
关于spring5的那些事:@Indexed 解密
目录
- 哪些资源会被索引?
- 如何使用?
- 原理
随着云原生的发展,很多技术会被重新掂量,重新定义,历来技术的发展也是遵循天时地利,以其势尽享其利。再云原生下,jdk的最大的问题在于笨重(几百mb),启动慢,而像Serverless架构,NodeJS技术栈可谓更完美。
其实在jdk9中倡导模块化本质在于减少JVM的体积,不需要资源(Jar)不用再加载,而启动慢的问题其实也有解决方案GraalVM (一款类似于HotSpot VM),它的先进之处在于缩短运行的成本将.java文件直接编译成native code,而jvm则多了一个环节,首先将.java文件编译成字节码(.class),再借助JVM运行时JIT技术编译成native code。
spring5.0开始支持@Indexed来提升进应用启动速度,通过Annotation Processing Tools API在编译时来构建索引文件,本质是通过静态化来解决启动时Bean扫描加载的时间长的问题。
what is Annotation Processing Tools API?
不是什么黑科技,之前的系列也讲过,有点类似lombok。
哪些资源会被索引?
默认支持标记为Component及其派生注解(Controller、Repository、Service、Configuration等)的类,当然也可以是非spring bean(@Indexed修饰的类)。
注:如果已经是spring bean(Component修饰的类,并且Component已经被标记为@Indexed)了就没必要再标记@Indexed,否则索引文件会再追加一个相同的,感觉这是个bug
如何使用?
使用非常讲的,添加依赖就可以了,install后默认会生成一个META-INF/spring.components。
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context-indexer</artifactId>
<optional>true</optional>
</dependency>
#spring.components com.yh.rfe.lucky.day.service.impl.BasCostReportServiceImpl=org.springframework.stereotype.Component com.yh.rfe.lucky.day.service.impl.BasShopRuleDetailServiceImpl=org.springframework.stereotype.Component
而CandidateComponentsIndexer负责对符合条件的注解生成索引文件,整个源码也不是特别复杂,通过三个组件:StereotypesProvider、MetadataCollector、MetadataStore来完成。
public class CandidateComponentsIndexer implements Processor {
@Override
public synchronized void init(ProcessingEnvironment env) {
this.stereotypesProviders = getStereotypesProviders(env);
this.typeHelper = new TypeHelper(env);
this.metadataStore = new MetadataStore(env);
this.metadataCollector = new MetadataCollector(env, this.metadataStore.readMetadata());
}
@Override
public boolean process(Set<? extends TypeElement> annotations, RoundEnvironment roundEnv) {
this.metadataCollector.processing(roundEnv);
roundEnv.getRootElements().forEach(this::processElement);
if (roundEnv.processingOver()) {
writeMetaData();
}
return false;
}
}
//定义了哪些注解需要被索引
interface StereotypesProvider {
/**
* Return the stereotypes that are present on the given {@link Element}.
* @param element the element to handle
* @return the stereotypes or an empty set if none were found
*/
Set<String> getStereotypes(Element element);
}
//获取需要被索引的CandidateComponentsMetadata(元数据)
class MetadataCollector {
public CandidateComponentsMetadata getMetadata() {
CandidateComponentsMetadata metadata = new CandidateComponentsMetadata();
for (ItemMetadata item : this.metadataItems) {
metadata.add(item);
}
if (this.previousMetadata != null) {
List<ItemMetadata> items = this.previousMetadata.getItems();
for (ItemMetadata item : items) {
if (shouldBeMerged(item)) {
metadata.add(item);
}
}
}
return metadata;
}
}
//将上面的结果输出到spring.components中
class MetadataStore {
static final String METADATA_PATH = "META-INF/spring.components";
public void writeMetadata(CandidateComponentsMetadata metadata) throws IOException {
if (!metadata.getItems().isEmpty()) {
try (OutputStream outputStream = createMetadataResource().openOutputStream()) {
