskLruCache.Editor editor = diskLruCache.edit(key);
editor.newOutputStream(0).write(value1.getBytes());
editor.newOutputStream(1).write(value2.getBytes());
editor.commit();
diskLruCache.close();
}
/**
* 添加一条缓存,1个key对应2个value
*/
public void getDiskCache(String key) throws IOException {
File directory = context.getCacheDir();
DiskLruCache diskLruCache = DiskLruCache.open(directory, 1, 2, 1024);
DiskLruCache.Snapshot snapshot = diskLruCache.get(key);
String value1 = snapshot.getString(0);
String value2 = snapshot.getString(1);
diskLruCache.close();
}
三、源码分析
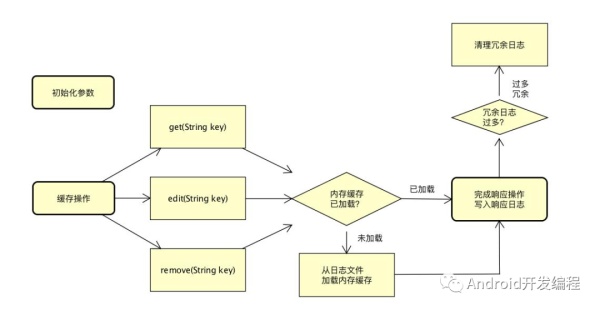
1、open()
DiskLruCache的构造方法是private修饰,这也就是告诉我们,不能通过new DiskLruCache来获取实例,构造方法如下:
private DiskLruCache(File directory, int appVersion, int valueCount, long maxSize) {
this.directory = directory;
this.appVersion = appVersion;
this.journalFile = new File(directory, JOURNAL_FILE);
this.journalFileTmp = new File(directory, JOURNAL_FILE_TEMP);
this.journalFileBackup = new File(directory, JOURNAL_FILE_BACKUP);
this.valueCount = valueCount;
this.maxSize = maxSize;
}
但是提供了open()方法,供我们获取DiskLruCache的实例,open方法如下:
/**
* Opens the cache in {@code directory}, creating a cache if none exists
* there.
*
* @param directory a writable directory
* @param valueCount the number of values per cache entry. Must be positive.
* @param maxSize the maximum number of bytes this cache should use to store
* @throws IOException if reading or writing the cache directory fails
*/
public static DiskLruCache open(File directory, int appVersion, int valueCount, long maxSize)
throws IOException {
if (maxSize <= 0) {
throw new IllegalArgumentException("maxSize <= 0");
}
if (valueCount <= 0) {
throw new IllegalArgumentException("valueCount <= 0");
}
// If a bkp file exists, use it instead.
//看备份文件是否存在
File backupFile = new File(directory, JOURNAL_FILE_BACKUP);
//如果备份文件存在,并且日志文件也存在,就把备份文件删除
//如果备份文件存在,日志文件不存在,就把备份文件重命名为日志文件
if (backupFile.exists()) {
File journalFile = new File(directory, JOURNAL_FILE);
// If journal file also exists just delete backup file.
//
if (journalFile.exists()) {
backupFile.delete();
} else {
renameTo(backupFile, journalFile, false);
}
}
// Prefer to pick up where we left off.
//初始化DiskLruCache,包括,大小,版本,路径,key对应多少value
DiskLruCache cache = new DiskLruCache(directory, appVersion, valueCount, maxSize);
//如果日志文件存在,就开始赌文件信息,并返回
//主要就是构建entry列表
if (cache.journalFile.exists()) {
try {
cache.readJournal();
cache.processJournal();
return cache;
} catch (IOException journalIsCorrupt) {
System.out
.println("DiskLruCache "
+ directory
+ " is corrupt: "
+ journalIsCorrupt.getMessage()
+ ", removing");
cache.delete();
}
}
//不存在就新建一个
// Create a new empty cache.
directory.mkdirs();
cache = new DiskLruCache(directory, appVersion, valueCount, maxSize);
cache.rebuildJournal();
return cache;
}
open函数:如果日志文件存在,直接去构建entry列表;如果不存在,就构建日志文件;
2、rebuildJournal()
构建文件:
//这个就是我们可以直接在disk里面看到的journal文件 主要就是对他的操作
private final File journalFile;
//journal文件的temp 缓存文件,一般都是先构建这个缓存文件,等待构建完成以后将这个缓存文件重新命名为journal
private final File journalFileTmp;
/**
* Creates a new journal that omits redundant information. This replaces the
* current journal if it exists.
