
Python安装spark的详细过程
目录
- 一.配置版本
- 二.配置环境
- 1.配置JDK
- 2.配置Spark
- 3.配置Hadoop
- 三.Pycharm配置spark
- 四.使用anconda中python环境配置spark
- 1.创建虚拟环境
- 2.安装pyspark
- 3.环境配置
- 4.运行
一.配置版本
Java JDK 1.8.0_111
Python 3.9.6
Spark 3.1.2
Hadoop 3.2.2
二.配置环境
1.配置JDK
从官网下载相应JDK的版本安装,并进行环境变量的配置
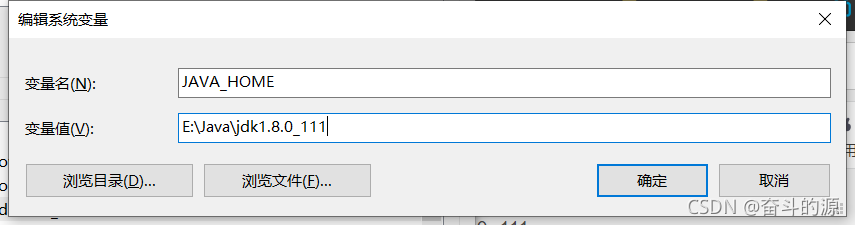
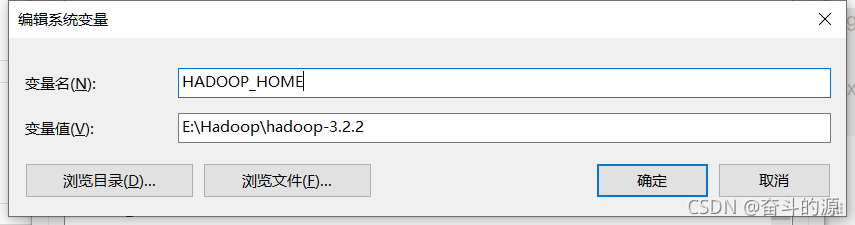
(1)在系统变量新建JAVA_HOME,根据你安装的位置填写变量值
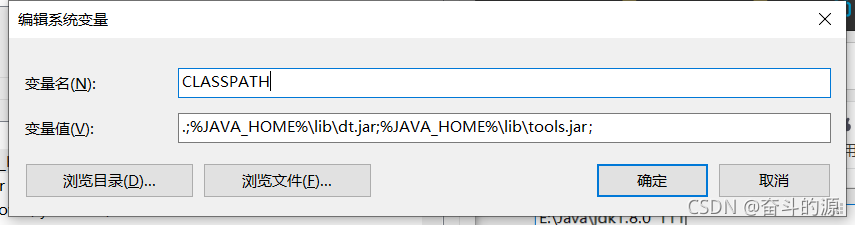
(2)新建CLASSPATH
变量值:.;%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar;(注意前面所需的符号)
(3)点击Path
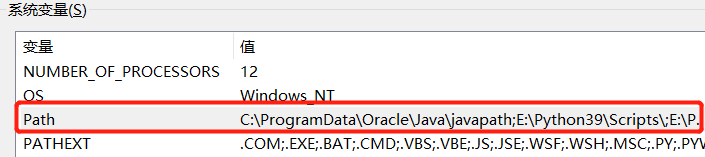
在其中进行新建:%JAVA_HOME%\bin
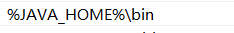
(4)配置好后进行确定
(5)验证,打开cmd,输入java -version和javac进行验证