PropertiesMarshaller.write(metadata, outputStream);
}
}
}
}
原理
其实在spring boot项目中绝对存在ComponentScan(在SpringBootApplication中),而传统的spring项目中xml中对应<context:component-scan>,通过指定的 package(路径)来扫描注入spring bean,在扫描时通过读取spring.components文件来读取class(类全路径)从而达到提升速度的目的。
CandidateComponentsIndex存储了spring.components文件的内容
public class CandidateComponentsIndex {
private static final AntPathMatcher pathMatcher = new AntPathMatcher(".");
private final MultiValueMap<String, Entry> index;
/*返回指定的注解类型和包路径相关候选类型
* Set<String> candidates = index.getCandidateTypes("com.example", "org.springframework.stereotype.Component");
*/
public Set<String> getCandidateTypes(String basePackage, String stereotype) {
List<Entry> candidates = this.index.get(stereotype);
if (candidates != null) {
return candidates.parallelStream()
.filter(t -> t.match(basePackage))
.map(t -> t.type)
.collect(Collectors.toSet());
}
return Collections.emptySet();
}
}
CandidateComponentsIndexLoader从classloader中读取,可以从多个jar中读取多个索引文件。
public final class CandidateComponentsIndexLoader {
public static final String COMPONENTS_RESOURCE_LOCATION = "META-INF/spring.components";
private static final ConcurrentMap<ClassLoader, CandidateComponentsIndex> cache =
new ConcurrentReferenceHashMap<>();
@Nullable
public static CandidateComponentsIndex loadIndex(@Nullable ClassLoader classLoader) {
ClassLoader classLoaderToUse = classLoader;
if (classLoaderToUse == null) {
classLoaderToUse = CandidateComponentsIndexLoader.class.getClassLoader();
}
return cache.computeIfAbsent(classLoaderToUse, CandidateComponentsIndexLoader::doLoadIndex);
}
@Nullable
private static CandidateComponentsIndex doLoadIndex(ClassLoader classLoader) {
if (shouldIgnoreIndex) {
return null;
}
try {
Enumeration<URL> urls = classLoader.getResources(COMPONENTS_RESOURCE_LOCATION);
if (!urls.hasMoreElements()) {
return null;
}
List<Properties> result = new ArrayList<>();
while (urls.hasMoreElements()) {
URL url = urls.nextElement();
Properties properties = PropertiesLoaderUtils.loadProperties(new UrlResource(url));
result.add(properties);
}
if (logger.isDebugEnabled()) {
logger.debug("Loaded " + result.size() + "] index(es)");
}
int totalCount = result.stream().mapToInt(Properties::size).sum();
return (totalCount > 0 ? new CandidateComponentsIndex(result) : null);
}
catch (IOException ex) {
throw new IllegalStateException("Unable to load indexes from location [" +
COMPONENTS_RESOURCE_LOCATION + "]", ex);
}
}
}
ClassPathBeanDefinitionScanner非常重要,它就是spring 中scan时干最脏最累的活的终结者。而ClassPathScanningCandidateComponentProvider非常重要可以视为scan的顶级实现类。
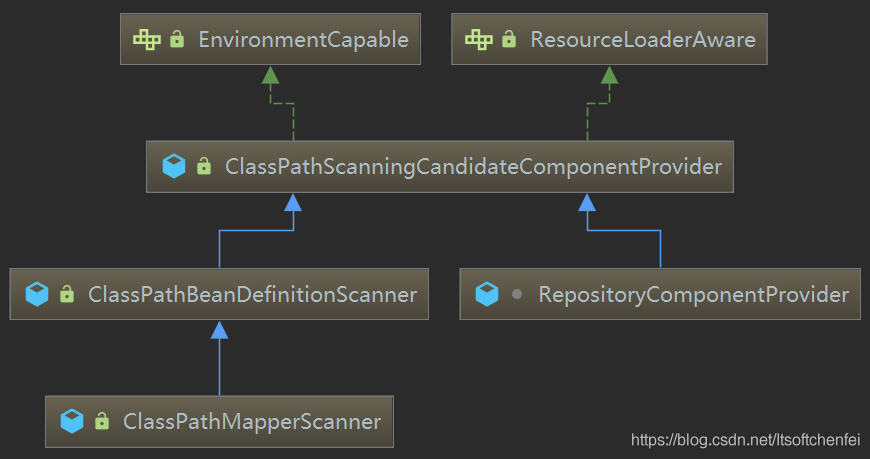
其中ClassPathMapperScanner是mybatis的mapper扫描类。
public class ClassPathBeanDefinitionScanner extends ClassPathScanningCandidateComponentProvider {
public int scan(String... basePackages) {
int beanCountAtScanStart = this.registry.getBeanDefinitionCount();
doScan(basePackages);
// Register annotation config processors, if necessary.
