
Python爬虫实战之批量下载快手平台视频数据
知识点
- requests
- json
- re
- pprint
开发环境:
- 版 本:anaconda5.2.0(python3.6.5)
- 编辑器:pycharm
案例实现步骤:
一. 数据来源分析
(只有当你找到数据来源的时候, 才能通过代码实现)
1.确定需求 (要爬取的内容是什么?)
- 爬取某个关键词对应的视频 保存mp4
2.通过开发者工具进行抓包分析 分析数据从哪里来的(找出真正的数据来源)?
- 静态加载页面
- 笔趣阁为例
- 动态加载页面
- 开发者工具抓数据包
【付费VIP完整版】只要看了就能学会的教程,80集Python基础入门视频教学
点这里即可免费在线观看
二. 代码实现过程
- 找到目标网址
- 发送请求 get post
- 解析数据 (获取视频地址 视频标题)
- 发送请求 请求每个视频地址
- 保存视频
今天的目标
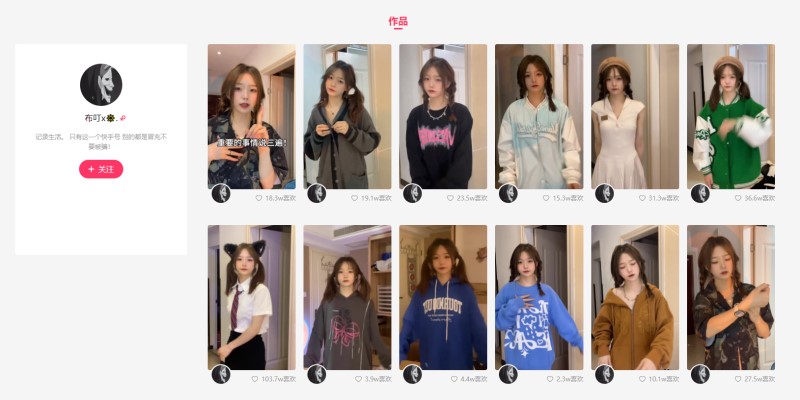

三. 单个视频
导入所需模块
import json import requests import re
发送请求
data = {
'operationName': "visionSearchPhoto",
'query': "query visionSearchPhoto($keyword: String, $pcursor: String, $searchSessionId: String, $page: String, $webPageArea: String) {\n visionSearchPhoto(keyword: $keyword, pcursor: $pcursor, searchSessionId: $searchSessionId, page: $page, webPageArea: $webPageArea) {\n result\n llsid\n webPageArea\n feeds {\n type\n author {\n id\n name\n following\n headerUrl\n headerUrls {\n cdn\n url\n __typename\n }\n __typename\n }\n tags {\n type\n name\n __typename\n }\n photo {\n id\n duration\n caption\n likeCount\n realLikeCount\n coverUrl\n photoUrl\n liked\n timestamp\n expTag\n coverUrls {\n cdn\n url\n __typename\n }\n photoUrls {\n cdn\n url\n __typename\n }\n animatedCoverUrl\n stereoType\n videoRatio\n __typename\n }\n canAddComment\n currentPcursor\n llsid\n status\n __typename\n }\n searchSessionId\n pcursor\n aladdinBanner {\n imgUrl\n link\n __typename\n }\n __typename\n }\n}\n",
'variables': {
'keyword': '张三',
'pcursor': ' ',
'page': "search",
'searchSessionId': "MTRfMjcwOTMyMTQ2XzE2Mjk5ODcyODQ2NTJf5oWi5pGHXzQzMQ"
}
response = requests.post('https://www.kuaishou.com/graphql', data=data)
加请求头
headers = {
# Content-Type(内容类型)的格式有四种(对应data):分别是
# 爬虫基础/xml: 把xml作为一个文件来传输
# multipart/form-data: 用于文件上传
'content-type': 'application/json',
# 用户身份标识
'Cookie': 'kpf=PC_WEB; kpn=KUAISHOU_VISION; clientid=3; did=web_721a784b472981d650bcb8bbc5e9c9c2',
# 浏览器信息 (伪装成浏览器发送请求)
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
}
json序列化操作
# json数据交换格式, 在JSON出现之前, 大家一直用XML来传递数据
# 由于各个语言都支持 JSON ,JSON 又支持各种数据类型,所以JSON常用于我们日常的 HTTP 交互、数据存储等。
# 将python对象编码成Json字符串
data = json.dumps(data)
json_data = requests.post('https://www.kuaishou.com/graphql', headers=headers, data=data).json()
字典取值
feeds = json_data['data']['visionSearchPhoto']['feeds']
for feed in feeds:
caption = feed['photo']['caption']
photoUrl = feed['photo']['photoUrl']
new_title = re.sub(r'[/\:*?<>/\n] ', '-', caption)
再次发送请求
resp = requests.get(photoUrl).content
保存数据
with open('video\\' + title + '.mp4', mode='wb') as f:
f.write(resp)
print(title, '爬取成功!!!')