此上说明jdk环境变量配置成功
2.配置Spark
(1)下载安装:
Spark官网:spark-3.1.2-bin-hadoop3.2下载地址
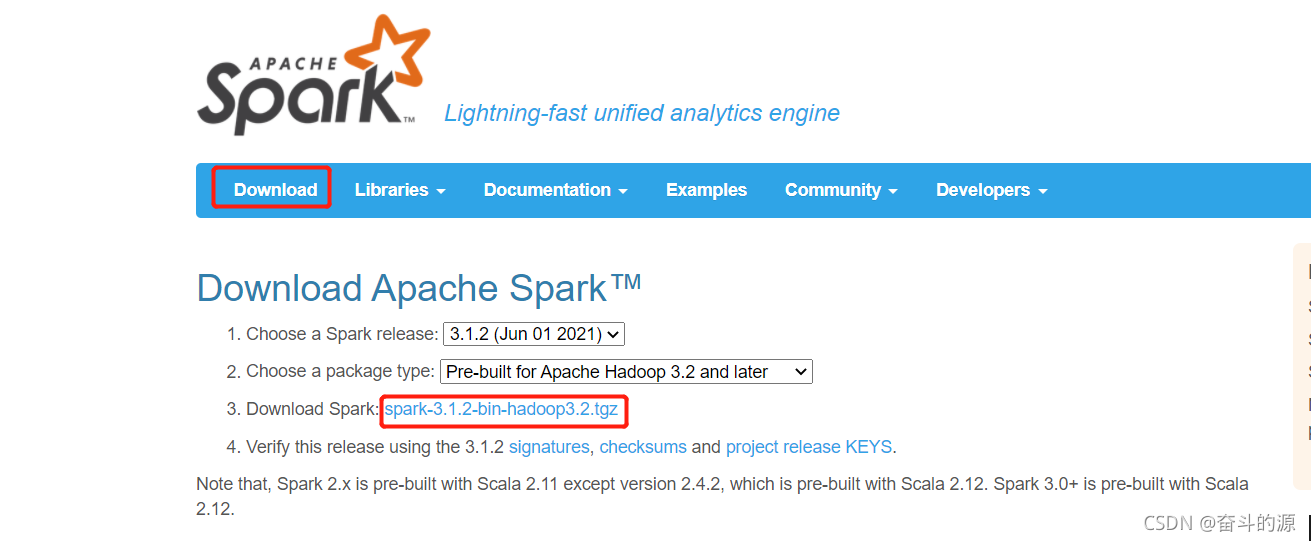
(2)解压,配置环境
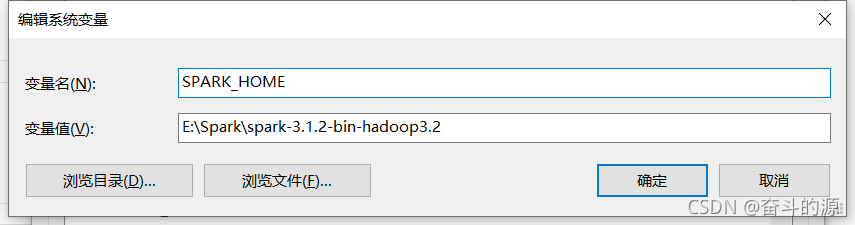
(3)点击Path,进行新建:%SPARK_HOME%\bin,并确认
(4)验证,cmd中输入pyspark
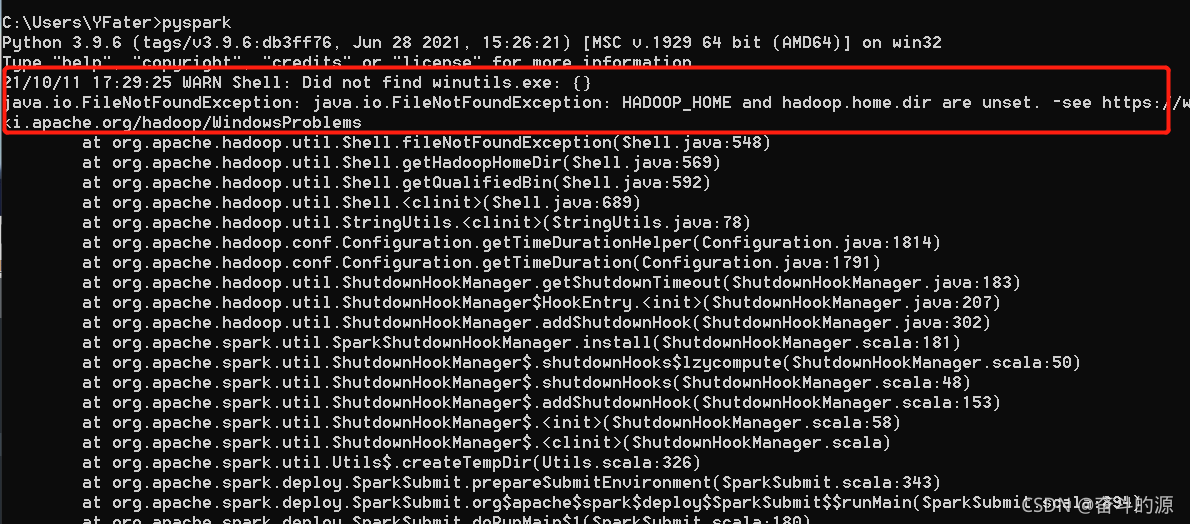
这里提醒我们要安装Hadoop
3.配置Hadoop
(1)下载:
Hadoop官网:Hadoop 3.2.2下载地址
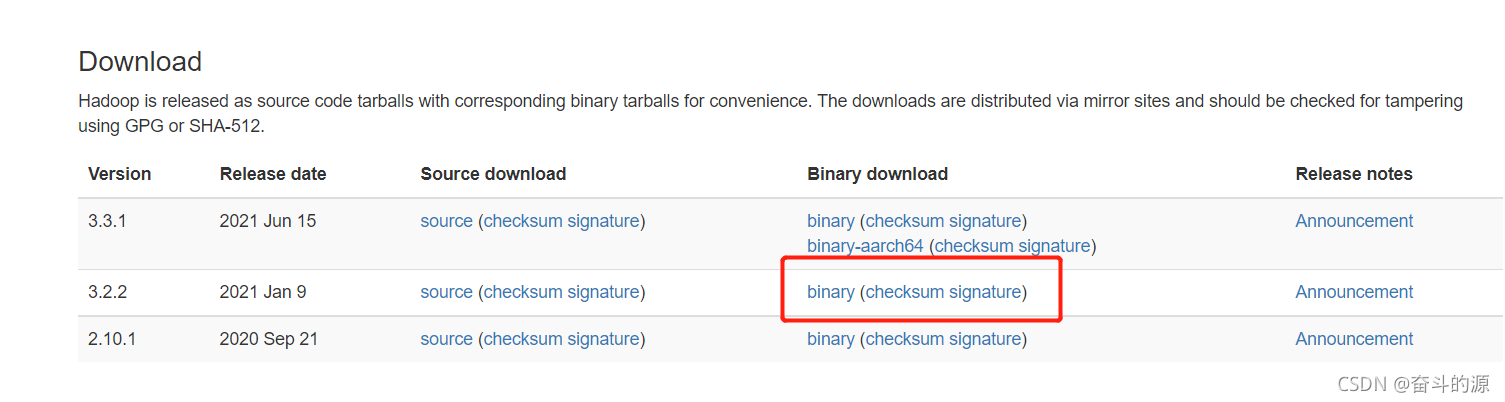
(2)解压,配置环境
注意:解压文件后,bin文件夹中可能没有以下两个文件:

下载地址:https://github.com/cdarlint/winutils
配置环境变量CLASSPATH:%HADOOP_HOME%\bin\winutils.exe
(3)点击Path,进行新建:%HADOOP_HOME%\bin,并确认
(4)验证,cmd中输入pyspark
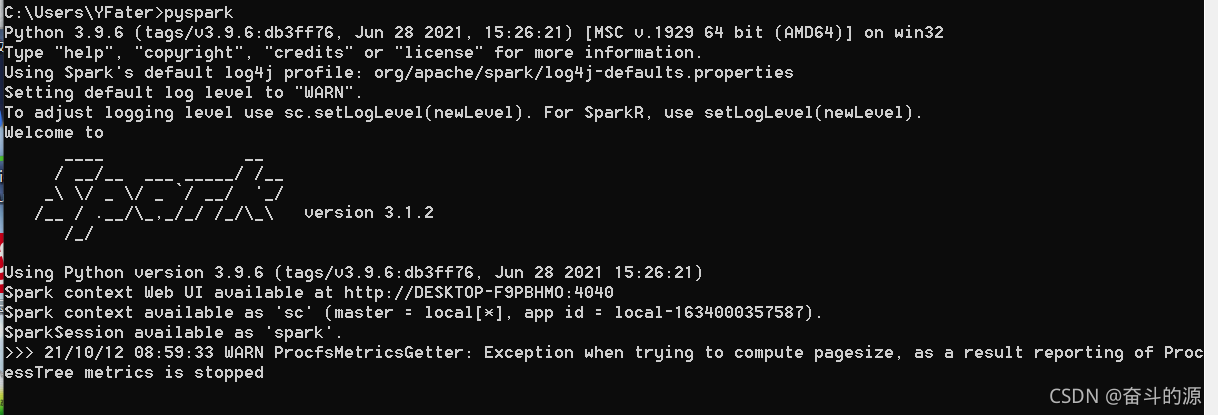
由上可以看出spark能运行成功,但是会出现如下警告:
