
如何利用python多线程爬取天气网站图片并保存
目录
- 1.1 题目
- 1.2 思路
- 1.2.1 发送请求
- 1.2.2 解析网页
- 1.2.3 获取结点
- 1.2.4 数据保存 (单线程)
- 1.2.4 数据保存 (多线程)
- 总结
1.1 题目
指定一个网站,爬取这个网站中的所有的所有图片,例如中国气象网(www.weather.com.cn),分别使用单线程和多线程的方式爬取。(限定爬取图片数量为学号后3位)
输出信息: 将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
1.2 思路
1.2.1 发送请求
构造请求头
import requests,re
import urllib
headers = {
'Connection': 'keep-alive',
'Cache-Control': 'max-age=0',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.61 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Language': 'zh-CN,zh;q=0.9',
}
url = "http://www.weather.com.cn/"
request = urllib.request.Request(url, headers=headers)
发送请求
request = urllib.request.Request(url, headers=headers) r = urllib.request.urlopen(request)
1.2.2 解析网页
页面解析,并且替换回车,方便后续进行正则匹配图片。
html = r.read().decode().replace('\n','')

1.2.3 获取结点
使用正则匹配,先获取所有的a标签,然后爬取a标签下面的所有图片
urlList = re.findall('<a href="(.*?)" ',html,re.S)
获取所有的图片
allImageList = []
for k in urlList:
try:
request = urllib.request.Request(k, headers=headers)
r = urllib.request.urlopen(request)
html = r.read().decode().replace('\n','')