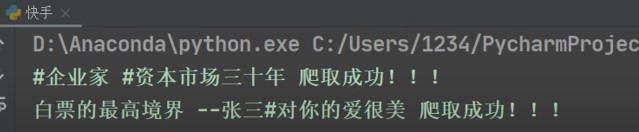
四. 翻页爬取
导入模块
import concurrent.futures import time
发送请求
def get_json(url, data):
response = requests.post(url, headers=headers, data=data).json()
return response
修改标题
def change_title(title):
# windows系统文件命名 不能含有特殊字符...
# windows文件命名 字符串不能超过 256...
new_title = re.sub(r'[/\\|:?<>"*\n]', '_', title)
if len(new_title) > 50:
new_title = new_title[:10]
return new_title
数据提取
def parse(json_data):
data_list = json_data['data']['visionSearchPhoto']['feeds']
info_list = []
for data in data_list:
# 提取标题
title = data['photo']['caption']
new_title = change_title(title)
url_1 = data['photo']['photoUrl']
info_list.append([new_title, url_1])
return info_list
保存数据
def save(title, url_1):
resp = requests.get(url_1).content
with open('video\\' + title + '.mp4', mode='wb') as f:
f.write(resp)
print(title, '爬取成功!!!')
主函数 调动所有的函数
def run(url, data):
"""主函数 调动所有的函数"""
json_data = get_json(url, data)
info_list = parse(json_data)
for title, url_1 in info_list:
save(title, url_1)
if __name__ == '__main__':
start_time = time.time()
with concurrent.futures.ThreadPoolExecutor(max_workers=10) as executor:
for page in range(1, 5):
url = 'https://www.kuaishou.com/graphql'
data = {
'operationName': "visionSearchPhoto",
'query': "query visionSearchPhoto($keyword: String, $pcursor: String, $searchSessionId: String, $page: String, $webPageArea: String) {\n visionSearchPhoto(keyword: $keyword, pcursor: $pcursor, searchSessionId: $searchSessionId, page: $page, webPageArea: $webPageArea) {\n result\n llsid\n webPageArea\n feeds {\n type\n author {\n id\n name\n following\n headerUrl\n headerUrls {\n cdn\n url\n __typename\n }\n __typename\n }\n tags {\n type\n name\n __typename\n }\n photo {\n id\n duration\n caption\n likeCount\n realLikeCount\n coverUrl\n photoUrl\n liked\n timestamp\n expTag\n coverUrls {\n cdn\n url\n __typename\n }\n photoUrls {\n cdn\n url\n __typename\n }\n animatedCoverUrl\n stereoType\n videoRatio\n __typename\n }\n canAddComment\n currentPcursor\n llsid\n status\n __typename\n }\n searchSessionId\n pcursor\n aladdinBanner {\n imgUrl\n link\n __typename\n }\n __typename\n }\n}\n",
'variables': {
'keyword': '曹芬',
# 'keyword': keyword,
'pcursor': str(page),
'page': "search",
'searchSessionId': "MTRfMjcwOTMyMTQ2XzE2Mjk5ODcyODQ2NTJf5oWi5pGHXzQzMQ"
}
}
data = json.dumps(data)
executor.submit(run, url, data, )
print('一共花费了:', time.time()-start_time)
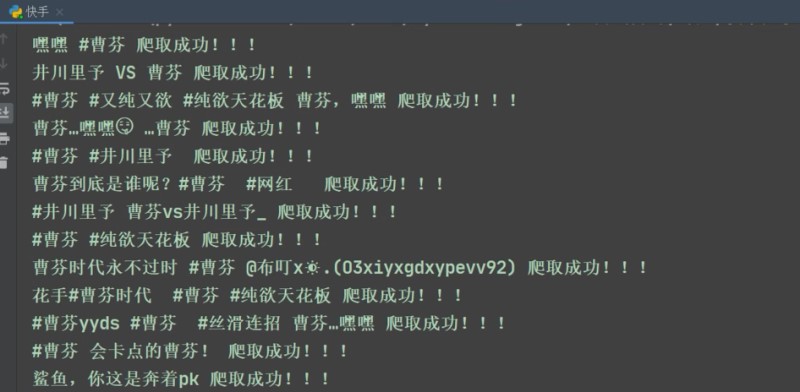

耗时为57.7秒
到此这篇关于Python爬虫实战之批量下载快手平台视频数据的文章就介绍到这了,更多相关Python 批量下载快手视频内容请搜索hwidc以前的文章或继续浏览下面的相关文章希望大家以后多多支持hwidc!
【本文出处:国外高防服务器 复制请保留原URL】