*/
private synchronized void rebuildJournal() throws IOException {
if (journalWriter != null) {
journalWriter.close();
}
//指向journalFileTmp这个日志文件的缓存
Writer writer = new BufferedWriter(
new OutputStreamWriter(new FileOutputStream(journalFileTmp), Util.US_ASCII));
try {
writer.write(MAGIC);
writer.write("\n");
writer.write(VERSION_1);
writer.write("\n");
writer.write(Integer.toString(appVersion));
writer.write("\n");
writer.write(Integer.toString(valueCount));
writer.write("\n");
writer.write("\n");
for (Entry entry : lruEntries.values()) {
if (entry.currentEditor != null) {
writer.write(DIRTY + ' ' + entry.key + '\n');
} else {
writer.write(CLEAN + ' ' + entry.key + entry.getLengths() + '\n');
}
}
} finally {
writer.close();
}
if (journalFile.exists()) {
renameTo(journalFile, journalFileBackup, true);
}
//所以这个地方 构建日志文件的流程主要就是先构建出日志文件的缓存文件,如果缓存构建成功 那就直接重命名这个缓存文件,这样做好处在哪里?
renameTo(journalFileTmp, journalFile, false);
journalFileBackup.delete();
//这里也是把写入日志文件的writer初始化
journalWriter = new BufferedWriter(
new OutputStreamWriter(new FileOutputStream(journalFile, true), Util.US_ASCII));
}
再来看当日志文件存在的时候,做了什么
3、readJournal()
private void readJournal() throws IOException {
StrictLineReader reader = new StrictLineReader(new FileInputStream(journalFile), Util.US_ASCII);
try {
//读日志文件的头信息
String magic = reader.readLine();
String version = reader.readLine();
String appVersionString = reader.readLine();
String valueCountString = reader.readLine();
String blank = reader.readLine();
if (!MAGIC.equals(magic)
|| !VERSION_1.equals(version)
|| !Integer.toString(appVersion).equals(appVersionString)
|| !Integer.toString(valueCount).equals(valueCountString)
|| !"".equals(blank)) {
throw new IOException("unexpected journal header: [" + magic + ", " + version + ", "
+ valueCountString + ", " + blank + "]");
}
//这里开始,就开始读取日志信息
int lineCount = 0;
while (true) {
try {
//构建LruEntries entry列表
readJournalLine(reader.readLine());
lineCount++;
} catch (EOFException endOfJournal) {
break;
}
}
redundantOpCount = lineCount - lruEntries.size();
// If we ended on a truncated line, rebuild the journal before appending to it.
if (reader.hasUnterminatedLine()) {
rebuildJournal();
} else {
//初始化写入文件的writer
journalWriter = new BufferedWriter(new OutputStreamWriter(
new FileOutputStream(journalFile, true), Util.US_ASCII));
}
} finally {
Util.closeQuietly(reader);
}
}
然后看下这个函数里面的几个主要变量:
//每个entry对应的缓存文件的格式 一般为1,也就是一个key,对应几个缓存,一般设为1,key-value一一对应的关系
private final int valueCount;
private long size = 0;
//这个是专门用于写入日志文件的writer
private Writer journalWriter;
//这个集合应该不陌生了,
private final LinkedHashMap<String, Entry> lruEntries =
new LinkedHashMap<String, Entry>(0, 0.75f, true);
//这个值大于一定数目时 就会触发对journal文件的清理了
private int redundantOpCount;
下面就看下entry这个实体类的内部结构
private final class Entry {
private final String key;
/**
* Lengths of this entry's files.
* 这个entry中 每个文件的长度,这个数组的长度为valueCount 一般都是1
*/
private final long[] lengths;
/**
* True if this entry has ever been published.
