
python基础之贪婪模式与非贪婪模式
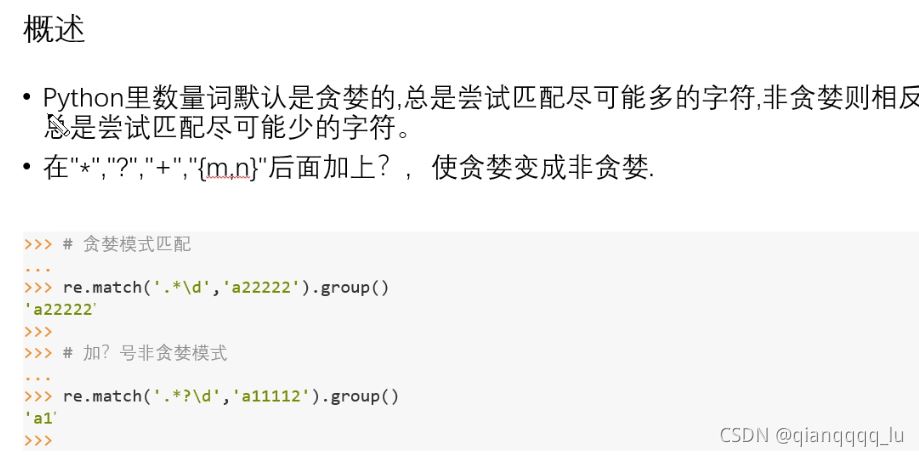
# 贪婪模式 默认的匹配规则
# 在满足条件的情况下 尽可能多的去匹配到字符串
import re
rs = re.match('\d{6,9}', '111222333')
print(rs.group())
# 非贪婪模式 在满足条件的情况下尽可能少的去匹配
rs = re.match('\d{6,9}?', '111222333')
print(rs.group())
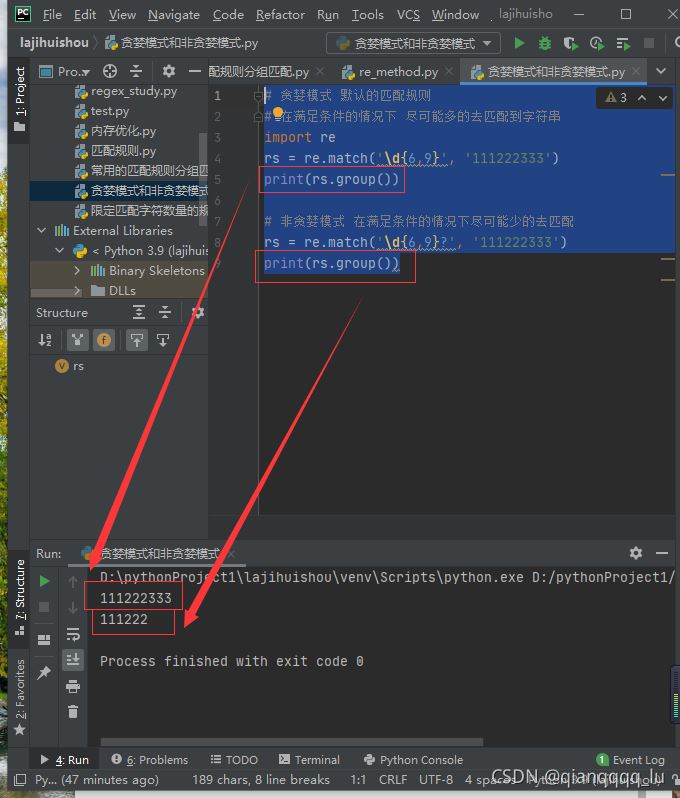
import re
content='aacbacbc'
pattren=re.compile('a.*b')
result=pattren.search(content)
print(result.group())
content='aacbacbc'
pattren=re.compile('a.*?b') #非贪婪模式匹配
result=pattren.search(content)
print(result.group())
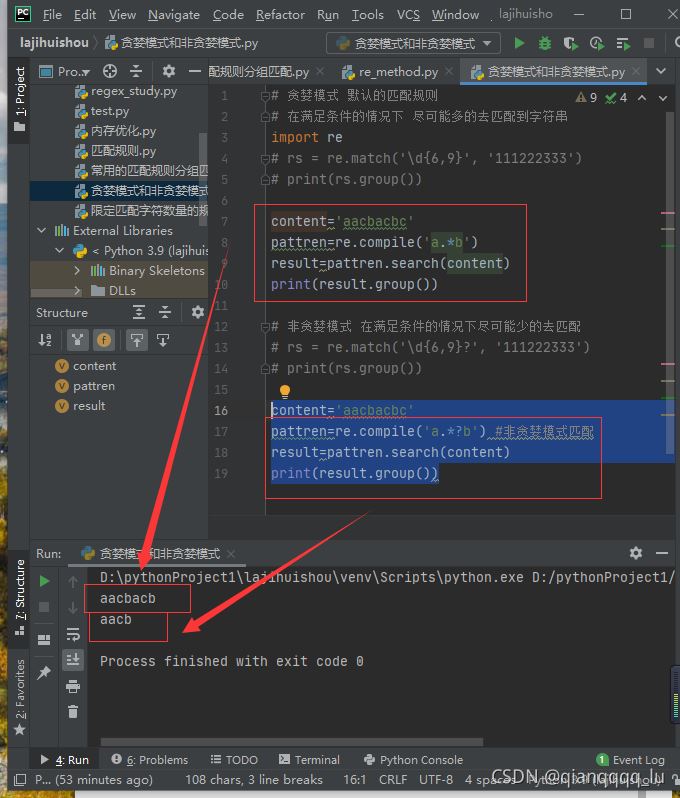






课后作业
import re
# 1.'save your heart for someone who cares' 请使用正则将文本中的
# “s” 替换成S 请写python代码完成匹配替换
data='save your heart for someone who cares'
res=re.sub('s','S',data)
print(res)
# 2.'<span>三生三世,十里桃花
# </span><span>莫斯科行动</span><span>九州海上牧云记</span>'
# 请使用正则将<span>标签中的全部内容匹配出来 用python代码实现
data='<span>三生三世,十里桃花</span>' \
