
Python实战快速上手BeautifulSoup库爬取专栏标题和地
目录
- 安装
- 解析标签
- 解析属性
- 根据class值解析
- 根据ID解析
- 多层筛选
- 提取a标签中的网址
- 实战-获取博客专栏 标题+网址
BeautifulSoup库快速上手
安装
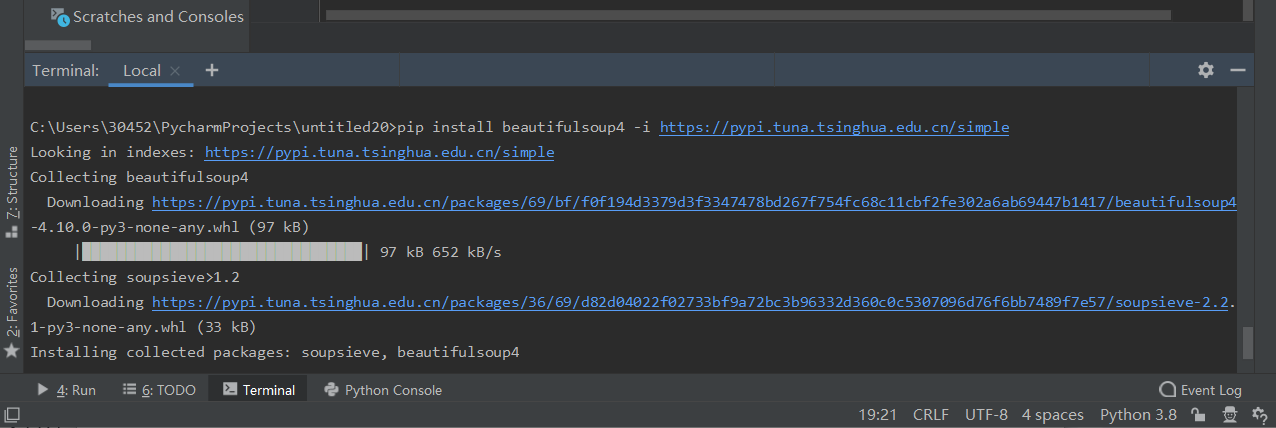
pip install beautifulsoup4 # 上面的安装失败使用下面的 使用镜像 pip install beautifulsoup4 -i https://pypi.tuna.tsinghua.edu.cn/simple
使用PyCharm的命令行
解析标签
from bs4 import BeautifulSoup
import requests
url='https://blog.csdn.net/weixin_42403632/category_11076268.html'
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:93.0) Gecko/20100101 Firefox/93.0'}
html=requests.get(url,headers=headers).text
s=BeautifulSoup(html,'html.parser')
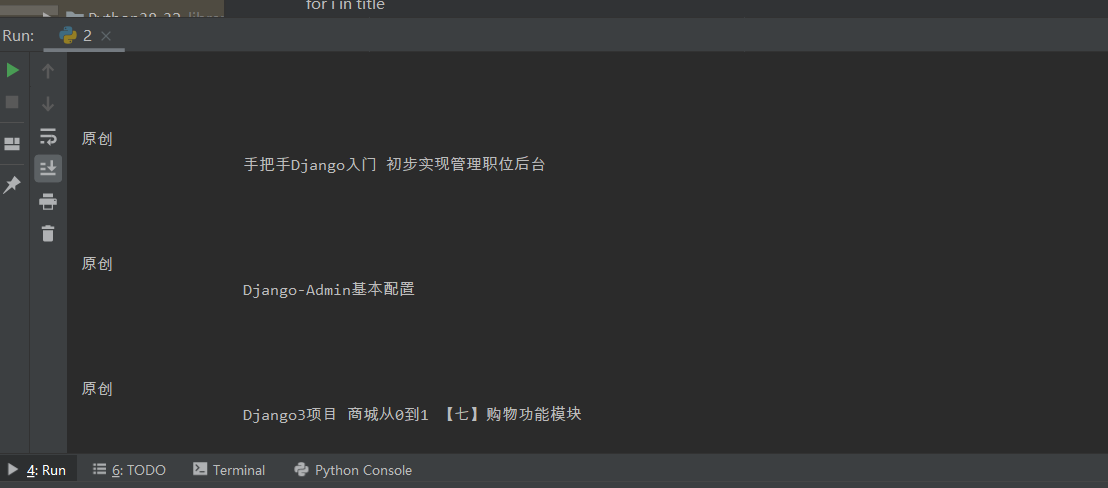
title =s.select('h2')
for i in title:
print(i.text)
第一行代码:导入BeautifulSoup库
第二行代码:导入requests
第三、四、五行代码:获取url的html
第六行代码:激活BeautifulSoup库 'html.parser'设置解析器为HTML解析器
第七行代码:选取所有<h2>标签
解析属性
BeautifulSoup库 支持根据特定属性解析网页元素
根据class值解析
from bs4 import BeautifulSoup
import requests
url='https://blog.csdn.net/weixin_42403632/category_11076268.html'
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:93.0) Gecko/20100101 Firefox/93.0'}