* 曾经被发布过 那他的值就是true
*/
private boolean readable;
/**
* The ongoing edit or null if this entry is not being edited.
* 这个entry对应的editor
*/
private Editor currentEditor;
@Override
public String toString() {
return "Entry{" +
"key='" + key + '\'' +
", lengths=" + Arrays.toString(lengths) +
", readable=" + readable +
", currentEditor=" + currentEditor +
", sequenceNumber=" + sequenceNumber +
'}';
}
/**
* The sequence number of the most recently committed edit to this entry.
* 最近编辑他的序列号
*/
private long sequenceNumber;
private Entry(String key) {
this.key = key;
this.lengths = new long[valueCount];
}
public String getLengths() throws IOException {
StringBuilder result = new StringBuilder();
for (long size : lengths) {
result.append(' ').append(size);
}
return result.toString();
}
/**
* Set lengths using decimal numbers like "10123".
*/
private void setLengths(String[] strings) throws IOException {
if (strings.length != valueCount) {
throw invalidLengths(strings);
}
try {
for (int i = 0; i < strings.length; i++) {
lengths[i] = Long.parseLong(strings[i]);
}
} catch (NumberFormatException e) {
throw invalidLengths(strings);
}
}
private IOException invalidLengths(String[] strings) throws IOException {
throw new IOException("unexpected journal line: " + java.util.Arrays.toString(strings));
}
//臨時文件創建成功了以後 就會重命名為正式文件了
public File getCleanFile(int i) {
Log.v("getCleanFile","getCleanFile path=="+new File(directory, key + "." + i).getAbsolutePath());
return new File(directory, key + "." + i);
}
//tmp开头的都是临时文件
public File getDirtyFile(int i) {
Log.v("getDirtyFile","getDirtyFile path=="+new File(directory, key + "." + i + ".tmp").getAbsolutePath());
return new File(directory, key + "." + i + ".tmp");
}
}
DiskLruCache的open函数的主要流程就基本走完了;
4、get()
/**
* Returns a snapshot of the entry named {@code key}, or null if it doesn't
* exist is not currently readable. If a value is returned, it is moved to
* the head of the LRU queue.
* 通过key获取对应的snapshot
*/
public synchronized Snapshot get(String key) throws IOException {
checkNotClosed();
validateKey(key);
Entry entry = lruEntries.get(key);
if (entry == null) {
return null;
}
if (!entry.readable) {
return null;
}
// Open all streams eagerly to guarantee that we see a single published
// snapshot. If we opened streams lazily then the streams could come
// from different edits.
InputStream[] ins = new InputStream[valueCount];
try {
for (int i = 0; i < valueCount; i++) {
ins[i] = new FileInputStream(entry.getCleanFile(i));
}
} catch (FileNotFoundException e) {
// A file must have been deleted manually!
for (int i = 0; i < valueCount; i++) {
if (ins[i] != null) {
Util.closeQuietly(ins[i]);
} else {
break;
}
}
return null;
}
redundantOpCount++;
//在取得需要的文件以后 记得在日志文件里增加一条记录 并检查是否需要重新构建日志文件
journalWriter.append(READ + ' ' + key + '\n');
if (journalRebuildRequired()) {
executorService.submit(cleanupCallable);
}
return new Snapshot(key, entry.sequenceNumber, ins, entry.lengths);
}
5、validateKey
private void validateKey(String key) {
Matcher matcher = LEGAL_KEY_PATTERN.matcher(key);
if (!matcher.matches()) {
throw new IllegalArgumentException("keys must match regex "
+ STRING_KEY_PATTERN + ": \"" + key + "\"");
}
}
这里是对存储entry的map的key做了正则验证,所以key一定要用md5加密,因为有些特殊字符验证不能通过;
然后看这句代码对应的:
if (journalRebuildRequired()) {
executorService.submit(cleanupCallable);
}
对应的回调函数是:
/** This cache uses a single background thread to evict entries. */
final ThreadPoolExecutor executorService =
new ThreadPoolExecutor(0, 1, 60L, TimeUnit.SECONDS, new LinkedBlockingQueue<Runnable>());
private final Callable<Void> cleanupCallable = new Callable<Void>() {
public Void call() throws Exception {
synchronized (DiskLruCache.this) {
if (journalWriter == null) {
return null; // Closed.