'<span>莫斯科行动</span><span>' \
'九州海上牧云记</span>'
res=re.compile(r'<span>(.*)</span><span>(.*)</span><span>(.*)</span>')
result=res.findall(data)
print(result)
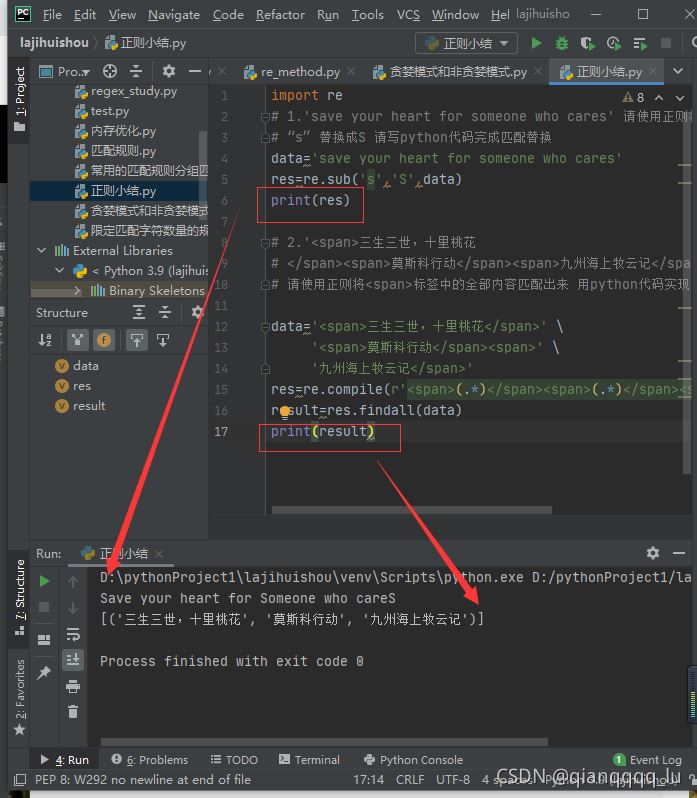
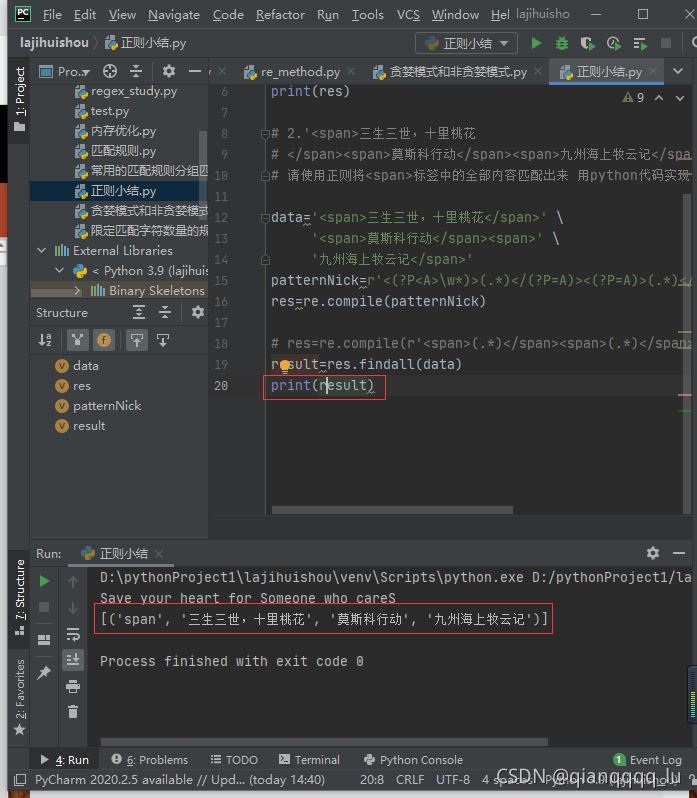
# 2.'<span>三生三世,十里桃花
# </span><span>莫斯科行动</span><span>九州海上牧云记</span>'
# 请使用正则将<span>标签中的全部内容匹配出来 用python代码实现
data='<span>三生三世,十里桃花</span>' \
'<span>莫斯科行动</span><span>' \
'九州海上牧云记</span>'
patternNick=r'<(?P<A>\w*)>(.*)</(?P=A)><(?P=A)>(.*)</(?P=A)><(?P=A)>(.*)</(?P=A)>'
res=re.compile(patternNick)
# res=re.compile(r'<span>(.*)</span><span>(.*)</span><span>(.*)</span>')
result=res.findall(data)
print(result)
总结
本篇文章就到这里了,希望能够给你带来帮助,也希望您能够多多关注hwidc的更多内容!
【本文由http://www.1234xp.com/xgzq.html首发,转载请保留出处,谢谢】