WARN ProcfsMetricsGetter: Exception when trying to compute pagesize, as a result reporting of ProcessTree metrics is stopped
这里因为spark为3.x版本有相关改动,使用spar2.4.6版本不会出现这样的问题。
不改版本解决方式(因是警告,未尝试):
方式一:解决方法一
方式二:解决方法二
三.Pycharm配置spark
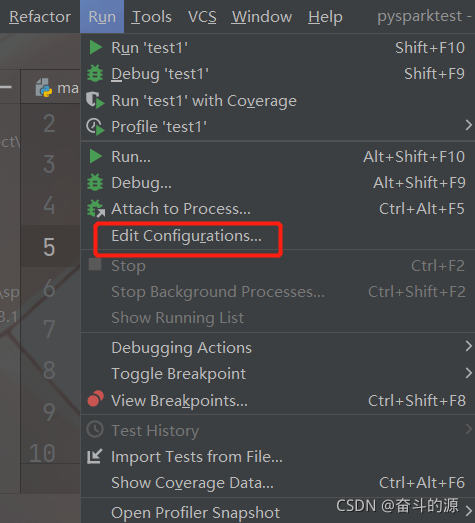
(1)Run–>Edit Configurations
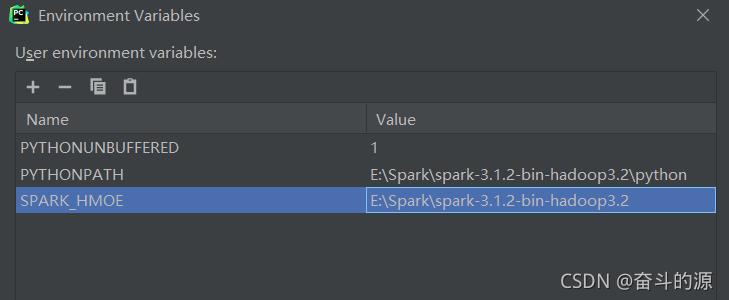
(2)对Environment Variables进行配置
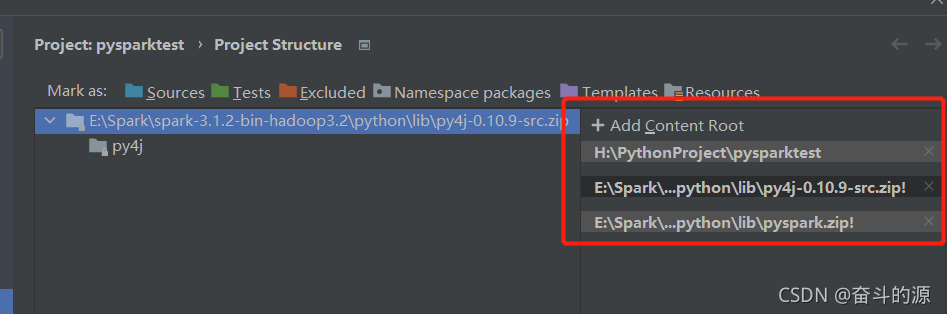
(3)File–>Settings–>Project Structure–>Add Content Root
找到spark-3.1.2-bin-hadoop3.2\python\lib下两个包进行添加
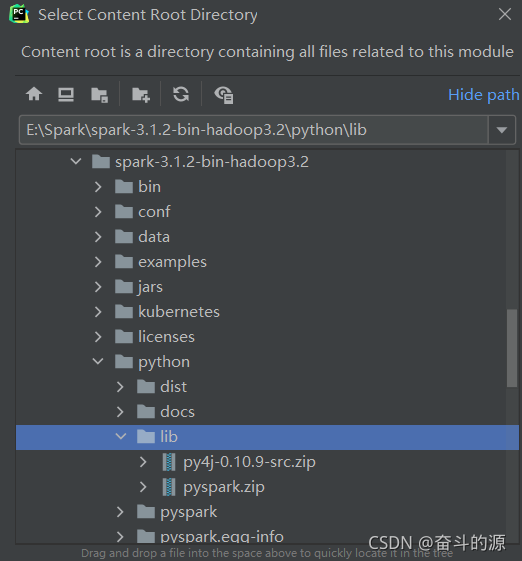
选择结果:
(4)测试
# 添加此代码,进行spark初始化
import findspark
findspark.init()
from datetime import datetime, date
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