html=requests.get(url,headers=headers).text
s=BeautifulSoup(html,'html.parser')
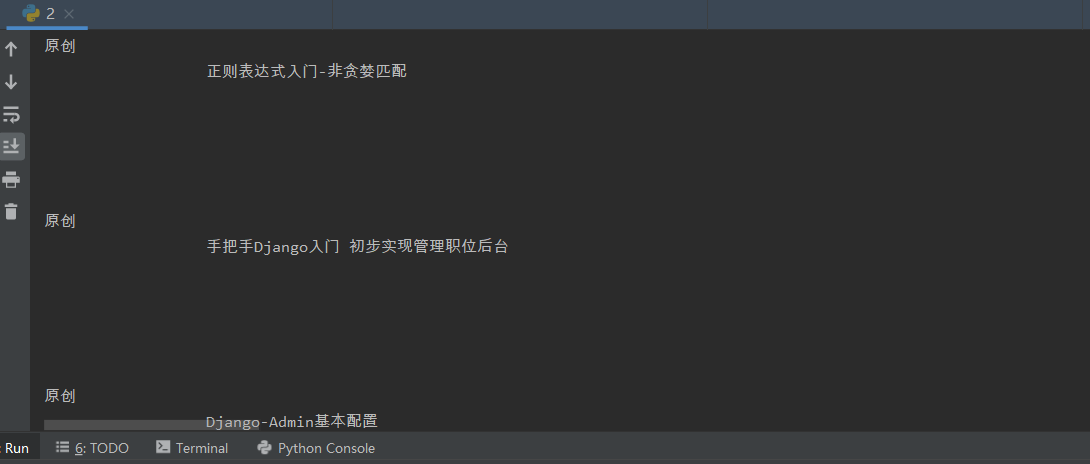
title =s.select('.column_article_title')
for i in title:
print(i.text)
根据ID解析
from bs4 import BeautifulSoup
html='''<div class="crop-img-before">
<img src="" alt="" id="cropImg">
</div>
<div id='title'>
测试成功
</div>
<div class="crop-zoom">
<a href="javascript:;" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" class="bt-reduce">-</a><a href="javascript:;" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" class="bt-add">+</a>
</div>
<div class="crop-img-after">
<div class="final-img"></div>
</div>'''
s=BeautifulSoup(html,'html.parser')
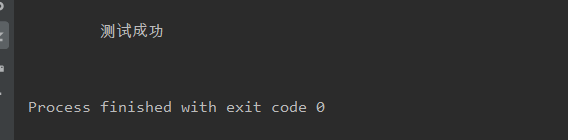
title =s.select('#title')
for i in title:
print(i.text)
多层筛选
from bs4 import BeautifulSoup
html='''<div class="crop-img-before">
<img src="" alt="" id="cropImg">
</div>
<div id='title'>
456456465
<h1>测试成功</h1>
</div>
<div class="crop-zoom">
<a href="javascript:;" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" class="bt-reduce">-</a><a href="javascript:;" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" class="bt-add">+</a>