}
trimToSize();
if (journalRebuildRequired()) {
rebuildJournal();
redundantOpCount = 0;
}
}
return null;
}
};
其中再来看看trimTOSize()的状态
6、trimTOSize()
private void trimToSize() throws IOException {
while (size > maxSize) {
Map.Entry<String, Entry> toEvict = lruEntries.entrySet().iterator().next();
remove(toEvict.getKey());
}
}
就是检测总缓存是否超过了限制数量,
再来看journalRebuildRequired函数
7、journalRebuildRequired()
/**
* We only rebuild the journal when it will halve the size of the journal
* and eliminate at least 2000 ops.
*/
private boolean journalRebuildRequired() {
final int redundantOpCompactThreshold = 2000;
return redundantOpCount >= redundantOpCompactThreshold //
&& redundantOpCount >= lruEntries.size();
}
就是校验redundantOpCount是否超出了范围,如果是,就重构日志文件;
最后看get函数的返回值 new Snapshot()
/** A snapshot of the values for an entry. */
//这个类持有该entry中每个文件的inputStream 通过这个inputStream 可以读取他的内容
public final class Snapshot implements Closeable {
private final String key;
private final long sequenceNumber;
private final InputStream[] ins;
private final long[] lengths;
private Snapshot(String key, long sequenceNumber, InputStream[] ins, long[] lengths) {
this.key = key;
this.sequenceNumber = sequenceNumber;
this.ins = ins;
this.lengths = lengths;
}
/**
* Returns an editor for this snapshot's entry, or null if either the
* entry has changed since this snapshot was created or if another edit
* is in progress.
*/
public Editor edit() throws IOException {
return DiskLruCache.this.edit(key, sequenceNumber);
}
/** Returns the unbuffered stream with the value for {@code index}. */
public InputStream getInputStream(int index) {
return ins[index];
}
/** Returns the string value for {@code index}. */
public String getString(int index) throws IOException {
return inputStreamToString(getInputStream(index));
}
/** Returns the byte length of the value for {@code index}. */
public long getLength(int index) {
return lengths[index];
}
public void close() {
for (InputStream in : ins) {
Util.closeQuietly(in);
}
}
}
到这里就明白了get最终返回的其实就是entry根据key 来取的snapshot对象,这个对象直接把inputStream暴露给外面;
8、save的过程
public Editor edit(String key) throws IOException {
return edit(key, ANY_SEQUENCE_NUMBER);
}
//根据传进去的key 创建一个entry 并且将这个key加入到entry的那个map里 然后创建一个对应的editor
//同时在日志文件里加入一条对该key的dirty记录
private synchronized Editor edit(String key, long expectedSequenceNumber) throws IOException {
//因为这里涉及到写文件 所以要先校验一下写日志文件的writer 是否被正确的初始化
checkNotClosed();
//这个地方是校验 我们的key的,通常来说 假设我们要用这个缓存来存一张图片的话,我们的key 通常是用这个图片的
//网络地址 进行md5加密,而对这个key的格式在这里是有要求的 所以这一步就是验证key是否符合规范
validateKey(key);
Entry entry = lruEntries.get(key);
if (expectedSequenceNumber != ANY_SEQUENCE_NUMBER && (entry == null
|| entry.sequenceNumber != expectedSequenceNumber)) {
return null; // Snapshot is stale.
}
if (entry == null) {
entry = new Entry(key);
lruEntries.put(key, entry);
} else if (entry.currentEditor != null) {
return null; // Another edit is in progress.