rdd = spark.sparkContext.parallelize([
(1, 2., 'string1', date(2000, 1, 1), datetime(2000, 1, 1, 12, 0)),
(2, 3., 'string2', date(2000, 2, 1), datetime(2000, 1, 2, 12, 0)),
(3, 4., 'string3', date(2000, 3, 1), datetime(2000, 1, 3, 12, 0))
])
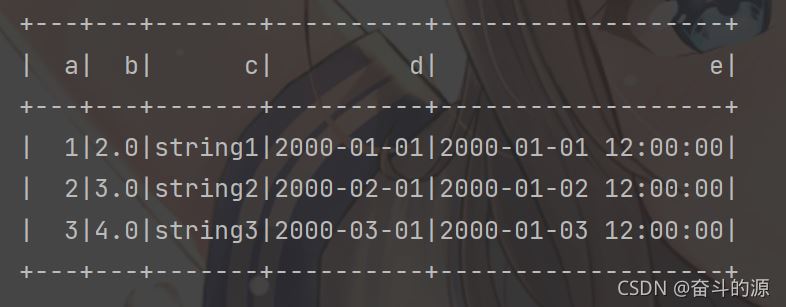
df = spark.createDataFrame(rdd, schema=['a', 'b', 'c', 'd', 'e'])
df.show()
运行结果:
四.使用anconda中python环境配置spark
1.创建虚拟环境
conda create -n pyspark_env python==3.9.6
查看环境:
conda env list
运行结果:

2.安装pyspark
切换到pyspark_env并进行安装pyspark
pip install pyspark

3.环境配置
运行上面的实例,会出现以下错误:

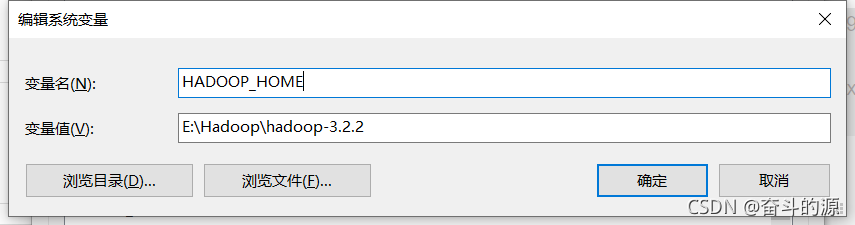
这说明我们需要配置py4j,SPARK_HOME
SPARK_HOME:
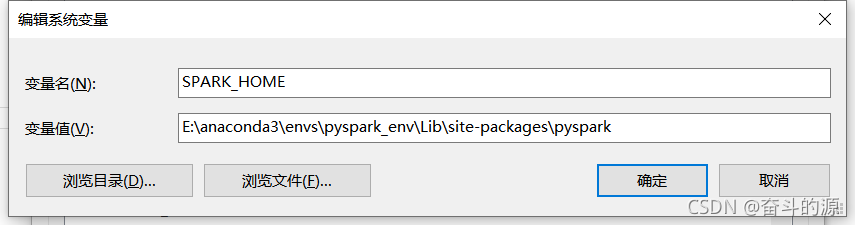