imgList = re.findall(r'<img.*?src="(.*?)"', html, re.S)
allImageList+=imgList
except Exception as e:
pass
这里的请求其实也是要用多线程爬取的,所有后续会补上!
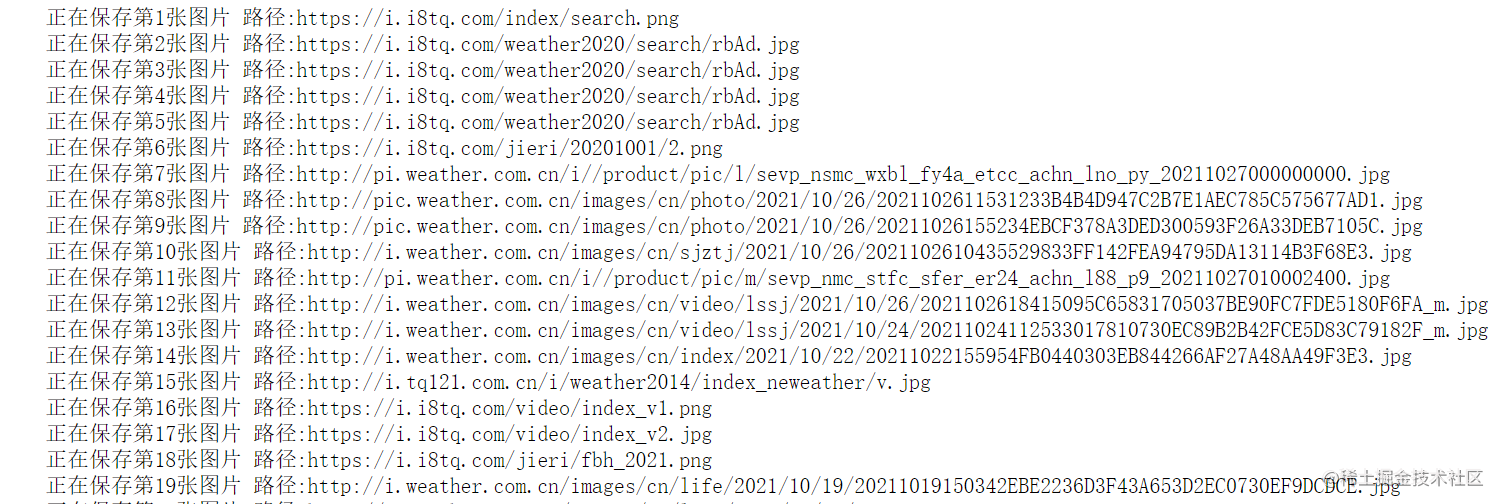
1.2.4 数据保存 (单线程)
for i, img in enumerate(allImageList[:102]):
print(f"正在保存第{i + 1}张图片 路径:{img}")
resp = requests.get(img)
with open(f'./image/{img.split("/")[-1]}', 'wb') as f: # 保存到这个image路径下
f.write(resp.content)
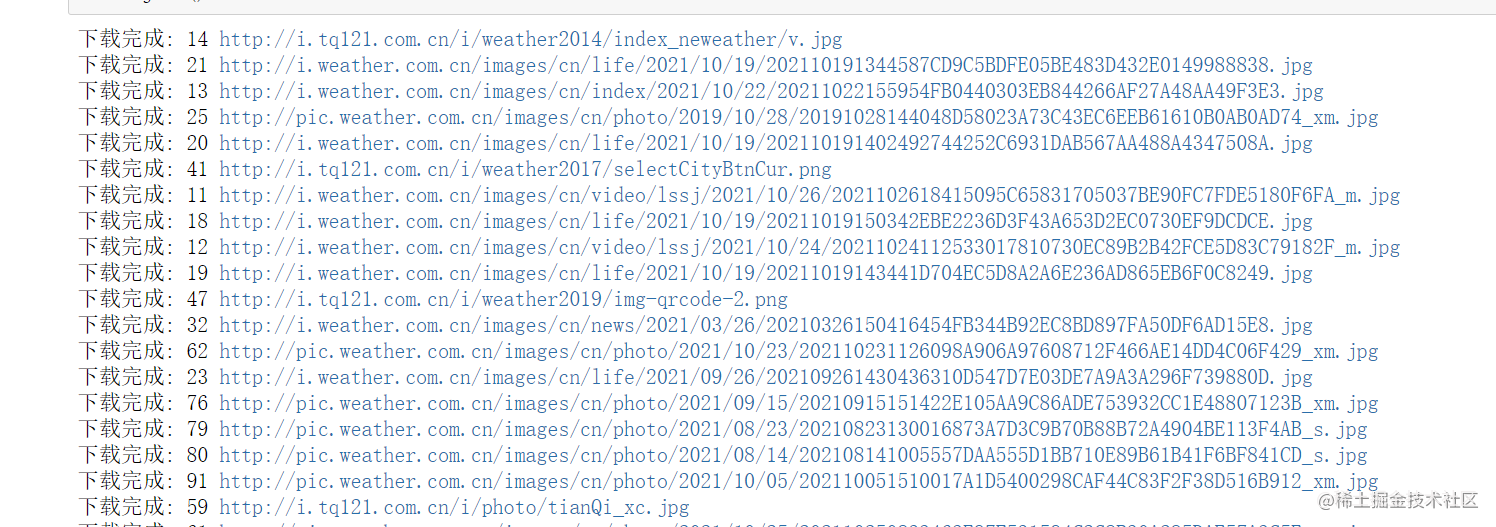
1.2.4 数据保存 (多线程)
引入多进程模块
import threading
# 多线程
def download_imgs(imgList,limit):
threads = []
T = [
threading.Thread(target = download, args=(url,i))
for i, url in enumerate(imgList[:limit + 1])
]
for t in T:
t.start()
threads.append(t)
return threads
编写下载函数
def download(img_url,name):
resp = requests.get(img_url)
try:
resp = requests.get(img_url)
with open(f'./images/{name}.jpg', 'wb') as f:
f.write(resp.content)
except Exception as e:
print(f"下载失败: {name} {img_url} -> {e}")
else:
print(f"下载完成: {name} {img_url}")
就很随机
总结
到此这篇关于如何利用python多线程爬取天气网站图片并保存的文章就介绍到这了,更多相关python爬取天气网站图片内容请搜索hwidc以前的文章或继续浏览下面的相关文章希望大家以后多多支持hwidc!
【文章转自:http://www.1234xp.com/xjp.html 复制请保留原URL】