if (this.includeAnnotationConfig) {
AnnotationConfigUtils.registerAnnotationConfigProcessors(this.registry);
}
return (this.registry.getBeanDefinitionCount() - beanCountAtScanStart);
}
protected Set<BeanDefinitionHolder> doScan(String... basePackages) {
Assert.notEmpty(basePackages, "At least one base package must be specified");
Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet<>();
for (String basePackage : basePackages) {
Set<BeanDefinition> candidates = findCandidateComponents(basePackage);//看这里吧
for (BeanDefinition candidate : candidates) {
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);
candidate.setScope(scopeMetadata.getScopeName());
String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);
if (candidate instanceof AbstractBeanDefinition) {
postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);
}
if (candidate instanceof AnnotatedBeanDefinition) {
AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);
}
if (checkCandidate(beanName, candidate)) {
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
definitionHolder =
AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
beanDefinitions.add(definitionHolder);
registerBeanDefinition(definitionHolder, this.registry);
}
}
}
return beanDefinitions;
}
}
public class ClassPathScanningCandidateComponentProvider implements EnvironmentCapable, ResourceLoaderAware {
private MetadataReaderFactory metadataReaderFactory;//这个之前讲过类元数据读取
private CandidateComponentsIndex componentsIndex;//前面讲过
public Set<BeanDefinition> findCandidateComponents(String basePackage) {
if (this.componentsIndex != null && indexSupportsIncludeFilters()) {
return addCandidateComponentsFromIndex(this.componentsIndex, basePackage);
}
else {
return scanCandidateComponents(basePackage);
}
}
private Set<BeanDefinition> addCandidateComponentsFromIndex(CandidateComponentsIndex index, String basePackage) {
Set<BeanDefinition> candidates = new LinkedHashSet<>();
try {
Set<String> types = new HashSet<>();
for (TypeFilter filter : this.includeFilters) {
String stereotype = extractStereotype(filter);
if (stereotype == null) {
throw new IllegalArgumentException("Failed to extract stereotype from "+ filter);
}
types.addAll(index.getCandidateTypes(basePackage, stereotype));
}
boolean traceEnabled = logger.isTraceEnabled();
boolean debugEnabled = logger.isDebugEnabled();
for (String type : types) {
MetadataReader metadataReader = getMetadataReaderFactory().getMetadataReader(type);
if (isCandidateComponent(metadataReader)) {
AnnotatedGenericBeanDefinition sbd = new AnnotatedGenericBeanDefinition(
metadataReader.getAnnotationMetadata());
if (isCandidateComponent(sbd)) {
if (debugEnabled) {
logger.debug("Using candidate component class from index: " + type);
}
candidates.add(sbd);
}
else {
if (debugEnabled) {
logger.debug("Ignored because not a concrete top-level class: " + type);
}
}
}
else {
if (traceEnabled) {
logger.trace("Ignored because matching an exclude filter: " + type);
}
}
}
}
catch (IOException ex) {
throw new BeanDefinitionStoreException("I/O failure during classpath scanning", ex);
}
return candidates;
}
}
AnnotationConfigApplicationContext#scan你一定不陌生吧,这可是开发用户级的API,其实它的scanner就是ClassPathBeanDefinitionScanner
public class AnnotationConfigApplicationContext extends GenericApplicationContext implements AnnotationConfigRegistry {
private final AnnotatedBeanDefinitionReader reader;
private final ClassPathBeanDefinitionScanner scanner;
public AnnotationConfigApplicationContext() {
this.reader = new AnnotatedBeanDefinitionReader(this);
this.scanner = new ClassPathBeanDefinitionScanner(this);
}
public AnnotationConfigApplicationContext(String... basePackages) {
this();
scan(basePackages);
refresh();
}
public void register(Class<?>... annotatedClasses) {
Assert.notEmpty(annotatedClasses, "At least one annotated class must be specified");
this.reader.register(annotatedClasses);
}
}
其实关于@Indexed个人觉得实现上还是有一定局限性(只是针对当前maven的一个module,换言之是基于jar的),要基于当前整个工程文件特别是org.springframework包(这个下面有很多待加载到ioc的bean的jar)工作量还是不少的,官方还没考虑吧。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持自由互联。
【来源:美国cn2服务器 转载请说明出处】