PYTHONPATH设置:
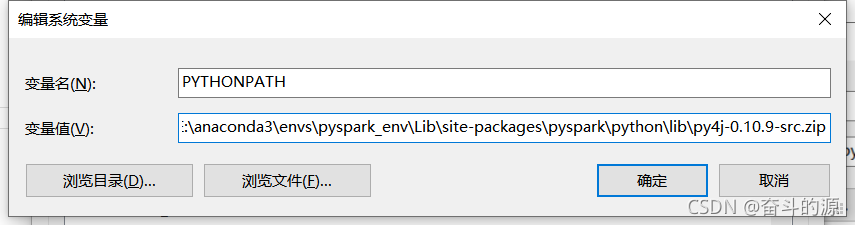
HADOOP_HOME设置:
path中设置:

4.运行

# 添加此代码,进行spark初始化
import findspark
findspark.init()
from datetime import datetime, date
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
rdd = spark.sparkContext.parallelize([
(1, 2., 'string1', date(2000, 1, 1), datetime(2000, 1, 1, 12, 0)),
(2, 3., 'string2', date(2000, 2, 1), datetime(2000, 1, 2, 12, 0)),
(3, 4., 'string3', date(2000, 3, 1), datetime(2000, 1, 3, 12, 0))
])
df = spark.createDataFrame(rdd, schema=['a', 'b', 'c', 'd', 'e'])
df.show()
运行结果同上
到此这篇关于Python安装spark的文章就介绍到这了,更多相关Python安装spark内容请搜索hwidc以前的文章或继续浏览下面的相关文章希望大家以后多多支持hwidc!
【文章原创作者:高防服务器ip】