</div>
<div class="crop-img-after">
<div class="final-img"></div>
</div>'''
s=BeautifulSoup(html,'html.parser')
title =s.select('#title')
for i in title:
print(i.text)
title =s.select('#title h1')
for i in title:
print(i.text)
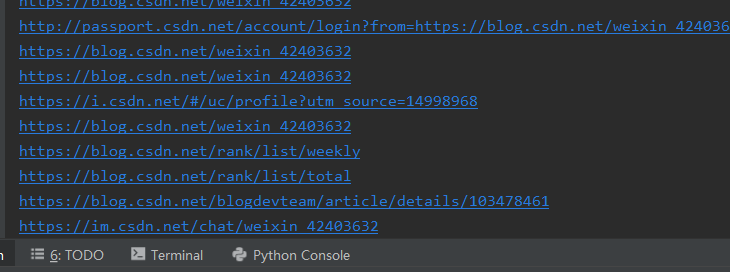
提取a标签中的网址
title =s.select('a')
for i in title:
print(i['href'])
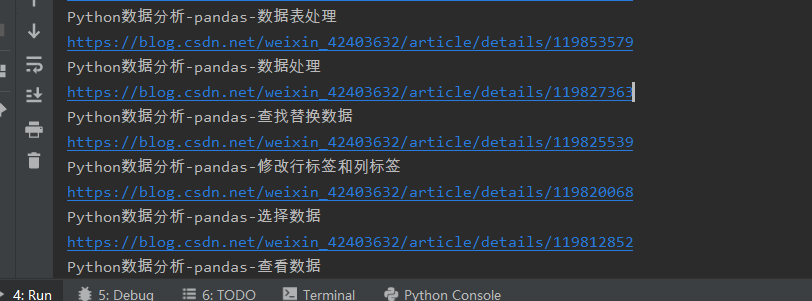
实战-获取博客专栏 标题+网址
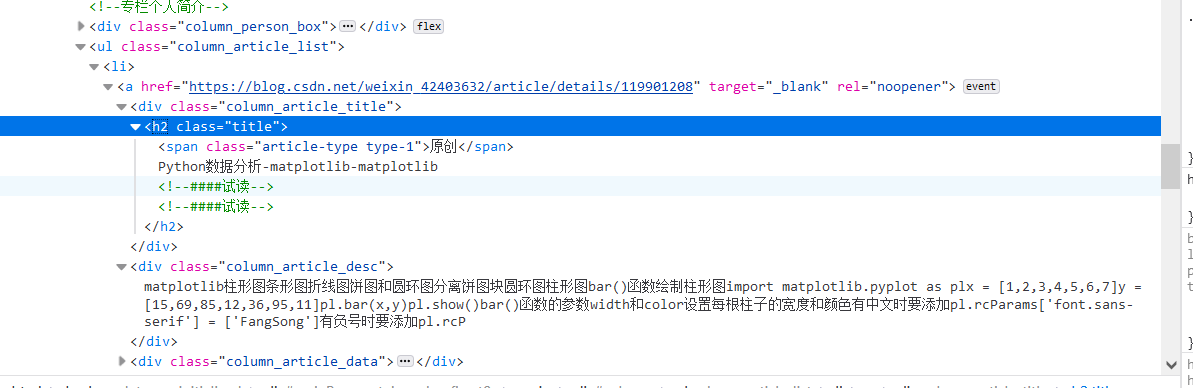
from bs4 import BeautifulSoup
import requests
import re
url='https://blog.csdn.net/weixin_42403632/category_11298953.html'
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:93.0) Gecko/20100101 Firefox/93.0'}
html=requests.get(url,headers=headers).text
s=BeautifulSoup(html,'html.parser')
title =s.select('.column_article_list li a')
for i in title:
print((re.findall('原创.*?\n(.*?)\n',i.text))[0].lstrip())
print(i['href'])
到此这篇关于Python实战快速上手BeautifulSoup库爬取专栏标题和地址的文章就介绍到这了,更多相关Python BeautifulSoup库内容请搜索hwidc以前的文章或继续浏览下面的相关文章希望大家以后多多支持hwidc!
【原URL http://www.yidunidc.com/mggfzq.html 请说明出处】