}
Editor editor = new Editor(entry);
entry.currentEditor = editor;
// Flush the journal before creating files to prevent file leaks.
journalWriter.write(DIRTY + ' ' + key + '\n');
journalWriter.flush();
return editor;
}
然后取得输出流
public OutputStream newOutputStream(int index) throws IOException {
if (index < 0 || index >= valueCount) {
throw new IllegalArgumentException("Expected index " + index + " to "
+ "be greater than 0 and less than the maximum value count "
+ "of " + valueCount);
}
synchronized (DiskLruCache.this) {
if (entry.currentEditor != this) {
throw new IllegalStateException();
}
if (!entry.readable) {
written[index] = true;
}
File dirtyFile = entry.getDirtyFile(index);
FileOutputStream outputStream;
try {
outputStream = new FileOutputStream(dirtyFile);
} catch (FileNotFoundException e) {
// Attempt to recreate the cache directory.
directory.mkdirs();
try {
outputStream = new FileOutputStream(dirtyFile);
} catch (FileNotFoundException e2) {
// We are unable to recover. Silently eat the writes.
return NULL_OUTPUT_STREAM;
}
}
return new FaultHidingOutputStream(outputStream);
}
}
注意这个index 其实一般传0 就可以了,DiskLruCache 认为 一个key 下面可以对应多个文件,这些文件 用一个数组来存储,所以正常情况下,我们都是
一个key 对应一个缓存文件 所以传0
//tmp开头的都是临时文件
public File getDirtyFile(int i) {
return new File(directory, key + "." + i + ".tmp");
}
然后你这边就能看到,这个输出流,实际上是tmp 也就是缓存文件的 .tmp 也就是缓存文件的 缓存文件 输出流;
这个流 我们写完毕以后 就要commit;
public void commit() throws IOException {
if (hasErrors) {
completeEdit(this, false);
remove(entry.key); // The previous entry is stale.
} else {
completeEdit(this, true);
}
committed = true;
}
这个就是根据缓存文件的大小 更新disklrucache的总大小 然后再日志文件里对该key加入clean的log
//最后判断是否超过最大的maxSize 以便对缓存进行清理
private synchronized void completeEdit(Editor editor, boolean success) throws IOException {
Entry entry = editor.entry;
if (entry.currentEditor != editor) {
throw new IllegalStateException();
}
// If this edit is creating the entry for the first time, every index must have a value.
if (success && !entry.readable) {
for (int i = 0; i < valueCount; i++) {
if (!editor.written[i]) {
editor.abort();
throw new IllegalStateException("Newly created entry didn't create value for index " + i);
}
if (!entry.getDirtyFile(i).exists()) {
editor.abort();
return;
}
}
}
for (int i = 0; i < valueCount; i++) {
File dirty = entry.getDirtyFile(i);
if (success) {
if (dirty.exists()) {
File clean = entry.getCleanFile(i);
dirty.renameTo(clean);
long oldLength = entry.lengths[i];
long newLength = clean.length();
entry.lengths[i] = newLength;
size = size - oldLength + newLength;
}
} else {
deleteIfExists(dirty);
}
}
redundantOpCount++;
entry.currentEditor = null;
if (entry.readable | success) {
entry.readable = true;
journalWriter.write(CLEAN + ' ' + entry.key + entry.getLengths() + '\n');
if (success) {
entry.sequenceNumber = nextSequenceNumber++;
}
} else {
lruEntries.remove(entry.key);
journalWriter.write(REMOVE + ' ' + entry.key + '\n');
}
journalWriter.flush();
if (size > maxSize || journalRebuildRequired()) {
executorService.submit(cleanupCallable);
}
}
commit以后 就会把tmp文件转正 ,重命名为 真正的缓存文件了;
这个里面的流程和日志文件的rebuild 是差不多的,都是为了防止写文件的出问题。所以做了这样的冗余处理;
总结:
DiskLruCache,利用一个journal文件,保证了保证了cache实体的可用性(只有CLEAN的可用),且获取文件的长度的时候可以通过在该文件的记录中读取。
利用FaultHidingOutputStream对FileOutPutStream很好的对写入文件过程中是否发生错误进行捕获,而不是让用户手动去调用出错后的处理方法;
到此这篇关于关于Android DiskLruCache的磁盘缓存机制原理的文章就介绍到这了,更多相关Android DiskLruCache磁盘缓存机制原理内容请搜索海外IDC网以前的文章或继续浏览下面的相关文章希望大家以后多多支持海外IDC网!
【本文由:http://www.1234xp.com/cdn.html 提供,感谢支持】